作者:may0324
更新:
没想到这篇文章写出后有这么多人关注和索要源码,有点受宠若惊。说来惭愧,这个工作当时做的很粗糙,源码修改的比较乱,所以一直不太好拿出手。最近终于有时间整理了一下代码并开源出来了。关于代码还有以下几个问题:
~1.在.cu中目前仍然是调用cpu_data接口,所以可能会增加与gpu数据交换的额外耗时,这个不影响使用,后面慢慢优化。~(已解决)
2.目前每层权值修剪的比例仍然是预设的,这个比例需要迭代试验以实现在尽可能压缩权值的同时保证精度。所以如何自动化选取阈值就成为了后面一个继续深入的课题。
3.直接用caffe跑出来的模型依然是原始大小,因为模型依然是.caffemodel类型,虽然大部分权值为0且共享,但每个权值依然以32float型存储,故后续只需将非零权值及其下标以及聚类中心存储下来即可,这部分可参考作者论文,写的很详细。
4.权值压缩仅仅压缩了模型大小,但在前向inference时不会带来速度提升。因此,想要在移动端做好cnn部署,就需要结合小的模型架构、模型量化以及NEON指令加速等方法来实现。
代码开源在github
https://github.com/may0324/DeepCompression-caffe
最近又转战CNN模型压缩了。。。(我真是一年换N个坑的节奏),阅读了HanSong的15年16年几篇比较有名的论文,启发很大,这篇主要讲一下Deep Compression那篇论文,因为需要修改caffe源码,但网上没有人po过,这里做个第一个吃螃蟹的人,记录一下对这篇论文的理解和源码修改过程,方便日后追本溯源,同时如果有什么纰漏也欢迎指正,互相交流学习。
这里就从Why-How-What三方面来讲讲这篇文章。
首先讲讲为什么CNN模型压缩刻不容缓,我们可以看看这些有名的caffe模型大小:
1. LeNet-5 1.7MB
2. AlexNet 240MB
3. VGG-16 552MB
LeNet-5是一个简单的手写数字识别网络,AlexNet和VGG-16则用于图像分类,刷新了ImageNet竞赛的成绩,但是就其模型尺寸来说,根本无法移植到手机端App或嵌入式芯片当中,就算是想通过网络传输,较高的带宽占用率也让很多用户望尘莫及。另一方面,大尺寸的模型也对设备功耗和运行速度带来了巨大的挑战。随着深度学习的不断普及和caffe,tensorflow,torch等框架的成熟,促使越来越多的学者不用过多地去花费时间在代码开发上,而是可以毫无顾及地不断设计加深网络,不断扩充数据,不断刷新模型精度和尺寸,但这样的模型距离实用却仍是望其项背。
在这样的情形下,模型压缩则成为了亟待解决的问题,其实早期也有学者提出了一些压缩方法,比如weight prune(权值修剪),权值矩阵SVD分解等,但压缩率也只是冰山一角,远不能令人满意。今年standford的HanSong的ICLR的一篇论文Deep Compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding一经提出,就引起了巨大轰动,在这篇论文工作中,他们采用了3步,在不损失(甚至有提升)原始模型精度的基础上,将VGG和Alexnet等模型压缩到了原来的35~49倍,使得原本上百兆的模型压缩到不到10M,令深度学习模型在移动端等的实用成为可能。
Deep Compression 的实现主要有三步,如下图所示: 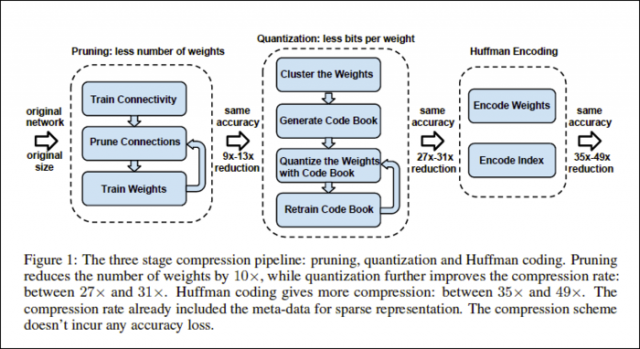
包括Pruning(权值修剪),Quantization(权值共享和量化),Huffman Coding(Huffman编码)。
如果你调试过caffe模型,观察里面的权值,会发现大部分权值都集中在-1~1之间,即非常小,另一方面,神经网络的提出就是模仿人脑中的神经元突触之间的信息传导,因此这数量庞大的权值中,存在着不可忽视的冗余性,这就为权值修剪提供了根据。pruning可以分为三步:
