本章用3年NLP学习经验总结,西欧阿哥毕生心血
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在以序列(sequence)数据为输出,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)
它并⾮刚性地记忆所有固定⻓度的序列,而是通过隐藏状态来存储之前时间步的信息。
为什么有BP神经网络、CNN,还需要RNN?
因为PB,CNN网络(前馈神经网络)的输入输出都是相互独立的(只能正向或者反向传播的,单向的),但是实际应用中的有些场景的输出内容和之前的内容相关的(时序性)
RNN称之为循环神经网络,也称之为递归神经网络(将这一时刻的输出记忆好,传入到下一时刻输入),递归就是指其中每一个元素都是执行相同的任务,但是输出(问题)依赖于输入和“记忆“
我们已经学习了前馈网络的两种结构——bp神经网络和卷积神经网络,这 两种结构有一个特点,就是假设输入(问题)是一个独立的没有上下文联系的单位, 比如输入(问题)是一张图片,网络识别是狗还是猫。但是对于一些有明显的上下 文特征的序列化输入(问题),比如预测视频中下一帧的播放内容,那么很明显这 样的输出必须依赖以前的输入(问题), 也就是说网络必须拥有一定的”记忆能 力”。为了赋予网络这样的记忆力,一种特殊结构的神经网络——递归神经网络 (Recurrent Neural Network) 便应运而生了。
机器翻译、看图说话、智能客服、聊天机器人、语音识别、文本情感分析、个性化推荐等…
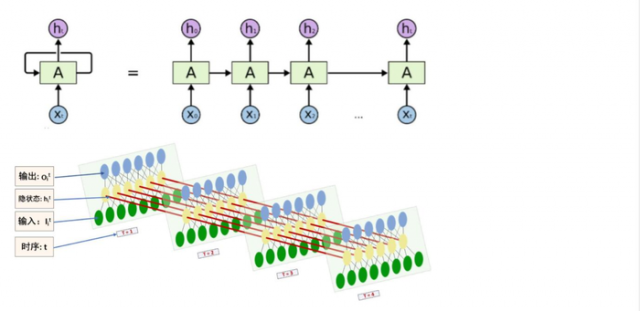
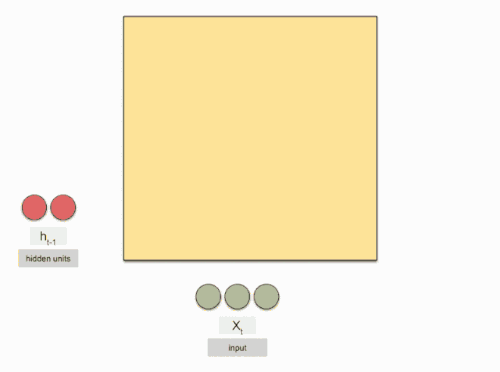
网络某一时刻的输入(问题)x_txt,和之前介绍的bp神经网络的输入(问题)一样,x_txt是一个n 维向量,不同的是递归网络的输入(问题)将是一整个序列,也就是x=[x_1,…,x_{t-1},x_t,x_{t+1},…x_T]x=[x1,…,xt−1,xt,xt+1,…xT],对于语言模型,每一个x_txt将代表一个词向量,一整个序列就代表一句话。 h_tht代表时刻t隐神经元对于线性转换值,s_tst(H_tHt)代表时刻t的隐藏状态 ,o_tot代表时刻t的输出
