序列数据:时间学列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。
基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。

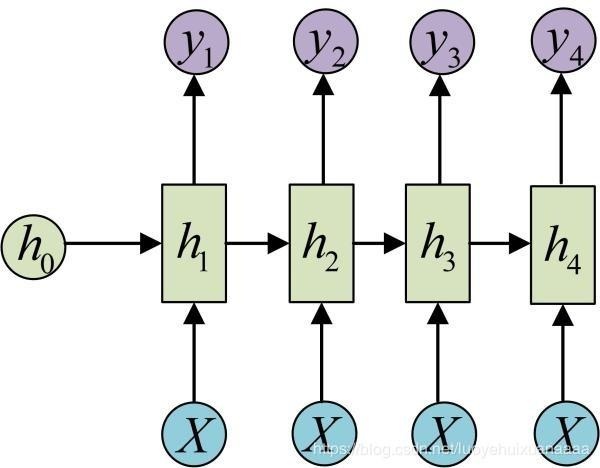
上图是一个标准的RNN结构图,图中每个箭头代表做一次变换,也就是说箭头连接带有权值。左侧是折叠起来的样子,右侧是展开的样子,左侧中h旁边的箭头代表此结构中的“循环”体现在隐层。
RNN还有以下特点:
1 权值共享,图中W全相同,U和V也一样
2 每一个输入值都只与它本身的那条路线建立权连接,不会和别的神经元连接
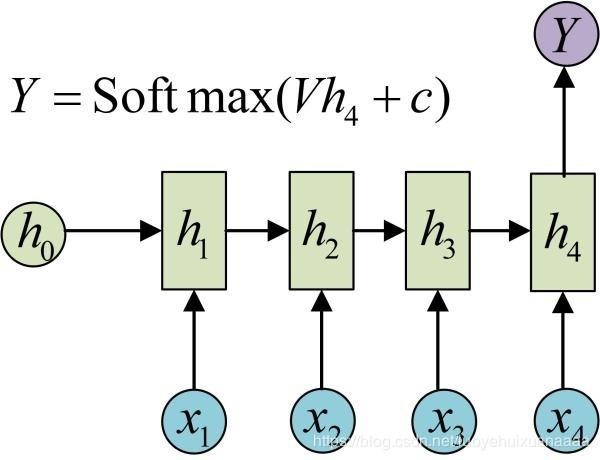
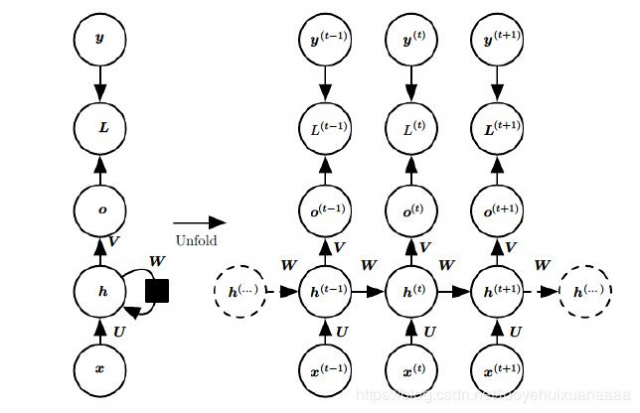
x是输入,h是隐层单元,o为输出,L为损失函数,y为训练集的标签。这些元素右上角带的t代表t时刻的状态,单元h在t时刻的表现不仅由此刻的输入决定,还受t时刻之前时刻的影响。V、W、U是权值,同一类型的权连接权值相同。有了上面的理解,前向传播算法其实非常简单,对于t时刻:


BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质梯度下降法,那么求各个参数的梯度便成了此算法的核心。

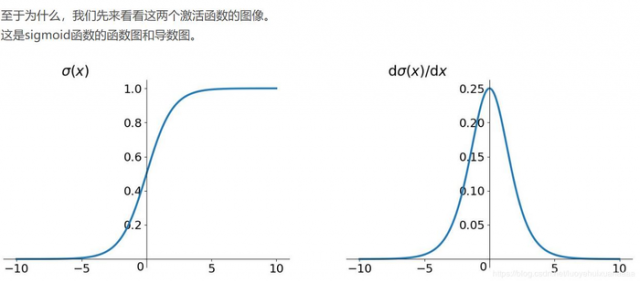
你可能会提出异议,RNN明明与深层神经网络不同,RNN的参数都是共享的,而且某时刻的梯度是此时刻和之前时刻的累加,即使传不到最深处,那浅层也是有梯度的。这当然是对的,但如果我们根据有限层的梯度来更新更多层的共享的参数一定会出现问题。