step1. 正常训练模型得到网络权值;
step2. 将所有低于一定阈值的权值设为0;
step3. 重新训练网络中剩下的非零权值。
经过权值修剪后的稀疏网络,就可以用一种紧凑的存储方式CSC或CSR(compressed sparse column or compressed sparse row)来表示。这里举个栗子来解释下什么是CSR
假设有一个原始稀疏矩阵A
CSR可以将原始矩阵表达为三部分,即AA,JA,IC
其中,AA是矩阵A中所有非零元素,长度为a,即非零元素个数;
JA是矩阵A中每行第一个非零元素在AA中的位置,最后一个元素是非零元素数加1,长度为n+1, n是矩阵A的行数;
IC是AA中每个元素对应的列号,长度为a。
所以将一个稀疏矩阵转为CSR表示,需要的空间为2*a+n+1个,同理CSC也是类似。
可以看出,为了达到压缩原始模型的目的,不仅需要在保持模型精度的同时,prune掉尽可能多的权值,也需要减少存储元素位置index所带来的额外存储开销,故论文中采用了存储index difference而非绝对index来进一步压缩模型,如下图所示: 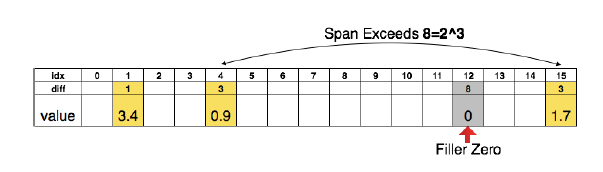
其中,第一个非零元素的存储的是他的绝对位置,后面的元素依次存储的是与前一个非零元素的索引差值。在论文中,采用固定bit来存储这一差值,以图中表述为例,如果采用3bit,则最大能表述的差值为8,当一个非零元素距其前一个非零元素位置超过8,则将该元素值置零。(这一点其实也很好理解,如果两个非零元素位置差很多,也即中间有很多零元素,那么将这一元素置零,对最终的结果影响也不会很大)
做完权值修剪这一步后,AlexNet和VGG-16模型分别压缩了9倍和13倍,表明模型中存在着较大的冗余。
为了进一步压缩网络,考虑让若干个权值共享同一个权值,这一需要存储的数据量也大大减少。在论文中,采用kmeans算法来将权值进行聚类,在每一个类中,所有的权值共享该类的聚类质心,因此最终存储的结果就是一个码书和索引表。
1.对权值聚类
论文中采用kmeans聚类算法,通过优化所有类内元素到聚类中心的差距(within-cluster sum of squares )来确定最终的聚类结果:
式中,W ={w1,w2,…wn}是n个原始权值,C={c1,c2,…ck}是k个聚类。
需要注意的是聚类是在网络训练完毕后做的,因此聚类结果能够最大程度地接近原始网络权值分布。
2. 聚类中心初始化
常用的初始化方式包括3种:
a) 随机初始化。即从原始数据种随机产生k个观察值作为聚类中心。
b) 密度分布初始化。现将累计概率密度CDF的y值分布线性划分,然后根据每个划分点的y值找到与CDF曲线的交点,再找到该交点对应的x轴坐标,将其作为初始聚类中心。
c) 线性初始化。将原始数据的最小值到最大值之间的线性划分作为初始聚类中心。
三种初始化方式的示意图如下所示: 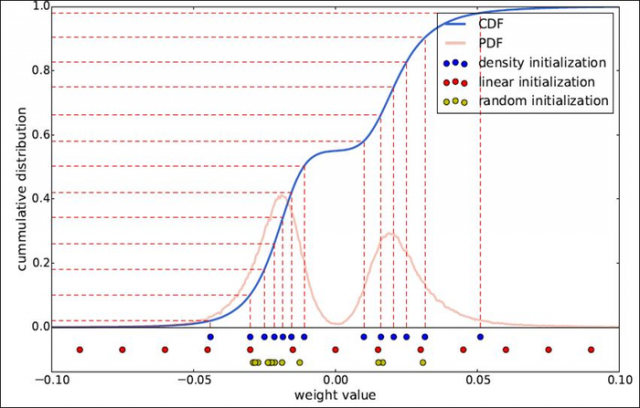
由于大权值比小权值更重要(参加HanSong15年论文),而线性初始化方式则能更好地保留大权值中心,因此文中采用这一方式,后面的实验结果也验证了这个结论。
3. 前向反馈和后项传播
前向时需要将每个权值用其对应的聚类中心代替,后向计算每个类内的权值梯度,然后将其梯度和反传,用来更新聚类中心,如图: 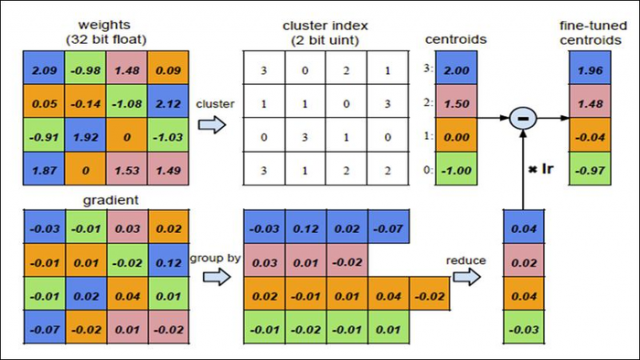
共享权值后,就可以用一个码书和对应的index来表征。假设原始权值用32bit浮点型表示,量化区间为256,即8bit,共有n个权值,量化后需要存储n个8bit索引和256个聚类中心值,则可以计算出压缩率compression ratio:
