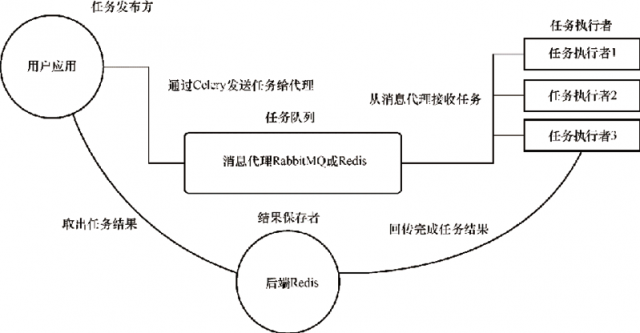
图1:Celery 的架构
# 安装Celery pip install celery==5.2.3 # 因为后端采用的是Redis,所以需要安装Redis pip install redis==4.2.0 # flower组件可以通过Web进行对Celery进行监控,但它不是必需的 pip install flower==1.0.0
注意,参数名称要大写。
| 参数配置示例 | 配置说明 |
|---|---|
|
BROKER_URL = 'amqp://username:passwd@ host:port/虚拟主机名' |
消息中间件的地址,建议采用 RabbitMQ 的方式。 |
| CELERY_RESULT_BACKEND='redis://username:passwd@host:port/db' | 指定结果的存储地址。 |
| CELERY_TASK_SERIALIZER='msgpack' | 指定任务的序列化方式。 |
| CELERY_TASK_RESULT_EXPIRES=60*60*24 | 任务过期时间,即 Celery 任务执行结果的超时时间。 |
| CELERY_ACCEPT_CONTENT=["msgpack"] | 指定任务接受的序列化类型。 |
| CELERY_ACKS_LATE=True | 是否需要确认任务发送完成,这一项对性能有影响。 |
| CELERY_MESSAGE_COMPRESSION='zlib' | 压缩方案选择,可以是 zlib 或 bzip2,默认为没有压缩。 |
| CELERYD_TASK_TIME_LIMIT=5 | 规定完成任务的时间,在5秒内完成任务,否则执行该任务的任务执行者将被杀死,任务移交给父进程。 |
| CELERYD_CONCURRENCY=4 |
任务执行者的并发数,默认为服务器的内核数目,可以使用命令行参数-c指定数目。 |
| CELERYD_PREFETCH_MULTIPLIER=4 | 任务执行者每次从消息中间件预取的任务数量。 |
| CELERYD_MAX_TASKS_PER_CHILD=40 | 每个任务执行者执行多少任务会死掉,默认为无限。 |
| 序列化方式 | 说明 |
|---|---|
| binary | 二进制序列化方式,Python 的 pickle 库默认的序列化方式。 |
| JSON | 支持多种语言,可用于跨语言方案,但不支持自定义的类对象。 |
| msgpack | 二进制的类 JSON 序列化方式,但比 JSON 方式的数据结构更小,运行速度更快。 |
| yaml | 表达能力更强,支持的数据类型比 JSON 方式多,但是 Python 客户端的性能不如 JSON 方式。 |
# -*- coding: utf-8 -*-
# @Project : celeryDemo
# @File : celery_task.py
# @Date : 2023-08-26
import celery
import time
backend = 'redis://127.0.0.1:6379/1' # 设置Redis的1数据库来存放结果
broker = 'redis://127.0.0.1:6379/2' # 设置Redis的2数据库来存放消息中间件
cel = celery.Celery('test', backend=backend, broker=broker)
# 参数说明:第一个是Celery的名字,Celery和哪个项目相关就命名哪个
# 后面两个关键字参数用于指定消息中间件和结果存放位置。
@cel.task
def send_email(name):
print("向%s发送邮件..." % name)
time.sleep(5)
print("向%s发送邮件完成" % name)
return "ok"
@cel.task
def send_msg(name):
print("向%s发送短信..." % name)
time.sleep(5)
print("向%s发送短信完成" % name)
return "ok"
celery --app=demo worker -l INFO
from celery_task import send_email, send_msg
result1 = send_email.delay("张三")
print(result1.id)
result2 = send_email.delay("李四")
print(result2.id)
result3 = send_email.delay("王五")
print(result3.id)
result4 = send_email.delay("赵六")
print(result4.id)
注意,运行的结果不是异步函数的返回值,而是一个 ID,因为 Celery 会将函数进行异步处理,处理结果会存放至指定的数据库,而我们取值需要使用 ID。