输入(问题)层到隐藏层直接的权重由U表示
隐藏层到隐藏层的权重W,它是网络的记忆控制者,负责调度记忆。
隐藏层到输出层的权重V
递归神经网络拥有记忆能力,而这种能力就是通过W将以 往的输入(问题)状态进行总结,而作为下次输入(问题)的辅助。可以这样理解隐藏状态:h=f(现有的输入(问题)+过去记忆总结)
普通的神经网络梯度更新如下图: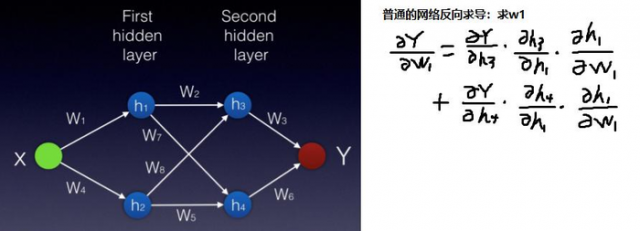
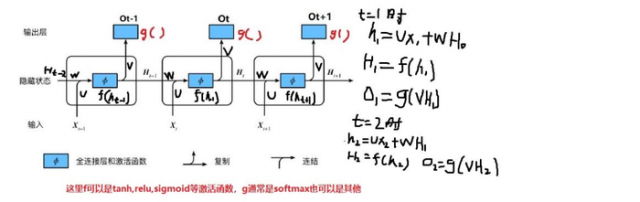
RNN梯度更新如下图:
假设符号E表示误差。在时间t+1(经过两个时间步长),权重矩阵U 如何更新??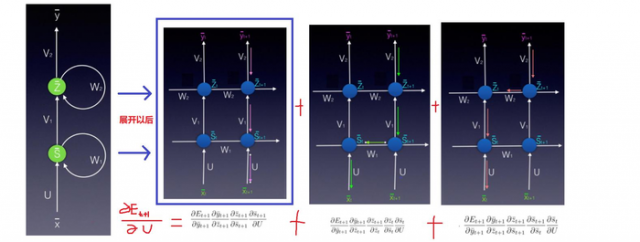
Vanilla-RNN 其实就是最简单的RNN
Vanilla-RNN存在的问题
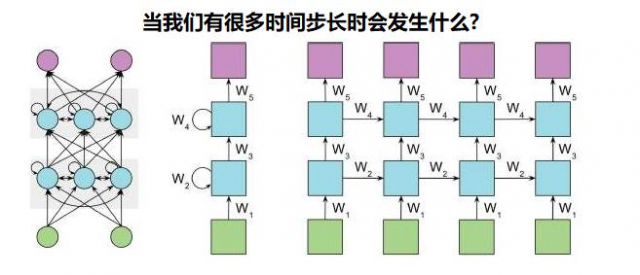
使用基于时间的反向传播算法训练循环神经网络时,我们可以选择小批量进行训练,这里我们定期更新批次权重(而不是每次输入(问题)样本)。 我们计算每一步的梯度,但不要立即更新权重。
另外,我们对权重每次更新固定的步长数量。这样有利于降低训练过程的复杂性,并消除权重更新中的噪音
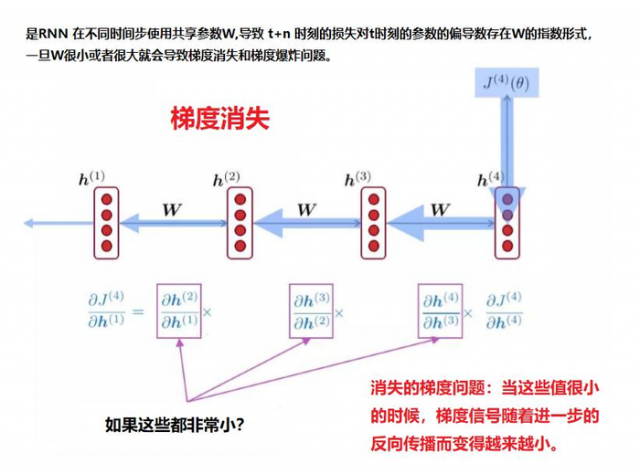
RNN原理就是:传递过程中不断做乘法。连续乘一个小于1的数字,导致该数趋近于0,反之,趋近于无穷大。
如果反向传播超过10个时间步长,梯度会变得非常小。这种现象称为梯度消失问题 在循环神经网络中,我们可能也有相反的问题,称为梯度膨胀问题。
RNN动态图
梯度消失
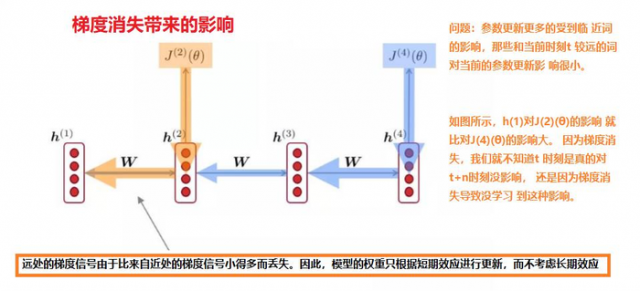
梯度消失带来的影响
如 下 图

梯度爆炸

梯度消失带来的影响

为了克服梯度消失的问题,LSTM和GRU模型便后续被推出了,为什么LSTM和 GRU可以克服梯度消失问题呢?