r = 32*n / (8*n + 256*32 )≈4
可以看出,如果采用8bit编码,则至少能达到4倍压缩率。
Huffman 编码是最后一步,主要用于解决编码长短不一带来的冗余问题。因为在论文中,作者针对卷积层统一采用8bit编码,而全连接层采用5bit,所以采用这种熵编码能够更好地使编码bit均衡,减少冗余。
实验结果就是能在保持精度不变(甚至提高)的前提下,将模型压缩到前所未有的小。直接上图有用数据说话。 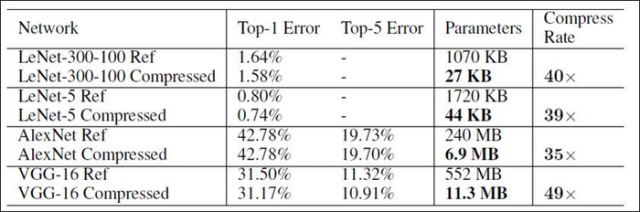
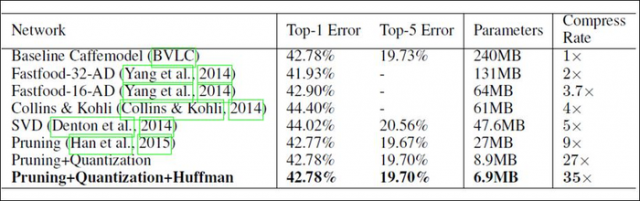
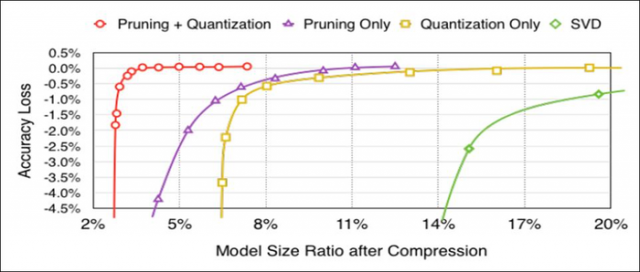
不同模型压缩比和精度的对比,验证了pruning和quantization一块做效果最好。
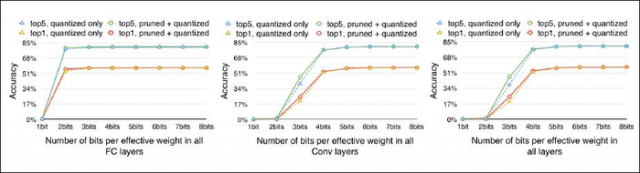
不同压缩bit对精度的影响,同时表明conv层比fc层更敏感, 因此需要更多的bit表示。
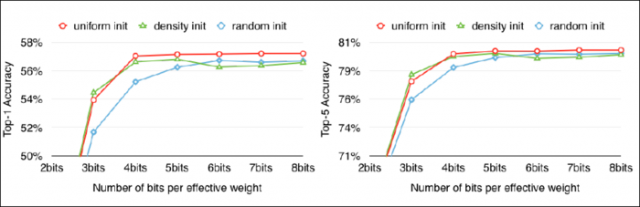
不同初始化方式对精度的影响,线性初始化效果最好。
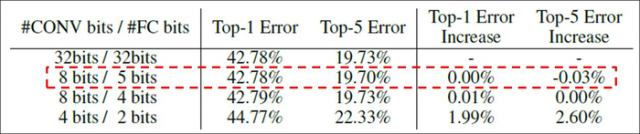
卷积层采用8bit,全连接层采用5bit效果最好。
此部分讲一讲修改caffe源码的过程。其实只要读懂了文章原理,修改起来很容易。
对pruning过程来说,可以定义一个mask来“屏蔽”修剪掉的权值,对于quantization过程来说,需定义一个indice来存储索引号,以及一个centroid结构来存放聚类中心。
在include/caffe/layer.hpp中为Layer类添加以下成员变量: 
以及成员函数: 
由于只对卷积层和全连接层做压缩,因此,只需修改这两个层的对应函数即可。
在include/caffe/layers/base_conv_layer.hpp添加成员函数
这两处定义的函数都是基类的虚函数,不需要具体实现。
在include/caffe/layers/conv_layer.hpp中添加成员函数声明: 
类似的,在include/caffe/layers/inner_product_layer.hpp也添加该函数声明。
在src/caffe/layers/conv_layer.cpp 添加该函数的声明,用于初始化mask和对权值进行聚类。 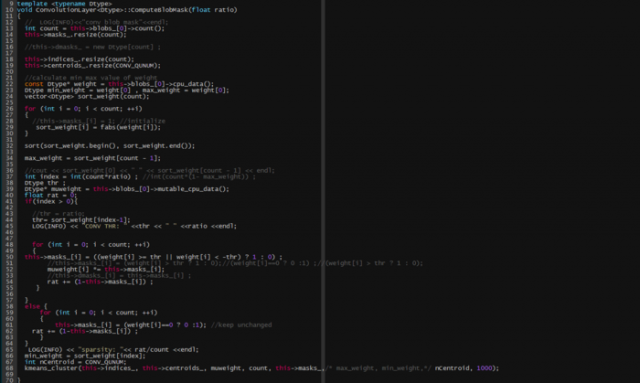
同时,修改前向和后向函数。
在前向函数中,需要将权值用其聚类中心表示,红框部分为添加部分: 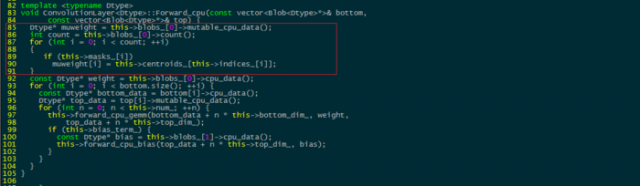
在后向函数中,需要添加两部分,一是对mask为0,即屏蔽掉的权值不再进行更新,即将其weight_diff设为0,另一个则是统计每一类内的梯度差值均值,并将其反传回去,红框内为添加部分。 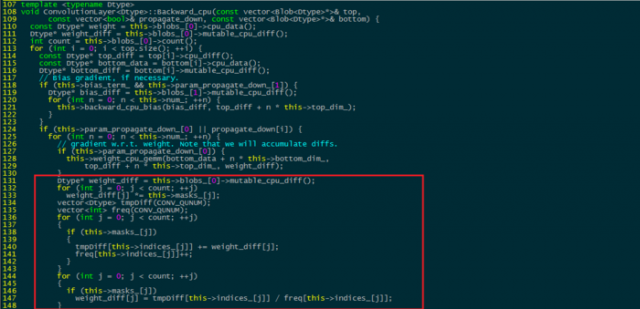

kmeans的实现如下,当然也可以用Opencv自带的,速度会更快些。
<span ><span ><code>template<typename Dtype>
void kmeans_cluster(vector<int> &cLabel, vector<Dtype> &cCentro, Dtype *cWeights, int nWeights, vector<int> &mask, /*Dtype maxWeight, Dtype minWeight,*/ int nCluster, int max_iter /* = 1000 */)