from celery.result import AsyncResult
from celery_task import cel
async_result=AsyncResult(id="275f43a8-a5bb-4822-9a90-8be3feeb3b4", app=cel)
if async_result.successful():
result = async_result.get()
print(result)
# result.forget() # 将结果删除
elif async_result.failed():
print('执行失败')
elif async_result.status == 'PENDING':
print('任务等待中被执行')
elif async_result.status == 'RETRY':
print('任务异常后正在重试')
elif async_result.status == 'STARTED':
print('任务已经开始被执行')
说明:执行失败的效果是代码有错但是异步不停止,还是会执行获得 ID,但是当获取结果时,async_result.failed() 为真。如果要演示记得重启 Celery,否则修改不生效。
# tasks.py
# 继承Task类
class MyTask(Task):
def on_success(self, retval, task_id, args, kwargs):
print 'task done: {0}'.format(retval)
return super(MyTask, self).on_success(retval, task_id, args, kwargs)
def on_failure(self, exc, task_id, args, kwargs, einfo):
print 'task fail, reason: {0}'.format(exc)
return super(MyTask, self).on_failure(exc, task_id, args, kwargs, einfo)
@app.task(base=MyTask)
def add(x, y):
return x + y
上面的代码通过 celery -A tasks worker --loglevel=info 运行任务执行者,根据任务状态执行不同操作,分别执行我们自定义的 on_failure 方法和 on_success 方法。
图2:myCelery 的项目结构
# -*- coding: utf-8 -*-
# @Time : 2023/8/26 6:49 下午
# @Project : myCelery
# @File : celeryApp.py
# @Version: Python3.9.8
from flask import Flask
from celery import Celery, platforms
from urllib.parse import quote
REDIS_IP = '172.21.26.54'
REDIS_DB = 0
# 若密码中出现了特殊的字符,建议用quote()进行转义,直接赋值会导致后续读取失败
PASSWORD = quote('hutong123456')
# 创建Flask的一个实例
flask_app = Flask(__name__)
# 配置Celery的backend和broker,只需要在初始化Flask应用时加入这行代码,将下面的配置信息写入应用的配置文件
# 使用Redis作为消息代理
flask_app.config['CELERY_BROKER_URL'] = 'redis://:{}@{}:6379/{}'.format(PASSWORD, REDIS_IP, REDIS_DB)
# 把任务结果保存在Redis中
flask_app.config['CELERY_RESULT_BACKEND'] = 'redis://:{}@{}:6379/{}'.format(PASSWORD, REDIS_IP, REDIS_DB)
platforms.C_FORCE_ROOT = True # 解决根用户不能启动Celery的问题
# CELERY_ACCEPT_CONTENT = ['application/json']
# CELERY_TASK_SERIALIZER = 'json'
# CELERY_RESULT_SERIALIZER = 'json'
# 创建一个Celery实例
celery_app = Celery(flask_app.name,
broker=flask_app.config['CELERY_BROKER_URL'],
backend=flask_app.config['CELERY_RESULT_BACKEND'],
include=['task', 'task2'])
celery_app.conf.update(flask_app.config)
