这部分许多内容要类比CNN来进行理解和解释,所以需要对CNN比较熟悉。
RNN的特点
1. 权值共享
CNN权值共享,RNN也有权值共享,在入门篇可以看到RNN结构图中,权重使用的是同样的字母
为什么要权值共享
a. 减少weight,减少计算量,这点其实比较好理解。
试想10X10的输入,全连接隐藏层如果是1000个神经元,那就有100000个weight要计算;
如果是卷积神经网络,5X5的感受视野,只要25个weight。即使100个卷积核,才2500,不严谨,反正很少就对了。
b. 参考再谈权值共享
为什么可以权值共享
参考CNN疑点解析
需要说明的是共享是同样的传递过程时参数相同,即x-s都是u,同理。
2. 每个输入都只与它本身的那条路线建立连接,不与其他神经元连接。
RNN的计算要素与流程
以标准RNN为例
计算要素

前向与反向
参照 https://www.cnblogs.com/yanshw/p/10478876.html 循环神经网络-极其详细的推到BPTT
参数优化
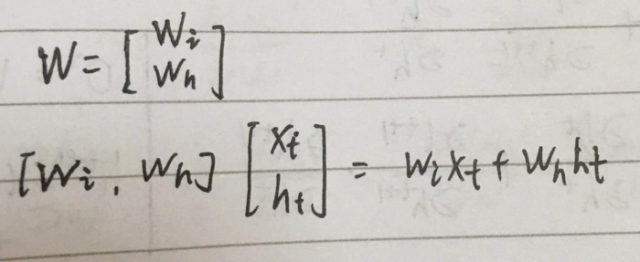
梯度爆炸和梯度消失
RNN在训练过程中容易出现梯度爆炸和梯度消失
所谓梯度爆炸就是在神经网络训练过程中,梯度变得越来越大以使得神经网络权重得到疯狂更新的情形,这种情况很容易发现,因为梯度过大,计算更新得到的参数也会大到崩溃,这时候我们可能看到更新的参数值中有很多的 NaN,这说明梯度爆炸已经使得参数更新出现数值溢出。这便是梯度爆炸的基本情况。
梯度消失。与梯度爆炸相反的是,梯度消失就是在神经网络训练过程中梯度变得越来越小以至于梯度得不到更新的一种情形。当网络加深时,网络深处的误差很难因为梯度的减小很难影响到前层网络的权重更新,一旦权重得不到有效的更新计算,神经网络的训练机制也就失效了。

在BPTT中有 ∏w·f’ 的连乘,所以很容易出现问题。