{
//find min max
Dtype maxWeight=numeric_limits<Dtype>::min(), minWeight=numeric_limits<Dtype>::max();
for(int k = 0; k < nWeights; ++k)
{
if(mask[k])
{
if(cWeights[k] > maxWeight)
maxWeight = cWeights[k];
if(cWeights[k] < minWeight)
minWeight = cWeights[k];
}
}
// generate initial centroids linearly
for (int k = 0; k < nCluster; k++)
cCentro[k] = minWeight + (maxWeight - minWeight)*k / (nCluster - 1);
//initialize all label to -1
for (int k = 0; k < nWeights; ++k)
cLabel[k] = -1;
const Dtype float_max = numeric_limits<Dtype>::max();
// initialize
Dtype *cDistance = new Dtype[nWeights];
int *cClusterSize = new int[nCluster];
Dtype *pCentroPos = new Dtype[nCluster];
int *pClusterSize = new int[nCluster];
memset(pClusterSize, 0, sizeof(int)*nCluster);
memset(pCentroPos, 0, sizeof(Dtype)*nCluster);
Dtype *ptrC = new Dtype[nCluster];
int *ptrS = new int[nCluster];
int iter = 0;
//Dtype tk1 = 0.f, tk2 = 0.f, tk3 = 0.f;
double mCurDistance = 0.0;
double mPreDistance = numeric_limits<double>::max();
// clustering
while (iter < max_iter)
{
// check convergence
if (fabs(mPreDistance - mCurDistance) / mPreDistance < 0.01) break;
mPreDistance = mCurDistance;
mCurDistance = 0.0;
// select nearest cluster
for (int n = 0; n < nWeights; n++)
{
if (!mask[n])
continue;
Dtype distance;
Dtype mindistance = float_max;
int clostCluster = -1;
for (int k = 0; k < nCluster; k++)
{
distance = fabs(cWeights[n] - cCentro[k]);
if (distance < mindistance)
{
mindistance = distance;
clostCluster = k;
}
}
cDistance[n] = mindistance;
cLabel[n] = clostCluster;
}
// calc new distance/inertia
for (int n = 0; n < nWeights; n++)
{
if (mask[n])
