
本文简要介绍了论文“ Marior: Margin Removal and Iterative Content Rectification for Document Dewarping in the Wild ”的相关工作。照相机捕捉到的文档图像通常会出现透视和几何变形。考虑到视觉美感较差和OCR系统性能下降,对其进行纠正具有重要的价值。最近的基于学习的方法集中关注于精确裁剪的文档图像。然而,这可能不足以克服实际挑战,包括具有大边缘区域或没有边缘区域的文档图像。由于这种不切实际,用户在遇到大型边缘区域时难以精确地裁剪文档。同时,无边缘的变形图像仍然是一个难以解决的问题。据作者所知,目前还没有完整有效的pipeline来纠正文档图像。为了解决这个问题,作者提出了一种新的方法,称为Marior(边缘去除和迭代内容修正)。Marior采用渐进策略,以从粗到细的方式迭代地提高去变形质量和可读性。具体来说,作者将pipeline划分为两个模块:边缘去除模块(MRM)和迭代内容校正模块(ICRM)。首先,作者预测输入图像的分割掩膜去除边缘,从而得到初步结果。然后,作者通过产生密集的位移流来进一步细化图像,以实现内容感知的校正。作者自适应地确定细化迭代的次数。实验证明了作者的方法在公共基准上的最新性能。
借助移动设备中先进的内置摄像头,将日常生活中无处不在的文档数字化已经为人们变得方便。但是,由于相机的角度和位置不合适,所捕获的文档图像通常包含透视变形。此外,文档本身也可能因弯曲、折叠或折痕而发生几何变形。这些类型的变形导致了光学字符识别(OCR)系统的性能下降,并导致读者的可读性较差。
最近的基于深度学习的去变形方法在对各种文档布局的鲁棒性方面取得了很大的进展。但是,它们几乎都只关注精确裁剪的文档图像,而忽略了边缘区域较大或没有边缘区域的情况,分别如图1 (a)和(b)所示。在本研究中,边缘区域是指由不属于感兴趣的文档的像素组成的区域。为了解决这个问题,作者可以在培训过程中考虑到所有这些情况,但作者发现结果不令人满意(参考补充材料)。作者认为,这归因于额外的内隐学习来识别前景文档和去除边缘区域。另一种方法是在去变形之前实现现有的目标检测算法,以避免需要手工裁剪。然而,没有带边缘的文档图像仍然是一个未解决的问题。因此,仍然没有完整和有效的pipeline来处理自然的所有情况。
因此,作者提出了Marior(边际去除和迭代内容修正)来解决这个问题,该模块由两个级联模块组成:边缘去除模块(MRM)和迭代内容修正模块(ICRM)。Marior使边缘去除和文件整改过程解耦。具体来说,在MRM中,作者首先将源失真图像输入作者的掩膜预测网络,该网络预测相应的文档分割掩膜。在此基础上,作者提出了一种基于掩膜的去变形器(MBD)来去除基于该掩膜的边缘,并得到了初步的变形结果。对于没有边缘区域和没有完整文档边缘的图像,如图1 (b)所示,作者建议使用基于IoU的方法将它们过滤掉并跳过边缘去除过程,这一灵感来自于观察到这些图像通常会导致噪声掩膜。