梯度消失或梯度爆炸
在间隔不断增大时,RNN会丧失学习到连接如此远的信息的能力,存在长期依赖问题
所有RNN都具有一种重复神经网络模块的链式形式。在标准RNN种,这个重复的模块只有一个非常简单的结构,例如有一个tanh层。
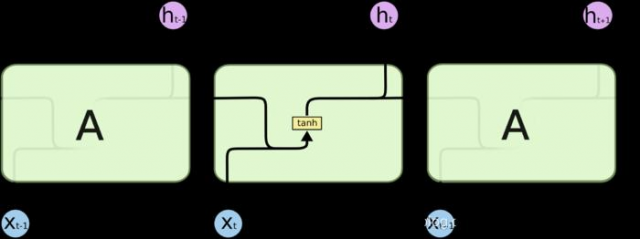
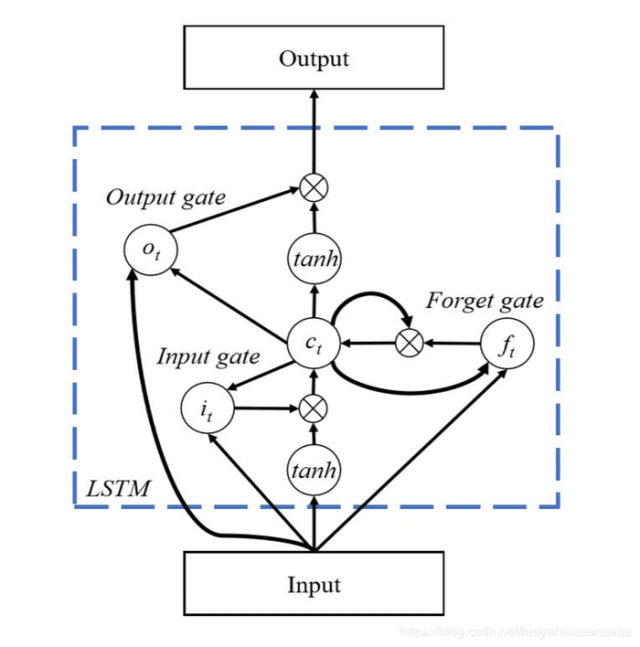
LSTM同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,整体上除了h在随时间流动,细胞状态c也在随时间流动,细胞状态c就代表着长期记忆。
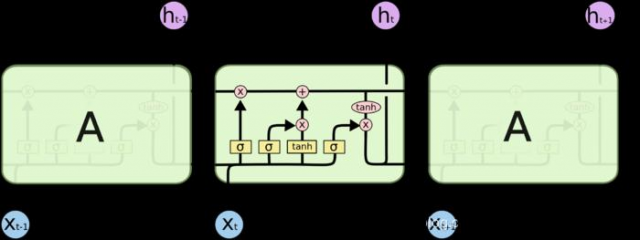
LSTM的关键就是细胞状态,水平线在图上方贯穿运行。
细胞状态,类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
LSTM有通过精心设计的被称为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个sigmoid神经网络层和一个pointwise乘法操作。
LSTM拥有三个门:遗忘门、输入门、输出门,来保护和控制细胞状态
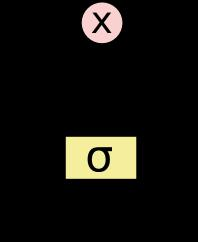
1 遗忘门
LSTM 中第一步决定从细胞状态中丢弃什么信息。通过一个遗忘门。该门会读取ht−1和xt,输出一个在 0 到 1 之间的数值给每个在细胞状态Ct−1Ct−1 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
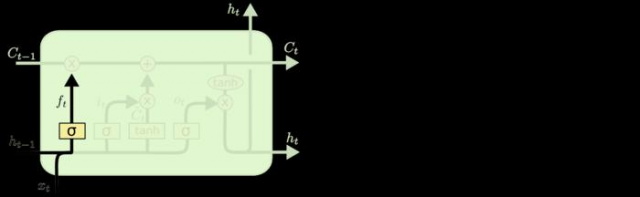
