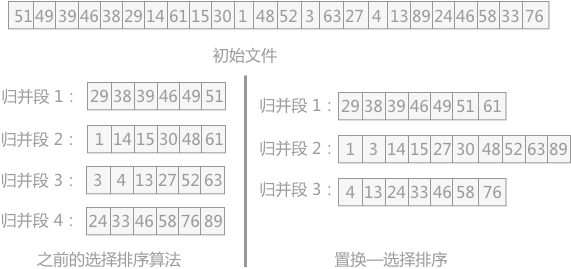
图 1 选择排序算法的比较




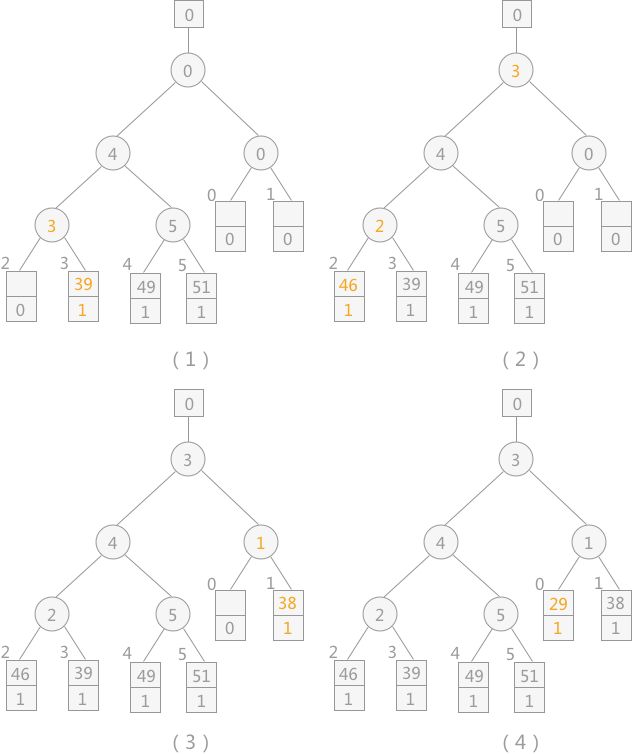
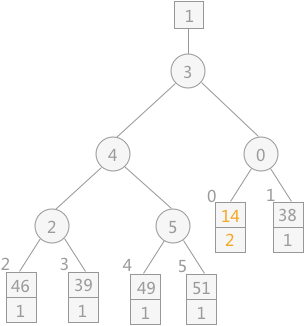
注意:当读入新的记录时,如果其值比 MINIMAX 大,其序号则仍为 1;反之则为 2 ,比较时序号 1 比序号 2的记录大。
#include <stdio.h>
#define MAXKEY 10000
#define RUNEND_SYMBOL 10000 // 归并段结束标志
#define w 6 // 内存工作区可容纳的记录个数
#define N 24 // 设文件中含有的记录的数量
typedef int KeyType; // 定义关键字类型为整型
// 记录类型
typedef struct{
KeyType key; // 关键字项
}RedType;
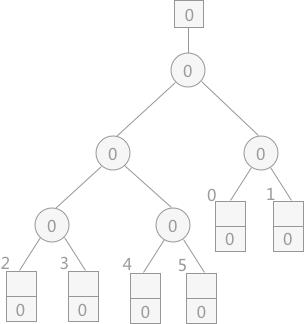
typedef int LoserTree[w];// 败者树是完全二叉树且不含叶子,可采用顺序存储结构
typedef struct
{
RedType rec; /* 记录 */
KeyType key; /* 从记录中抽取的关键字 */
int rnum; /* 所属归并段的段号 */
}RedNode, WorkArea[w];
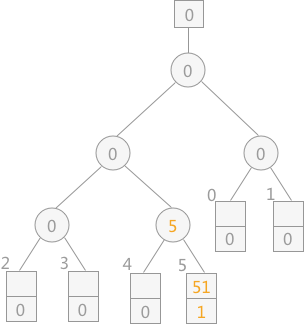
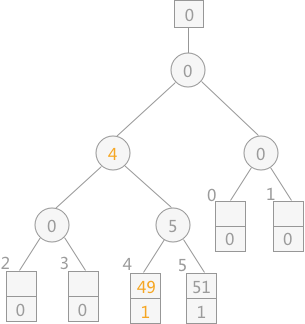
// 从wa[q]起到败者树的根比较选择MINIMAX记录,并由q指示它所在的归并段
void Select_MiniMax(LoserTree ls,WorkArea wa,int q){
int p, s, t;
// ls[t]为q的双亲节点,p作为中介
for(t = (w+q)/2,p = ls[t]; t > 0;t = t/2,p = ls[t]){
// 段号小者 或者 段号相等且关键字更小的为胜者
if(wa[p].rnum < wa[q].rnum || (wa[p].rnum == wa[q].rnum && wa[p].key < wa[q].key)){
s=q;
q=ls[t]; //q指示新的胜利者
ls[t]=s;
}
}
ls[0] = q; // 最后的冠军
}
//输入w个记录到内存工作区wa,建得败者树ls,选出关键字最小的记录,并由s指示其在wa中的位置。
void Construct_Loser(LoserTree ls, WorkArea wa, FILE *fi){
int i;
for(i = 0; i < w; ++i){
wa[i].rnum = wa[i].key = ls[i] = 0;
}
for(i = w - 1; i >= 0; --i){
fread(&wa[i].rec, sizeof(RedType), 1, fi);// 输入一个记录
wa[i].key = wa[i].rec.key; // 提取关键字
wa[i].rnum = 1; // 其段号为"1"
Select_MiniMax(ls,wa,i); // 调整败者树
}
}
// 求得一个初始归并段,fi为输入文件指针,fo为输出文件指针。
void get_run(LoserTree ls,WorkArea wa,int rc,int *rmax,FILE *fi,FILE *fo){
int q;
KeyType minimax;
// 选得的MINIMAX记录属当前段时
while(wa[ls[0]].rnum == rc){
q = ls[0];// q指示MINIMAX记录在wa中的位置
minimax = wa[q].key;
// 将刚选得的MINIMAX记录写入输出文件
fwrite(&wa[q].rec, sizeof(RedType), 1, fo);
// 如果输入文件结束,则虚设一条记录(属"rmax+1"段)
if(feof(fi)){
wa[q].rnum = *rmax+1;
wa[q].key = MAXKEY;
}else{ // 输入文件非空时
// 从输入文件读入下一记录