由于它们都有特殊的方式存储”记忆”,那么以前梯度比较大的”记忆**”不会像简单的RNN一样马上被抹除**,因此可以一定程度上克服梯度消失问题。
另一个简单的技巧可以用来克服梯度爆炸的问题就是gradient clipping(梯度裁剪),
也就是当你计算的梯度超过阈值c的或者小于阈值−c时候,便把此时的梯度设置成c或 −c。
下图所示是RNN的误差平面,可以看到RNN的误差平面要么非常陡峭,要么非 常平坦,如果不采取任何措施,当你的参数在某一次更新之后,刚好碰到陡峭的 地方,此时梯度变得非常大,那么你的参数更新也会非常大,很容易导致震荡问题。而如果你采取了gradient clipping这个技巧,那么即使你不幸碰到陡峭的地 方,梯度也不会爆炸,因为梯度被限制在某个阈值c。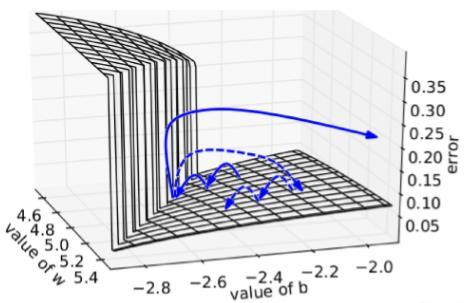
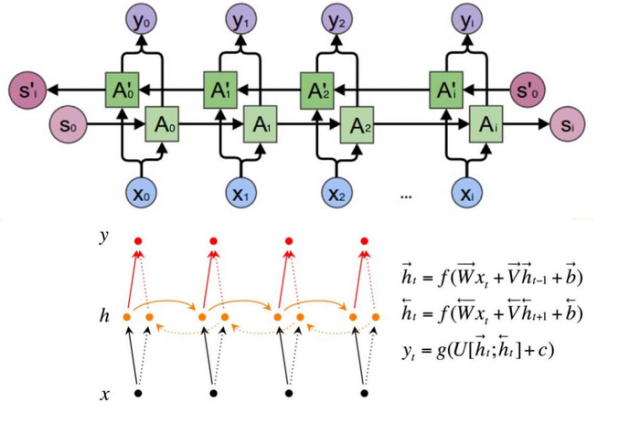
Bidirectional RNN(双向RNN)假设当前t的输出不仅仅和之前的序列有关,并且 还与之后的序列有关
例如:预测一个语句中缺失的词语那么需要根据上下文进 行预测;
Bidirectional RNN是一个相对简单的RNNs,由两个RNNs上下叠加在 一起组成。输出由这两个RNNs的隐藏层的状态决定。
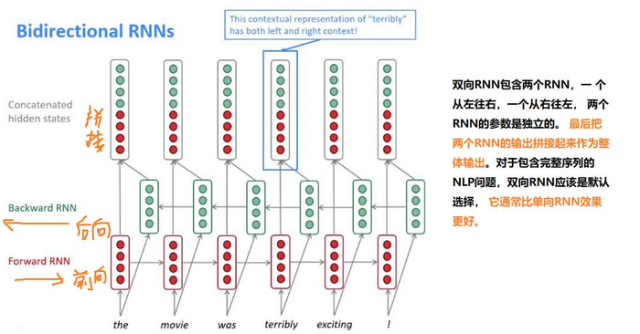
双向RNN中的机制
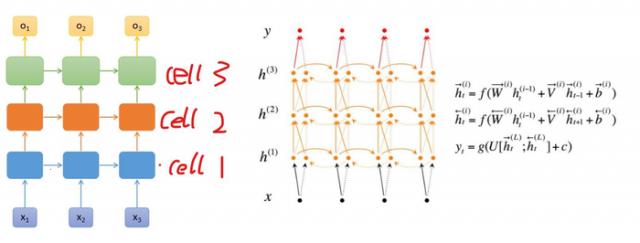
Deep Bidirectional RNN(深度双向RNN)类似Bidirectional RNN,区别在于每个每一步的输入(问题)有多层网络,这样的话该网络便具有更加强大的表达能力 和学习能力,但是复杂性也提高了,同时需要训练更多的数据。
本文链接:http://task.lmcjl.com/news/6025.html


