图像识别和自然语言处理是目前应用极为广泛的AI技术,这些技术不管是速度还是准确度都已经达到了相当的高度,具体应用例如智能手机的人脸解锁、内置的语音助手。这些技术的实现和发展都离不开神经网络,可是传统的神经网络只能解决关于辨识的问题,并不能够为机器带来自主创造的能力,例如让机器写出一篇流畅的新闻报道,生成一副美丽的风景画。但随着GAN的出现,这些都成为了可能。
生成式对抗网络(GAN, Generative Adversarial Networks)是一种近年来大热的深度学习模型,该模型由两个基础神经网络即生成器神经网络(Generator Neural Network)和判别器神经网络(Discriminator Neural Network)所组成,其中一个用于生成内容,另一个则用于判别生成的内容。
GAN受博弈论中的零和博弈启发,将生成问题视作判别器和生成器这两个网络的对抗和博弈:生成器从给定噪声中(一般是指均匀分布或者正态分布)产生合成数据,判别器分辨生成器的的输出和真实数据。前者试图产生更接近真实的数据,相应地,后者试图更完美地分辨真实数据与生成数据。由此,两个网络在对抗中进步,在进步后继续对抗,由生成式网络得的数据也就越来越完美,逼近真实数据,从而可以生成想要得到的数据(图片、序列、视频等)。
GAN最早是由Ian J. Goodfellow等人于2014年10月提出的,他的《Generative Adversarial Nets》可以说是这个领域的开山之作,论文一经发表,就引起了热议。而随着GAN在理论与模型上的高速发展,它在计算机视觉、自然语言处理、人机交互等领域有着越来越深入的应用,并不断向着其它领域继续延伸。
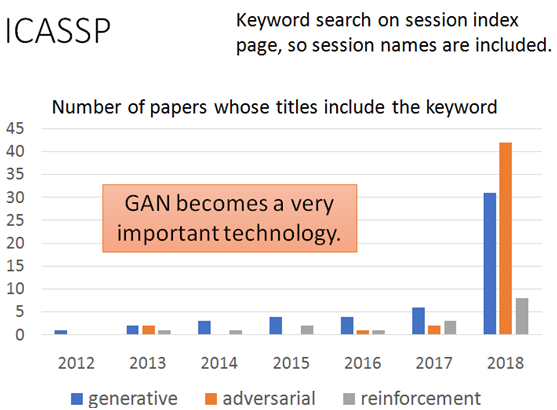
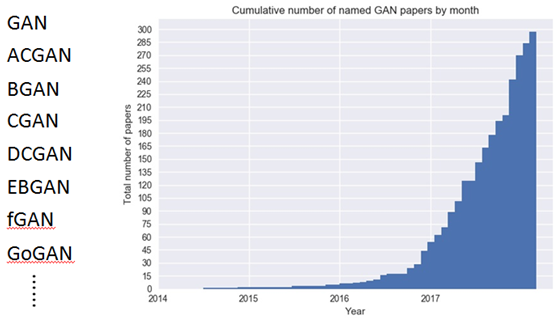
从上面的两份数据中可以看出不管是在ICASSP上发表的涉及到GAN的论文还是GAN的升级版模型,数量都获得了极大的增长,尤其是2017年至今。包含关键词:生成式(generative)的论文从6篇增加到31篇;对抗(Adversarial)的论文更是从2篇增加到42篇,而GAN的变种模型从2017年初的50多个增加到现在的近300个。
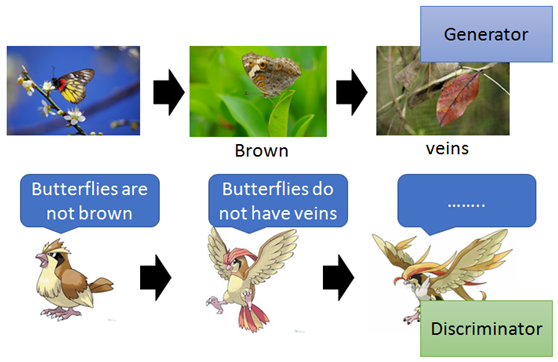
图中的枯叶蝶扮演Generator的角色,相应的其天敌之一的麻雀扮演Discriminator的角色。起初,枯叶蝶的翅膀与其他的蝴蝶别无二致,都是色彩斑斓;
如此不断的进行下去,伴随着枯叶蝶的不断进化和麻雀判别标准的不断升级,二者不断地相互博弈,最终导致的结果就是枯叶蝶的翅膀(输出)无限接近于真实的枯叶(真实物体)。
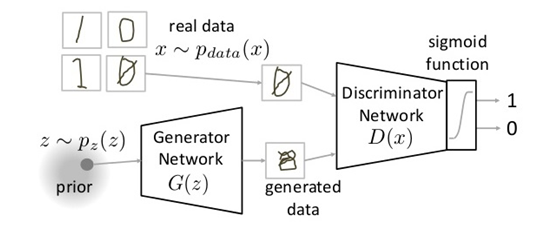
上图中的标记符号:
其他符号前文中已作解释。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
用公式表示如下:
[min_{G} max_{D}V(D,G) = E_{x sim p_{data}(x)}[log D(x)]+E_{z sim p_{z}(z)}[log (1-D(G(z)))]
]
整个式子由两项构成。X表示真实图片,Z表示输入G网络的噪声,而G(z)表示G网络生成的图片。D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是(min_G)。
D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)。
这个过程被下面这张图很好的描述了出来:
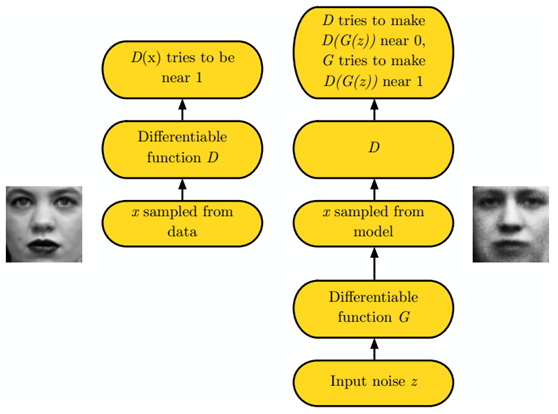
最终通过不断的训练,生成的图片会相当真实。
