Stereo R-CNN based 3D Object Detection for Autonomous Driving
通过充分利用立体图像中的稀疏、密集、语义和几何信息,提出了一种用于自动驾驶的称为立体声R-CNN的三维物体检测方法。它扩展了立体输入的快速R-CNN,以同时检测和关联左右图像中的对象。
在立体区域提议网络(RPN)之后添加额外的分支来预测稀疏的关键点、视点和对象尺寸,并结合二维左右框来计算粗略的三维对象边界框。然后,我们使用左右获取的ROI,通过基于区域的光度学对齐来恢复精确的3D边界框。
此方法不需要深度输入和三维位置监控,但是优于现有的所有基于全监控图像的方法。在具有挑战性的KITTI数据集上的实验表明,此方法在3D检测和3D定位任务上都比目前最先进的基于立体的方法有大约30%的AP。
(1)一种立体R-CNN方法,它同时检测和关联立体图像中的目标。
(2)一种利用关键点和立体盒约束的三维盒估计器。
(3)一种基于密集区域的光度学对准方法,可确保我们的三维物体定位精度。
(4)对KITTI数据集的评估表明,我们的性能优于所有最先进的基于图像的方法,甚至可以与基于激光雷达的方法相比。
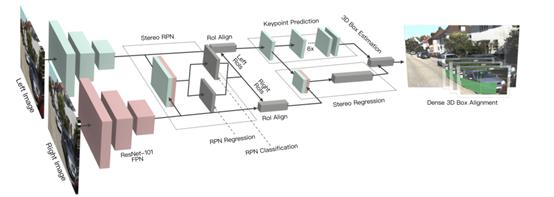
使用所提出的立体R-CNN同时检测和关联左、右图像中的目标,使用权重共享ResNet-101和FPN作为骨干网络来提取左右图像的一致特征。
网络架构图主要分为三个部分:(1)RPN:立体声RPN模块,输出相应的左右感兴趣区域。
RPN:是一种基于滑动窗口的前景检测器。特征提取后,利用3×3卷积层对信道进行缩减,然后利用两个同级全连接层对目标进行分类,并对每个输入位置用预先定义的多尺度盒进行定位,回归盒偏移量。
计算正锚相对于目标联合GT框中包含的左GT框和右GT框的偏移量,分别为左回归和右回归指定偏移量。立体回归器有六个回归项:。其中,用u,v表示图像空间中2D框中心的水平和垂直坐标,w、h表示盒子的宽度和高度,使用v、h的偏移量△v、△h去校正立体图像。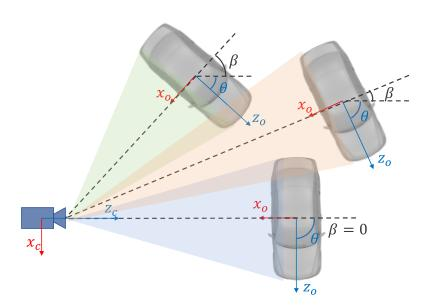
θ表示车辆相对于摄像机框架的方向,β表示相对于摄像机中心的目标方位角。
三种车辆的方向不同,但在裁剪后的RoI图像上,它们的投影是完全相同的。因此,我们回归定义为:α=θ+β。还可以表示为。
(2)Stereo Regression:在分别对左、右特征图应用ROI Align之后,将左、右RoI特征连接起来,并对对象进行分类。同时在立体回归中回归精确的2D立体框、视点和维度分支机构。(四个子分支分别预测对象类别、立体包围盒、维度和视点角度。)
(3)keypoint的检测:采用的是类似于mask rcnn的结构进行关键点的预测,定义了4个3D semantic keypoint,即车辆底部的3D corner point,同时将这4个点投影到图像,得到4个perspective keypoint。
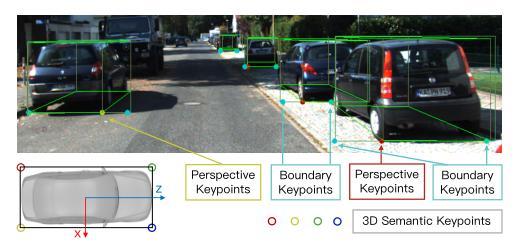
定义了四个3D语义关键点,它们指示3D边界框底部的四个角。只有一个三维语义关键点可以明显地投影到框的中间(不是左边缘就是右边缘)。我们将这个语义关键点的投影定义为透视关键点。我们还预测了两个边界关键点,作为规则形状对象实例掩码的简单替代。只有两个边界关键点之间的区域属于当前对象,将用于进一步的密集对齐。
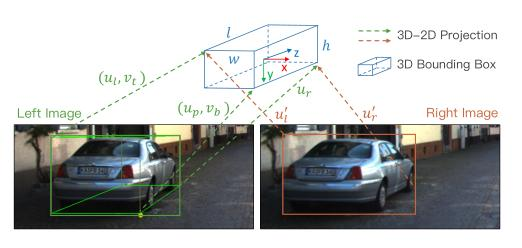
利用稀疏的关键点和二维盒信息来求解一个粗糙的三维边界盒。三维包围盒的状态可用x={x,y,z,θ}表示,分别表示三维中心位置和水平方向。在给定左右二维框、透视关键点和回归尺寸的情况下,通过最小化二维框和关键点的重投影误差,可以求解三维框。
从立体框和透视关键点提取七个测量值 表示左二维框的左、上、右、下边缘、右二维框的左、右边缘以及透视关键点的u坐标。
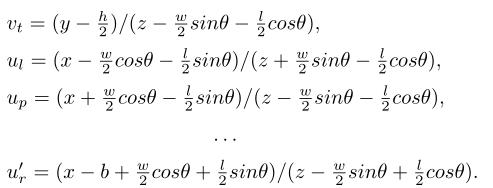
用b表示立体相机的基线长度,用w,h,l表示回归尺寸。
光度误差: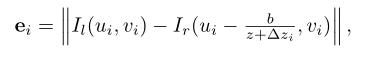
训练损失: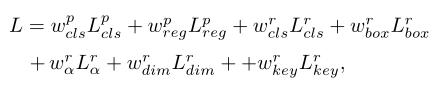
本文链接:http://task.lmcjl.com/news/5961.html