之后,作者将MRM中去掉边缘的输出输入ICRM以进行进一步细化。它预测了一个密集的位移流,该流为输入图像中的每个像素分配了一个二维(2D)偏移向量。根据该流进行校正后,作者得到了一个去变形的输出图像。因为删除了边缘的图像更多关注内容(例如,文本行和图形),所以ICRM能够感知内容。因此,作者进一步设计了一种新的内容感知损失,以隐式地指导ICRM更多地关注信息区域,如文本线和图形,而不是统一的文档背景。这种设计基于一种直觉,后者包含更少的变形线索,对变形结果的轻微偏差在视觉上可以忽略不计。此外,作者还发现,ICRM的迭代实现可以提高整改性能。为此,作者提出了一种自适应的方法来确定迭代次数,以使所提出的迭代ICRM过程更加智能和高效。
综上所述,作者的贡献如下:
作者提出了一种新的方法Marior来处理具有各种边缘情况的文档图像,这些情况被现有的基于学习的方法忽略了。在作者的边缘去除模块(MRM)中提出了一种新的基于掩膜的存储器,该模块基于预测的分割掩膜对文档图像进行粗破坏。然后提出了一个迭代内容整正模块(ICRM),通过预测密集位移流来进一步细化图像。
作者设计了一种新的内容感知损失,以隐式地引导流预测网络更多地关注信息区域。作者还提出了一种自适应迭代策略来提高性能。
广泛的实验表明,所提出的Marior在两个广泛使用的公共基准上取得了最先进的性能。此外,这种方法在处理具有不同边缘的困难情况也取得了重大成功。
如图2所示,Marior包含两个级联的MBD和ICRM模块,这些模块逐步修正变形的源图像$I_s$,并输出最终的去变形图像$I_{fd}$。在MRM中,作者首先根据预测的掩膜去除边缘,得到一个初步的去变形结果$I_{pd}$。这种基于掩膜的去变形过程是通过一种新的MBD来实现的。然后ICRM以作为输入$I_{pd}$,预测与$I_{pd}$具有相同分辨率的密集位移流。这个二维流分配了$I_pd$中每个像素应该移动的距离,以获得$I_{fd}$。基于这个位移流,作者从$I_{pd}$中取样$I_{fd}$。为了获得更好的修正性能,作者迭代实现了ICRM,提出了一种自适应的方法来确定迭代次数
3.1边缘去除模块(MRM)
掩膜预测。为了从给定的图像中删除边缘,作者首先要定位文档区域。作者认为定位是一个语义分割任务,其目的是产生一个精确表示文档区域的掩膜。作者的掩膜预测网络的体系结构如图3(a)所示,直接采用了DeepLabv3+ 中的编码器和解码器。除了文档掩膜外,作者还设计了一个头部来产生一个用于辅助训练的边缘掩膜。此外,作者观察到文档掩膜具有一个独特的和相对固定的模式,如相对直的边、一个较大的连接区域和一个接近四边形的形状。如图3 (a)所示,作者使用GAN框架将这些先验知识应用到MRM中。作者发现这可以有效地降低所产生的掩膜上的噪声,如图3 (b)。所示该目标被定义为: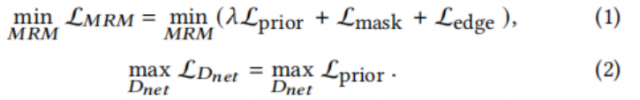