GAN最直接的应用在于数据的生成,也就是通过GAN的建模能力生成图像、语音、文字、视频等等。目前,GAN最成功的应用领域主要是计算机视觉,包括图像、视频的生成,如图像翻译、图像上色、图像修复、视频生成等。此外GAN在自然语言处理,人机交互领域也略有拓展和应用。
如下图所示,只需输入鸟类和花朵的关键特征,GAN,就能为我们输出对应的花鸟的图片。(论文地址:https://arxiv.org/abs/1605.05396)

图中,可以将黑白图像转换为彩色图像、将航拍图像变成地图形式、将白天的照片转换为黑夜的照片、甚至可以根据物体的轮廓、边缘信息,来生成实体包包的形式。(论文地址:https://arxiv.org/abs/1611.07004)

GAN还可以增加图像分辨率:从较低分辨率照片生成高分辨率照片。(论文地址:https://arxiv.org/abs/1609.04802)
GAN还可以应用于视频预测,即生成器根据前面一系列帧生成视频最后一帧。(论文地址:https://arxiv.org/abs/1511.06380)
动图中左右两边的奥巴马讲话的镜头,你能第一眼就看出来哪边是合成的吗?
Vondrick等人在视频领域取得了巨大进展,他们能生成32帧分辨率为64×64 的逼真视频,描绘的内容包括高尔夫球场、沙滩、火车站以及新生儿。(论文地址:https://arxiv.org/abs/1609.02612)

Santana等人实现了利用GAN 的辅助自动驾驶。首先,生成与真实交通场景图像分布一致的图像,然后,训练一个基于循环神经网络的转移模型来预测下一个交通场景。
另外,GAN还可以用于对抗神经机器翻译,将神经机器翻译(neural machine translation, NMT)作为GAN 的生成器,采用策略梯度方法训练判别器,通过最小化人类翻译和神经机器翻译的差别生成高质量的翻译。
虽然目前GAN还只是集中应用于图像和视频领域,但是相信它将来也必然会在其他领域大放异彩。
Ian在2014年提出的朴素GAN在生成器和判别器在结构上是通过以多层全连接网络为主体的多层感知机(Multi-layer Perceptron, MLP) 实现的,然而其调参难度较大,训练失败相当常见,生成图片质量也相当不佳,尤其是对较复杂的数据集而言。
由于卷积神经网络(Convolutional neural network, CNN)比MLP有更强的拟合与表达能力,并在判别式模型中取得了很大的成果。因此,Alec等人将CNN引入生成器和判别器,称作深度卷积对抗神经网络(Deep Convolutional GAN, DCGAN)。DCGAN的原理和GAN是一样的,它只是把上述的G和D换成了两个卷积神经网络(CNN)。但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
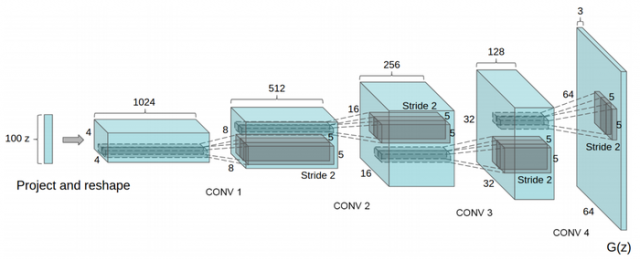
DCGAN虽然没有带来理论上以及GAN上的解释性,但是其强大的图片生成效果吸引了更多的研究者关注GAN,证明了其可行性并提供了经验,给后来的研究者提供了神经网络结构的参考。此外,DCGAN的网络结构也可以作为基础架构,用以评价不同目标函数的GAN,让不同的GAN得以进行优劣比较。DCGAN的出现极大增强了GAN的数据生成质量。而如何提高生成数据的质量(如生成图片的质量)也是如今GAN研究的热门话题。

这效果已经可以和专业的画师比一比了。
与前文的DCGAN不同,WGAN(Wasserstein GAN)并不是从判别器与生成器的网络构架上去进行改进,而是从目标函数的角度出发来提高模型的表现。Martin Arjovsky等人先阐述了朴素GAN因生成器梯度消失而训练失败的原因:他们认为,朴素GAN的目标函数在本质上可以等价于优化真实分布与生成分布的Jensen-Shannon散度。而根据Jensen-Shannon散度的特性,当两个分布间互不重叠时,其值会趋向于一个常数,这也就是梯度消失的原因。此外,Martin Arjovsky等人认为,当真实分布与生成分布是高维空间上的低维流形时,两者重叠部分的测度为0的概率为1,这也就是朴素GAN调参困难且训练容易失败的原因之一。