celery_app.autodiscover_tasks()
if __name__ == '__main__':
pass
Celery 通过创建一个 Celery 类对象来初始化,传入 Flask 应用的名称、消息代理的连接 URL、存储结果的 URL 以及包含的 task 任务列表。URL 放在 flask_app.config 中的 CELERY_BROKER_URL 和 CELERY_RESULT_BACKEND 的键值。
# -*- coding: utf-8 -*-
# @Time : 2023/8/26 9:58 上午
# @Project : myCelery
# @File : task.py
# @Version: Python3.9.8
from celeryApp import celery_app
import time
# 这里定义一个后台任务task,异步执行装饰器为@celery_app.task
@celery_app.task(bind=True)
def long_task(self):
total = 100
for i in range(total):
# 自定义状态state为waiting..,另外添加元数据meta,模拟任务当前的进度状态
self.update_state(state='waiting..', meta={'current': i, 'total': total, })
# 使用sleep模拟耗时的业务处理
time.sleep(1)
# 任务处理完成后,自定义返回结果
return {'current': 100, 'total': 100, 'result': 'completed'}
因为前面配置定义的 Celery 的实例化对象名称叫 celery_app,所以在装饰器的时候要用 @celery_app.task。| 参数 | 说明 |
|---|---|
| PENDING | 任务等待中 |
| STARTED | 任务已开始 |
| SUCCESS | 任务执行成功 |
| FAILURE | 任务执行失败 |
| RETRY | 任务将被重试 |
| REVOKED | 任务取消 |
# -*- coding: utf-8 -*-
# @Time : 2023/8/26 10:42 上午
# @Project : myCelery
# @File : webFlask.py
# @Version: Python3.9.8
from flask import jsonify, url_for
from celeryApp import flask_app
from task import long_task
# 通过在浏览器中输入ip:port/longtask触发异步任务
@flask_app.route('/longtask', methods=['GET'])
def longtask():
# 发送或触发异步任务,通过调用apply_async函数,生成AsyncResult对象
task = long_task.apply_async()
print('task id : {}'.format(task.task_id))
# task_id和id一样的
# print('task id : {}'.format(task.id))
# url_for重定向到taskstatus()
return jsonify({"msg": "success"}), 202, {'Location': url_for('taskstatus',
task_id=task.task_id)}
# 通过在浏览器中输入ip:port/status/<task_id>查询异步任务的执行状态
@flask_app.route('/status/<task_id>')
def taskstatus(task_id):
# 获取异步任务的结果
task = long_task.AsyncResult(task_id)
print('执行中的 task id :{}'.format(task))
# 等待处理
if task.state == 'PENDING':
response = {
'state': task.state,
'current': 0,
'total': 100
}
# 执行中
elif task.state != 'FAILURE':
print('task info : {}'.format(task.info))
# task.info 和 task.result是一样的
# print('task info : {}'.format(task.result))
response = {
'state': task.state,
'current': task.info.get('current', 0),
'total': task.info.get('total', 100)
}