长期依赖问题
RNN面临的最大挑战就是无法解决长期依赖问题。例如对下面两句话:
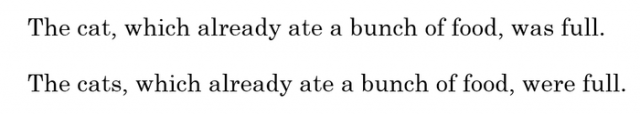
最后的was与were如何选择是和前面的单复数有关系的,但对于简单的RNN来说,两个词相隔比较远,如何判断是单数还是复数就很关键。
长期依赖的根本问题是,经过许多阶段传播后的梯度倾向于消失(大部分情况)或爆炸(很少,但对优化过程影响很大)。
对于梯度爆炸是很好解决的,可以使用梯度修剪(Gradient Clipping),即当梯度向量大于某个阈值,强行缩放梯度向量。但对于梯度消失是很难解决的。
RNN种类
一对一
一对多
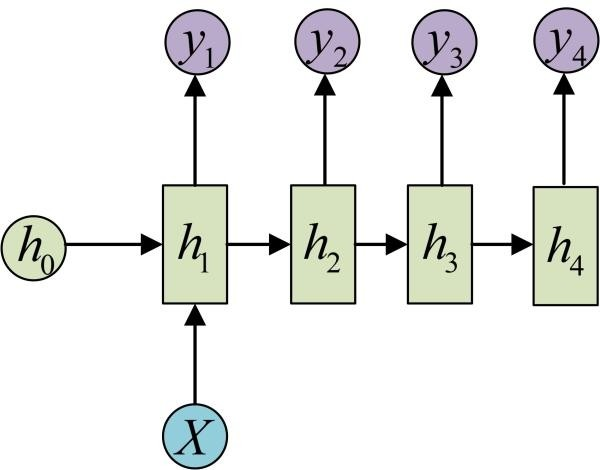
如图片描述,输入一张图片,输出图片的文字描述
多对一
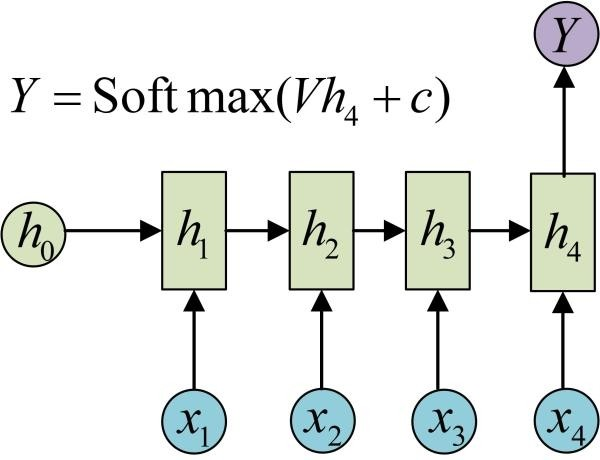
如分类,输入文本,分类积极消极。
多对多1
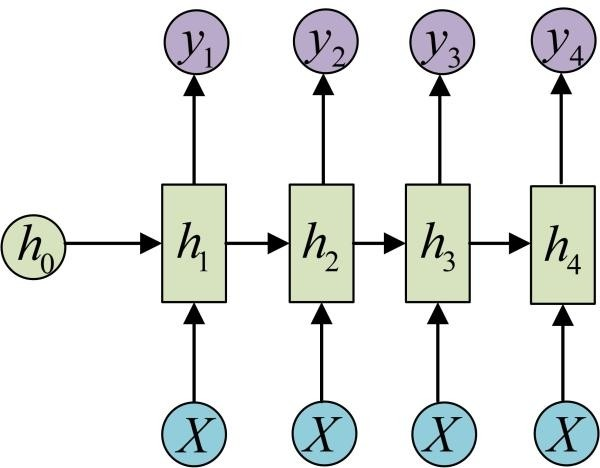
多用于序列标注
多对多2
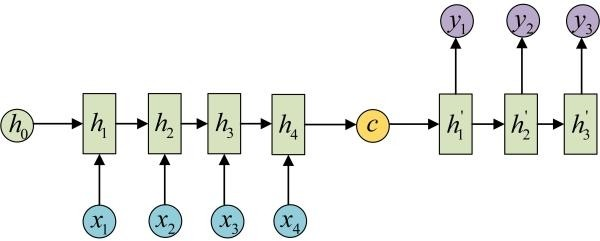
如机器翻译,输入中文,输出英文
RNN的形象描述
RNN模仿了人的记忆功能,它把昨天的记忆传给今天,然后做个总结,把今天的总结又传给明天,这使得它能够记住之前的事情,
但是由于它大脑容量有限,本身智商低,总结能力差,记忆力差,
所以每天都传一些乱七八糟的给第二天,以至于时间长了,之前的很难记得清。
人类之所以有聪明和笨之分,也是因为聪明的人善于总结,每天只记忆精华的东西,而笨的人一股脑全记,其实脑子里是一团浆糊,到真正用时,啥也没记住。
那RNN改进的办法是不是也是每天提炼一下,少记点东西呢?
本文链接:http://task.lmcjl.com/news/6028.html


