已知数据集为: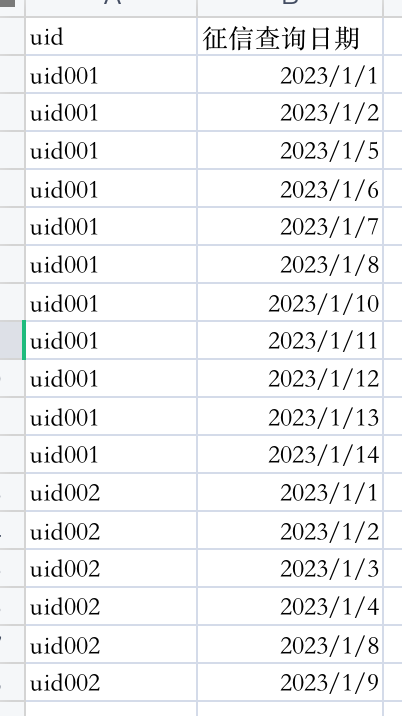
目的:
计算每个uid的连续活跃天数,并且每一段活跃期内的开始时间和结束时间
第一步:处理数据集
处理数据集,使其满足每个uid每个日期只有一条数据。
第二步:以uid为主键,按照日期进行排序,计算row_number.
SELECT uid
,`征信查询日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查询日期` ASC) AS `rn`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` ASC) `fir`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` desc) `las`
FROM input
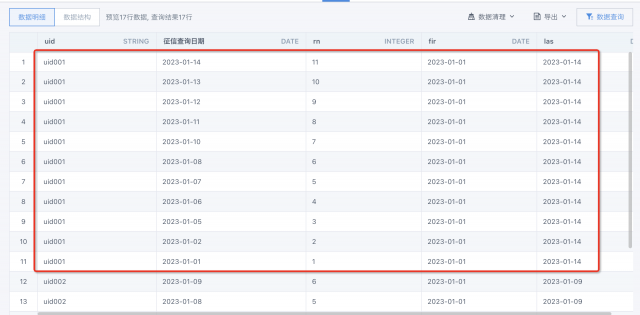
两个关键点:
select *,DATE_SUB(`征信查询日期`,`rn`) as `关键列` from (
SELECT uid
,`征信查询日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查询日期` ASC) AS `rn`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` ASC) `fir`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` desc) `las`
FROM input)
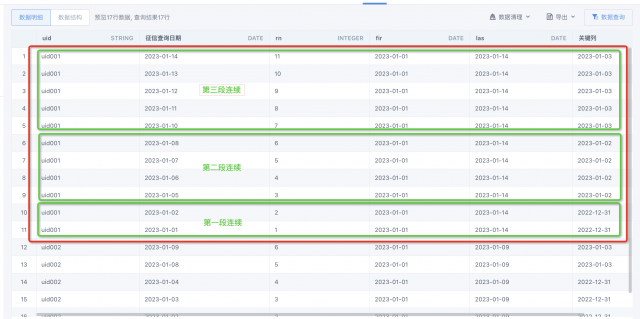
第三步:以uid和关键列作为主键。
select uid, `关键列`,count(*) as `连续活跃天数`, min(`征信查询日期`) as `活跃开始时间`, max(`征信查询日期`) as `活跃结束时间` from (
select *, DATE_SUB(`征信查询日期`,`rn`) as `关键列` from (
SELECT uid
,`征信查询日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查询日期` ASC) AS `rn`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` ASC) `fir`
,first_value(`征信查询日期`)over(PARTITION BY uid ORDER BY `征信查询日期` desc) `las`
FROM input
) )group by uid, `关键列`

原文链接:https://www.cnblogs.com/tian1022/p/17310496.html
本文链接:http://task.lmcjl.com/news/18237.html