# task中定义了执行成功后返回的结果包含result字符
if 'result' in task.info:
response['result'] = task.info['result']
else:
# 后台任务出错
response = {
'state': task.state,
'current': task.info.get('current', 0),
'total': 100
}
return jsonify(response)
if __name__ == '__main__':
# 运行Flask
flask_app.run()
在上述代码中,Flask 应用能够请求执行这个后台任务,如 task=long_task.apply_async(),不直接调用任务函数,而是通过 apply_async() 调用任务函数。其中,long_task() 函数就是在一个 worker 进程中运行的任务。apply_async(args=[10, 20], countdown=60)
调用 apply_async() 后会返回一个 AsyncResult 对象,通过这个对象可以获取任务状态的信息,AsyncResult 对象的属性或函数如表4所示。
| 属性或函数 | 具体含义 |
|---|---|
| state | 返回任务状态 |
| task_id | 返回任务ID |
| result | 返回任务执行结果,等同于调用get()方法 |
| ready() | 判断任务是否完成 |
| info() | 获取任务信息 |
| wait(seconds) | 等待N秒后获取结果 |
| successful() | 判断任务是否成功 |
celery -A celeryAPP.celery_app worker --loglevel=info
其中,参数-A后是我们创建的 Celery 的初始化实例对象名称,包含对应的任务,worker 表示该实例就是任务执行者。另外,该命令需要在项目工程目录下执行,即本示例的 myCelery 目录。
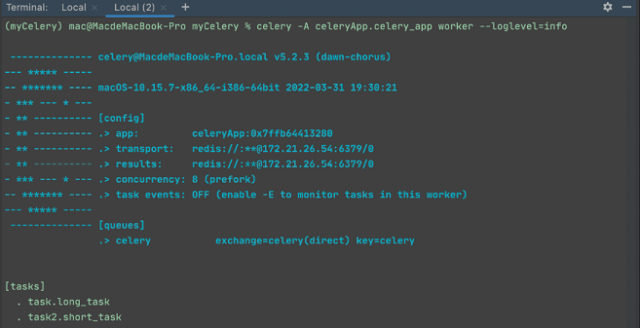
图3:Celery任务启动成功
# 后台启动worker进程,参数-l指定worker输出的日志级别 celery multi start worker_1 -A appcelery -l info # 重启worker进程 celery multi restart worker_1 -A appcelery -l info # 立刻停止worker进程,如果无法停止,则加上参数-A celery multi stop worker_1 # 任务执行完,停止 celery multi stopwait worker_1 # 查看进程数 celery status -A appcelery
from celery.utils.log import get_task_logger
lg = get_task_logger(__name__)
@celery.task
def log_test():
lg.debug("in log_test()")
但是仅如此我们会发现所有的日志最后都出现在 shell 窗口的 stdout 中,所以必须在启动 Celery 的时候使用-f选项来指定输出文件,如下:
celery -A main.celery worker -l debug -f log/celery/celery_task.log &
然后,启动 Flask,调用异步任务和获取异步任务执行状态,我们只需要在 PyCharm 中运行 webFlask 程序即可,运行成功后如图4所示。
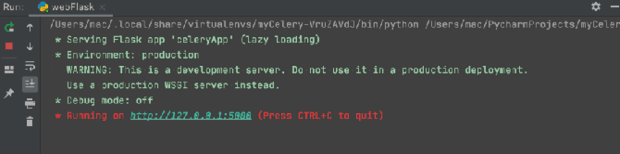
图4:Celery 结合 Flask 启动
图5:在浏览器中触发 longtask 模拟的耗时任务
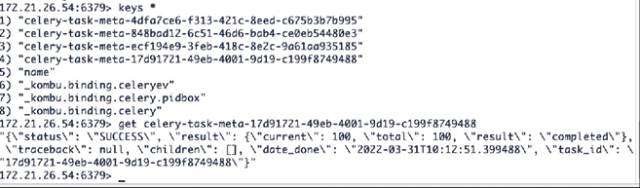
图6:查看队列任务
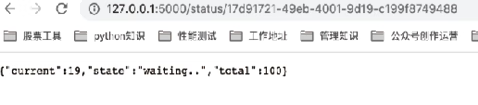
图7:异步任务状态1
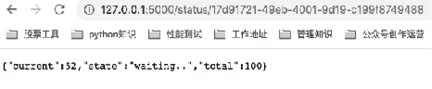
图8:异步任务状态2
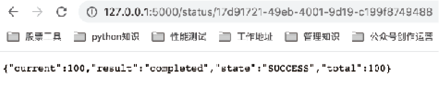
图9:异步任务状态3
celery -A celeryApp.celery_app flower --port=5556 --basic_auth=admin:admin
结果如图10所示。
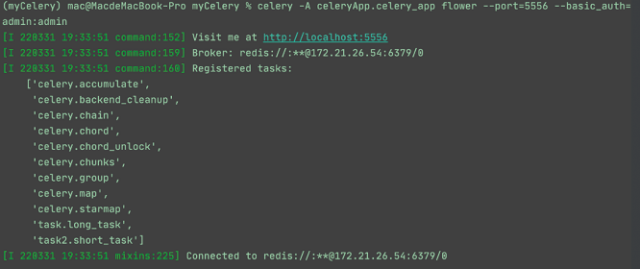
图10:监控任务队列
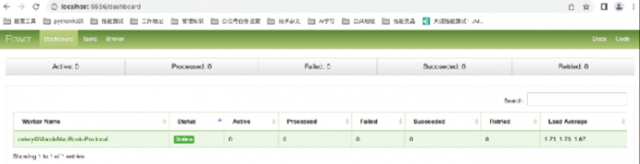
图11:任务消费者
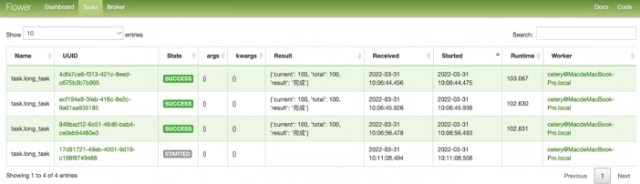
图12:任务名称
本文链接:http://task.lmcjl.com/news/5841.html