针对这种现象,Martin Arjovsky等人利用Wasserstein-1距离(又称Earth Mover距离)来替代朴素GAN所代表的Jensen-Shannon散度。Wasserstein距离是从最优运输理论中的Kantorovich问题衍生而来的,可以如下定义真实分布与生成分布的Wasserstein-1距离:
[W(P_{r},P_{g}) = inf_{gamma in prod(P_{r},P_{g})} E_{(x,y)simgamma}[parallel x-y parallel]
]
其中 (p_{r},p_{g}) 分别为真实分布与生成分布,$gamma $ 为$ p_{r},p_{g}$ 分的联合分布。相较于Jensen-Shannon散度,Wasserstein-1距离的优点在于,即使 (p_{r},p_{g}) 互不重叠,Wasserstein距离依旧可以清楚地反应出两个分布的距离。为了与GAN相结合,将其转换成对偶形式:
[W(P_{r},P_{theta}) = sup_{parallel f parallel_{L}leq1}E_{xsim P_{r}}[f(x)]-E_{x sim P_{theta}}[f(x)]
]
从表示GAN的角度理解,fw表示判别器,与之前的D不同的是,WGAN不再需要将判别器当作0-1分类将其值限定在[0,1]之间,fw越大,表示其越接近真实分布;反之,就越接近生成分布。此外,$ ||f||_{L} ≤ 1 $ 表示其Lipschitz常数为1。显然,Lipschitz连续在判别器上是难以约束的,为了更好地表达Lipschitz转化成权重剪枝,即要求参数w ∈ [−c, c],其中为常数。因而判别器的目标函数为:
[max_{f_{w}}E_{xsim P_{r}}[f_{w}(x)]-E_{zsim p_{z}}[f_{w}(G(z))]
]
其中w ∈ [−c, c],生成器的损失函数为:
[min_{G}-E_{zsim P_{z}}[f_{w}(G(z))]
]
WGAN的贡献在于,从理论上阐述了因生成器梯度消失而导致训练不稳定的原因,并用Wasserstein距离替代了Jensen-Shannon散度,在理论上解决了梯度消失问题。此外,WGAN还从理论上给出了朴素GAN发生模式坍塌(mode collapse)的原因,并从实验角度说明了WGAN在这一点上的优越性。最后,针对生成分布与真实分布的距离和相关理论以及从Wasserstein距离推导而出的Lipschitz约束,也给了后来者更深层次的启发,如基于Lipschitz密度的 损失敏感GAN(loss sensitive GAN, LS-GAN)。
虽然WGAN在理论上解决了训练困难的问题,但它也有各种各样的缺点。在理论上,由于对函数(即判别器)存在Lipschitz-1约束,这个条件难以在神经网络模型中直接体现,所以作者使用了权重剪枝(clip) 来近似替代Lipschitz-1约束。显然在理论上,这两个条件并不等价,而且满足Lipschitz-1约束的情况多数不满足权重剪枝约束。而在实验上,很多人认为训练失败是由权重剪枝引起的。对此Ishaan Gulrajani提出了梯度带梯度惩罚的WGAN(WGAN with gradient penalty, WGAN-GP),将Lipschitz-1约束正则化,通过把约束写成目标函数的惩罚项,以近似Lipschitz-1约束条件。
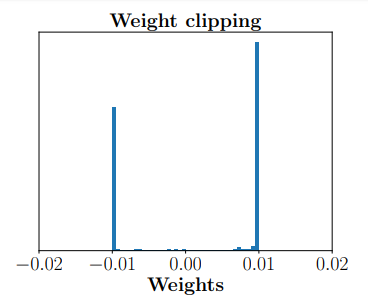
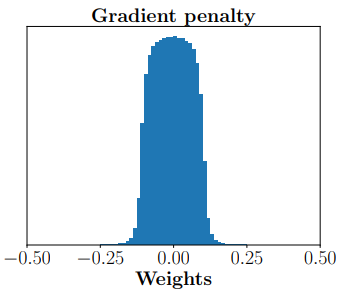