决定记住上面,遗忘上面,其中新的输入肯定要产生影响。
2 输入门
这一步决定什么样的信息被存放在细胞状态中。
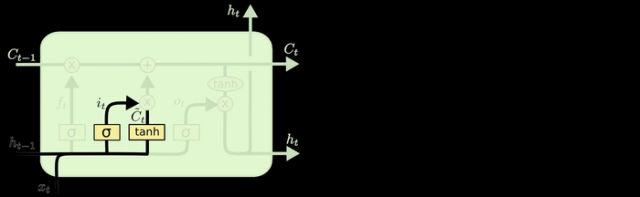
现在是更新旧细胞状态的时间了,Ct−1更新为 Ct
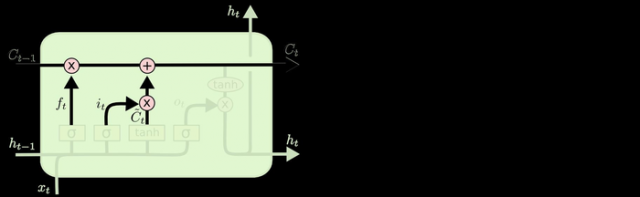
3 输出门
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。
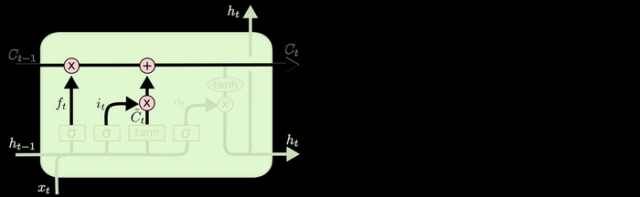
这三个门虽然功能上不同,但在执行任务的操作上是相同的。
它将忘记们和输入门合成了一个单一的更新门,同时还混合了细胞状态和隐藏状态。最终的模型比标准的LSTM模型要简单,也是非常流行的变体。
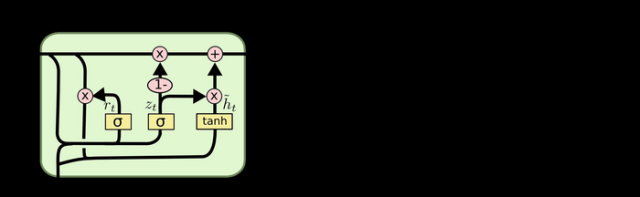
GRU是LSTM网络的一种效果更好的变体,它较LSTM网络结构的变体更加简单,而且效果也很好,它也是可以解决RNN网络中的长期依赖问题。
GRU模型中只有两个门:分别是更新门和重置门。图中的zt和rt分别表示更新门和重置门。
更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 h~t 上,重置门越小,前一状态的信息被写入的越少。
概括来说,LSTM和GRU都是通过各种门函数来将重要特征保留下来,这样就保证了在long-term传播的时候也不会丢失。此外,GRU相对于LSTM少了一个门函数,因此在参数的数量上也是要少于LSTM的,所以整体上GRU的训练速度要快于LSTM的。不过对于两个网络的好坏还得看具体的应用场景。
本文链接:http://task.lmcjl.com/news/12452.html