$L_{mask}$和$L_{edge}$是标准的二进制交叉熵损失: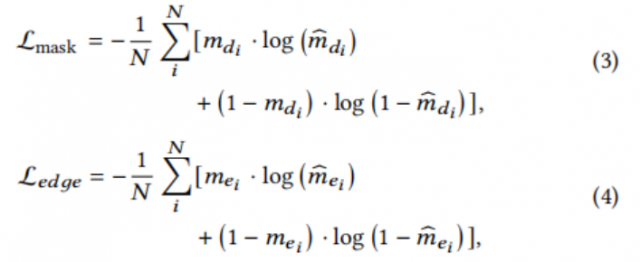
其中,${\hat{m}{d_i}}$和${\hat{m}{e_i}}$表示文档掩膜${\hat{m}_d}$和${\hat{m}_e}$边缘掩膜中的第i个元素的预测分类,和分别为它们对应的ground truth。N是${\hat{m}d}$中元素的数量。$L$是GAN框架中的一个标准目标,它使${\hat{m}d}$的分布更接近ground truth掩膜${{m}d}$的分布,$\lambda$是$L$的权重: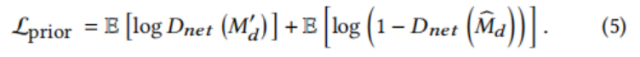
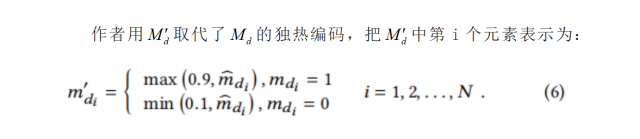
这是为了在优化鉴别器时,减少独热编码正样本与生成的负样本之间的分布差距。值得注意的是,该掩膜预测模型也可以作为其他替代的分割模型,它只需要能够提供文档区域的分割掩膜。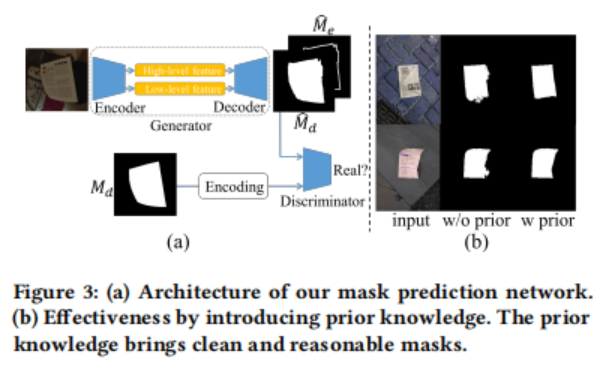
基于掩膜的去变形器(MBD)。在获得文档掩膜后,作者提出了一种新的MBD来去除边缘并进行初步的去变形,如图4所示。具体来说,基于预测的掩膜,作者首先使用道格拉斯佩克算法检测四个角,然后根据它们的相对位置确定顺序(左上、右上、右下、左下)。然后作者可以在每条边上确定等距的点(在作者的实验中,除了四个角外,作者在每条边上使用三个等距的点)。作者将这些控制点与一个矩形的相应位置进行匹配。然后利用这些关键点对对$I_s$进行薄板样条(TPS)插值,从而去除边缘,得到$I$。值得注意的是,对于没有边缘区域的文档图像,它们没有完整的边缘,如图1 (b)所示,作者跳过TPS插值,将$I_s$原始作为MBD的输出。作者通过计算${\hat{m}_d}$和来自所有检测控制点的掩膜之间的IoU来过滤这些图像,并设置一个阈值。这是因为可以观察到,没有完全边缘的文档图像通常会导致噪声${\hat{m}_d}$,从而导致相对较低的IoU。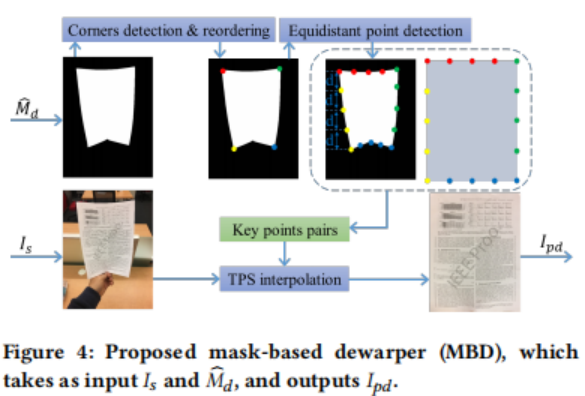
3.2迭代内容校正模块(ICRM)
使用MRM进行初步去变形的结果并不完美。原因有两方面。第一个原因是在每条边上选择等距点不考虑深度信息;因此,这种等距划分与在物理纸上进行的划分不一致。第二个原因是,有时,当预测的掩膜遇到不清楚的边缘或非常复杂的边缘时,它并不够准确。此外,没有边缘区域的文档图像跳过了初步的去变形,因此仍然没有被触及。
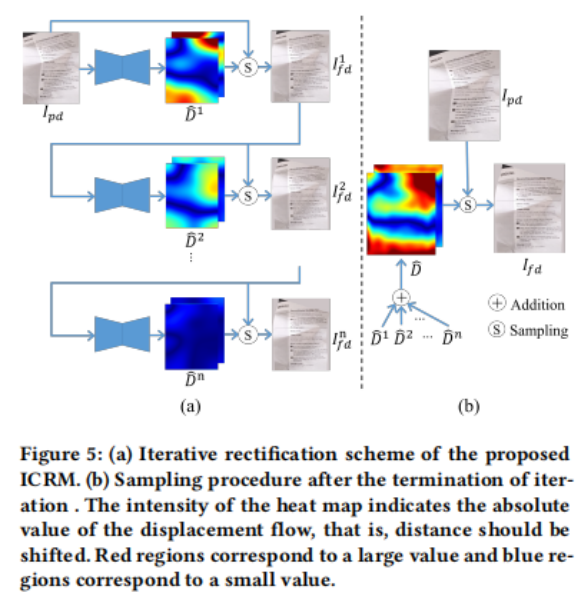
为了进一步校正$I_{pd}$,作者提出了ICRM,它以$I_{pd}$作为输入,产生一个${\hat{D}}$密集的位移流。作者采用常用的具有跳过连接的编解码器作为作者的位移流预测网络。作者在瓶颈和扩展卷积中采用注意力策略来扩大接受场以捕获全局信息。如前所述,对信息区域的修正,如文本线和数字,在直观上比统一的文档背景更重要。作者使用文档内容掩膜${{M}_c}$来设计内容感知损失$L_c$,它隐式地引导网络更多地关注信息区域。作者也采用了移位不变损失$L_c$。ICRM的最终训练损失表示为:
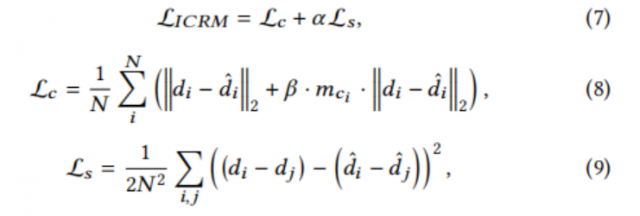
式中${\hat{d}_i}$、${{d}i}$和${m{c_i}}$分别表示预测位移流${\hat{D}}$、ground truth位移流和文档内容掩膜${{M}_c}$中的第i个元素。${\alpha}$和${\beta}$是恒定的权重。
因为作者在MRM中完成了边缘的去除,所以ICRM应该专注于内容修正,而不需要额外的隐式学习来识别前景文档并去除边缘区域。边际去除的分离也使ICRM能够采用迭代方案对文档逐步进行修正,作者发现这可以提高整改性能。如果边际去除没有解耦,网络可能会学习基于文档边缘来纠正文档,并倾向于在每次迭代中找到它们,即使它们不存在,这将导致有问题的输出。作者的迭代方案如图5 (a).所示首先,作者将${I_{pd}}$输入位移流预测网络,得到第一个位移流${\hat{D1}}$,然后作者可以用它从${I_{pd}}$中采样${{I1}_{fd}}$:
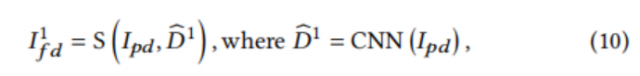
其中,S为采样过程。如图5 (a)所示,在${{I^1}_{fd}}$中仍存在变形。作者采用迭代方案进一步细化整正结果,公式如下:
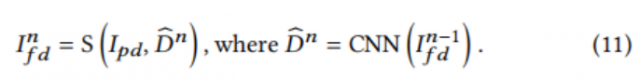
经过多次迭代,${{I1}_{fd}}$取得了令人满意的整改性能。由于输入${{I{n-1}}_{fd}}$相对平坦,${\hat{D^n}}$的响应显著降低。更多的迭代会消耗更多的时间,甚至会引入新的变形。因此,迭代过程应该在适当的时间终止。作者提出了一种自适应的方法来确定这个时间,如算法1所示。

这里的var(${\hat{Dn}}$)是${\hat{Dn}}$的方差,${\hat{D}}$是一个预定义的常数值,作为阈值。迭代过程结束后,作者通过将之前所有的${\hat{D^i}}$(i=1,2,…,n)相加得到最终的位移流${\hat{D}}$,得到基于${\hat{D}}$的最终变形结果${I_{fd}}$: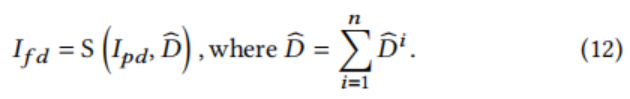
4.1数据集
作者在Doc3D 数据集上训练MRM和ICRM中的两个网络,该数据集包含100k个丰富注释的样本。作者将数据集分为90k训练数据和10k验证数据。在掩膜预测训练过程中,作者随机将边缘替换为《Describing textures in the wild.》纹理图像的边缘作为数据增强。除了常用的随机裁剪和缩放外,作者还采用了随机擦除的方法。ICRM的训练数据(包括源失真输入图像和ground truth位移流)首先由作者提出的MBD进行预处理。作者认为从反照率图(在Doc3D中提供)得到的二值化结果是等式8中的$M_c$。