mCurDistance = mCurDistance + cDistance[n];
}
// generate new centroids
// accumulation(private)
for (int k = 0; k < nCluster; k++)
{
ptrC[k] = 0.f;
ptrS[k] = 0;
}
for (int n = 0; n < nWeights; n++)
{
if (mask[n])
{
ptrC[cLabel[n]] += cWeights[n];
ptrS[cLabel[n]] += 1;
}
}
for (int k = 0; k < nCluster; k++)
{
pCentroPos[ k] = ptrC[k];
pClusterSize[k] = ptrS[k];
}
//reduction(global)
for (int k = 0; k < nCluster; k++)
{
cCentro[k] = pCentroPos[k];
cClusterSize[k] = pClusterSize[k];
cCentro[k] /= cClusterSize[k];
}
iter++;
// cout << "Iteration: " << iter << " Distance: " << mCurDistance << endl;
}
//gather centroids
//#pragma omp parallel for
//for(int n=0; n<nNode; n++)
// cNodes[n] = cCentro[cLabel[n]];
delete[] cDistance;
delete[] cClusterSize;
delete[] pClusterSize;
delete[] pCentroPos;
delete[] ptrC;
delete[] ptrS;
}</code></span></span>连接层的修改和卷积层的一致不再赘述。同样的,可以把对应的.cu文件中的gpu前向和后向函数实现也修改了,方便gpu训练。
最后,在src/caffe/net.cpp的CopyTrainedLayersFrom(const NetParameter& param)函数中调用我们定义的函数,即在读入已经训练好的模型权值时,对每一层做需要的权值mask初始化和权值聚类。 
至此代码修改完毕,编译运行即可。
[1] SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
[2] Deep Compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding
[3] Learning both Weights and Connections for Efficient Neural Networks
[4] Efficient Inference Engine on Compressed Deep Neural Network
最后再提一句,几乎所有的模型压缩文章都是从Alexnet和VGG下手,一是因为他们都采用了多层较大的全连接层,而全连接层的权值甚至占到了总参数的90%以上,所以即便只对全连接层进行“开刀”,压缩效果也是显著的。另一方面,这些论文提出的结果在现在看来并不是state of art的,存在可提升的空间,而且在NIN的文章中表明,全连接层容易引起过拟合,去掉全连接层反而有助于精度提升,所以这么看来压缩模型其实是个不吃力又讨好的活,获得的好处显然是双倍的。但运用到特定的网络中,还需要不断反复试验,因地制宜,寻找适合该网络的压缩方式。
本文链接:http://task.lmcjl.com/news/6023.html