fread(&wa[q].rec,sizeof(RedType),1,fi);
wa[q].key = wa[q].rec.key;// 提取关键字
if(wa[q].key < minimax){
// 新读入的记录比上一轮的最小关键字还小,则它属下一段
*rmax = rc+1;
wa[q].rnum = *rmax;
}else{
// 新读入的记录大则属当前段
wa[q].rnum = rc;
}
}
// 选择新的MINIMAX记录
Select_MiniMax(ls, wa, q);
}
}
//在败者树ls和内存工作区wa上用置换-选择排序求初始归并段
void Replace_Selection(LoserTree ls, WorkArea wa, FILE *fi, FILE *fo){
int rc, rmax;
RedType j;
j.key = RUNEND_SYMBOL;
// 初建败者树
Construct_Loser(ls, wa, fi);
rc = rmax =1;//rc指示当前生成的初始归并段的段号,rmax指示wa中关键字所属初始归并段的最大段号
while(rc <= rmax){// "rc=rmax+1"标志输入文件的置换-选择排序已完成
// 求得一个初始归并段
get_run(ls, wa, rc, &rmax, fi, fo);
fwrite(&j,sizeof(RedType),1,fo);//将段结束标志写入输出文件
rc = wa[ls[0]].rnum;//设置下一段的段号
}
}
void print(RedType t){
printf("%d ",t.key);
}
int main(){
RedType a[N]={51,49,39,46,38,29,14,61,15,30,1,48,52,3,63,27,4,13,89,24,46,58,33,76};
RedType b;
FILE *fi,*fo; //输入输出文件
LoserTree ls; // 败者树
WorkArea wa; // 内存工作区
int i, k;
fo = fopen("ori","wb"); //准备对 ori 文本文件进行写操作
//将数组 a 写入大文件ori
fwrite(a, sizeof(RedType), N, fo);
fclose(fo); //关闭指针 fo 表示的文件
fi = fopen("ori","rb");//准备对 ori 文本文件进行读操作
printf("文件中的待排序记录为:\n");
for(i = 1; i <= N; i++){
// 依次将文件ori的数据读入并赋值给b
fread(&b,sizeof(RedType),1,fi);
print(b);
}
printf("\n");
rewind(fi);// 使fi的指针重新返回大文件ori的起始位置,以便重新读入内存,产生有序的子文件。
fo = fopen("out","wb");
// 用置换-选择排序求初始归并段
Replace_Selection(ls, wa, fi, fo);
fclose(fo);
fclose(fi);
fi = fopen("out","rb");
printf("初始归并段各为:\n");
do{
k = fread(&b, sizeof(RedType), 1, fi); //读 fi 指针指向的文件,并将读的记录赋值给 b,整个操作成功与否的结果赋值给 k
if(k == 1){
if(b.key ==MAXKEY){//当其值等于最大值时,表明当前初始归并段已经完成
printf("\n\n");
continue;
}
print(b);
}
}while(k == 1);
return 0;
}
运行结果为:
文件中的待排序记录为:
51 49 39 46 38 29 14 61 15 30 1 48 52 3 63 27 4 13 89 24 46 58 33 76
初始归并段各为:
29 38 39 46 49 51 61
1 3 14 15 27 30 48 52 63 89
4 13 13 24 33 46 58 76
O(nlogw)(其中 n 为记录数,w 为内存工作区的大小)。
本文链接:http://task.lmcjl.com/news/16950.html