4.2消融实验
作者将没有数据增强的vanilla DeepLabv3+作为baseline,并给出了在表1中获得的改进。作者使用在《Real-time document localization in natural images by recursive application of a CNN》中提出的数据集验证了模型,它由120个真实单词的文档图像组成。该数据集是为文档定位而构建的,并且只使用文档的四个角进行注释,作者使用它来生成四边形ground truth掩膜(这些文档图像只包含透视变形)。如表1所示,数据增强大大提高了性能。在作者的MRM中的掩膜预测网络也得到了改进。引入先验知识的有效性见图3 (b)。
作者进一步评估了提出的内容感知损失在Doc3D验证集上的有效性。作者使用结构相似度指数(SSIM)来评估由${\hat{D}}$产生的修正图像的质量。如表2所示,作者使用${\beta}$=3的设置获得了最好的图像质量,这表明了作者提出的内容感知损失的贡献。
4.3在公共基准上的比较
评价指标。作者使用多尺度结构相似度(MS-SSIM)和局部失真(LD)来评估所产生的校正图像与其扫描的ground truth值之间的图像相似度。MS-SSIM是一种广泛应用的图像结构相似度评价度量。LD通过预测密集的SIFT流来评估局部失真。此外,作者使用带有LSTM引擎的Tesseract 4.1.01作为文本识别器,对校正图像上的文本进行识别,也显示了校正性能。作者使用字符错误率(CER)来评估识别结果,该错误率来自于识别文本和参考文本之间的列文斯坦距离。CER可以计算为${CER=(s+i+d)/N,其中s,i和d分别是来自列文斯坦距离的替换、插入和删除的数量。N是参考文本中的字符数。
DocUNet benchmark。该数据集的定量结果如表3所示,其中“Crop”代表了以往研究中通常用于比较的准确裁剪图像。“Origin”表示最初捕获的图像,因此包含较大的边缘区域。为了进行更公平的比较,在“Origin”子集上进行实验时,使用Faster R-CNN 作为附加到其他方法上的文档检测器。这个探测器的细节包括在补充材料中。按照DewarpNet[7]中的建议,对50张富含文本的图像执行文本识别。作者将从相应扫描的ground truth图像中识别出的文本作为参考文本。
作者首先评估了内容整改和迭代策略的有效性。结果显示在表3的最后三行中。Baseline是没有ICRM的Marior(即,只采用MRM)。在没有迭代的情况下实现一次内容修正后(即表3中的Marior w/o iteraion),所有三个指标都得到了显著的改善。特别是,在“Crop”和“Origin”子集上的CER分别降低了19%和14%。这证明了ICRM对文档内容整改的有效性。此外,在作者迭代实现文档内容整改(即表3中的Marior)后,结果进一步改善。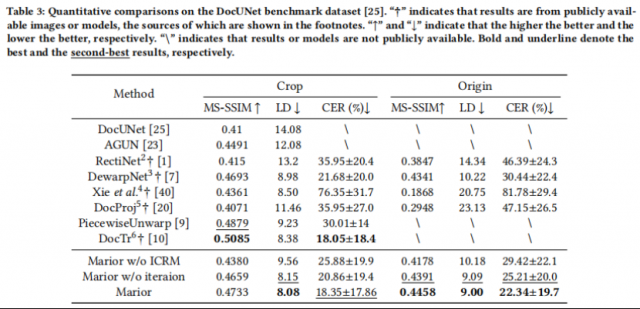