上图为WGAN与WGAN-GP的权重分布情况
因而,WGAN的目标函数可以写作:
[max_{f}E_{xsim P_{r}}[f(x)]-E_{widetilde{x} sim P_{g}}[f(widetilde{x})]+lambda E_{hat{x}sim P_{hat{x}}}[(parallel nabla_{hat{x}}f(hat{x})parallel_{2}-1)^2]
]
其中(p_{bar{x}}) 是 (p_{r})与(p_{g})之间的线性采样,即满足:
[hat x = varepsilon x+(1-varepsilon)hat x, varepsilonsim uniform(0,1)
]
此外,生成器的目标函数与WGAN相同,取第二项进行优化即可。
WGAN-GP的贡献在于,它用正则化的形式表达了对判别器的约束,也为后来GAN的正则化模型做了启示。此外WGAN-GP基本从理论和实验上解决了梯度消失的问题,并且具有强大的稳定性,几乎不需要调参,即在大多数网络框架下训练成功率极高。
虽然WGAN和WGAN-GP已经基本解决了训练失败的问题,但是无论是训练过程还是是收敛速度都要比常规 GAN 更慢。受WGAN理论的启发,Mao 等人提出了最小二乘GAN (least square GAN, LSGAN)。LSGAN的一个出发点是提高图片质量。它的主要想法是为判别器D提供平滑且非饱和梯度的损失函数。这里的非饱和梯度针对的是朴素GAN的对数损失函数。显然,x越大,对数损失函数越平滑,即梯度越小,这就导致对判别为真实数据的生成数据几乎不会有任何提高。针对于此,LSGAN的判别器目标函数如下:
[min_D E_{x sim P_{data(x)}}[(D(x)-b)^2]+E_{zsim P_z(z)}[(D(G(z))-a)^2]
]
生成器的目标函数如下:
[E_{zsim P_{z}(z)}[(D(G(z))-c)^2]
]
这里(a, b, c)满足(b − c = 1)和(b − a = 2)。它等价于f散度中的散度 (x^{2}) ,也即是说,LSGAN用散度(x^{2})取代了朴素GAN的Jensen-Shannon散度。
最后,LSGAN的优越性在于,它缓解了GAN训练时的不稳定,提高了生成数据的质量和多样性,也为后面的泛化模型f-GAN提供了思路。
(待更新。。。)
1.一文看懂生成式对抗网络GANs:介绍指南及前景展望(http://36kr.com/p/5086889.html)
2.the-gan-zoo(https://github.com/hindupuravinash/the-gan-zoo)
3.台湾大学李宏毅:Generative Adversarial Network (GAN):Introduction(http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2018/Lecture/GAN%20(v2).pptx)
4.Generative Adversarial Networks(https://arxiv.org/abs/1406.2661)
5.GAN学习指南:从原理入门到制作生成Demo(https://zhuanlan.zhihu.com/p/24767059)
6.Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks(https://arxiv.org/abs/1511.06434)
7.DCGAN-tensorflow(https://github.com/carpedm20/DCGAN-tensorflow)
8.AI可能真的要代替插画师了……(https://zhuanlan.zhihu.com/p/28488946)
本文链接:http://task.lmcjl.com/news/12469.html