与“Crop”子集上的现有方法相比,Marior取得了相当的性能。然而,在“Origin”子集上,Marior方法比现有的方法更好,即使Marior也没有检测器的帮助。定性比较如图6和图7所示。在图6中,作者将作者的方法与DocProj [20]、DewarpNet [7]和Xie等人的[40]的方法进行了比较。前三列中的输入图像来自于“Crop”子集。虽然DocProj [20]在一定程度上纠正了文档内容,但边缘仍然存在,这导致了糟糕的视觉美学。删除网[7]和Xie等[40]的方法很好地纠正了文档内容,同时删除了边缘。与[7]和[40]方法相比,作者的方法还取得了良好的感知性能和细节方面的性能。第4列和第5列的输入图像来自“Origin”子集,如果借助一个强大的文档检测器,以前的方法可以获得可信的结果。相比之下,Marior可以用嘴探测器来处理这个子集。对于在第6列、第7列中没有边缘区域的输入图像,Marior仍然取得了令人满意的性能,而现有的方法却没有。作者与图7中最先进的无变形方法和DocTr进行了进一步的比较,这也证明了作者的前后方法的优越性。
OCR_REAL dataset。这个数据集包含文本ground truth,作者认为它是CER度量的参考文本。此外,由于缺乏扫描的ground truth图像,作者不评估MS-SSIM和LD。识别性能与识别引擎高度相关。因此,为了更严格,作者在Tesseract 4.1.01中同时使用基于深度学习(LSTM)和非基于深度学习的引擎来执行识别。作者还评估了在该数据集上的不同方法的平均运行时间。为了进行公平的比较,当作者评估运行时间时,保持每种方法的输出图像的分辨率相同(1024×960),当采样图像的分辨率不同时,运行时间会有所不同。结果如表4所示,与其他方法相比,DocProj [20]、DocTr [10]和Marior在两种识别引擎下都实现了稳定和优越的性能。然而,DocProj [20]和DocTr [10]比Marior更耗时。另外,如前所分析,如图8所示,DocProj [20]由于无法去除边缘,无法实现Marior呈现的视觉美感。
作者提出了一种简单而有效的方法,Marior,以从粗到细的方式为变形文档图像矫正。作者采用两个级联模块,首先去除文档图像的边缘,然后对内容进行进一步的修正。所提出的Marior自适应地决定了迭代的次数,从而实现了效率和性能之间的权衡。作者提出的方法不仅在DocUNet [25]和OCR_REAL [23]基准数据集上取得了最先进的性能,而且成功地解决了具有大边缘区域的情况和没有边缘区域的情况,这在以往的研究中研究较少。这是在自然文档矫正方面的一个重大成功。在今后的工作中,有必要探索对这两个模块进行端到端优化,以获得更好的性能。
原文链接:https://www.cnblogs.com/intsig/p/17361280.html
本文链接:http://task.lmcjl.com/news/5579.html


