1.使用urllib库对网页进行爬取,其中'https://movie.douban.com/cinema/nowplaying/guangzhou/'是豆瓣电影正在上映的电影页面, 定义html_data变量,存放网页html代码,输入 print(html_data)可以查看输出结果。
from urllib import request
resp = request.urlopen('https://movie.douban.com/cinema/nowplaying/guangzhou/')
html_data = resp.read().decode('utf-8')
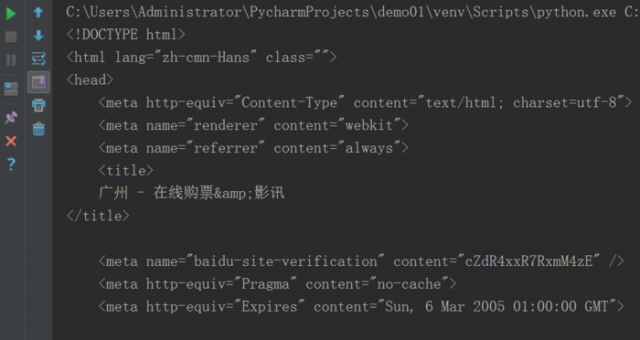
输入print(html_data),其输出结果如下图所示:
2.得到的html代码后,使用BeautifulSoup库进行html代码的解析。获取需要的数据。
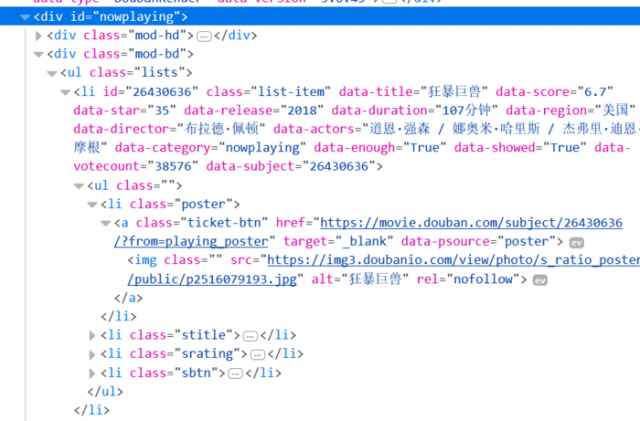
1).获取我们想要色数据。如:“狂暴巨兽”电影的名称、主演、评分等信息。f12查看元素可以获取到div id="nowplaying"标签开始是我们想要的数据。
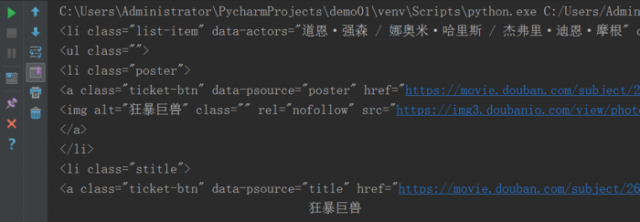
2)代码编写。使用 print(nowplaying_movie_list[0])查看内容。
from bs4 import BeautifulSoup as bs
soup = bs(html_data, 'html.parser')
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')
# print(nowplaying_movie_list[0])
其运行结果如下图所示:
3.电影评论需要电影id及电影名称等信息,因此需要通过python编码爬取电影id及名称。
1).电影id可以通过data-subject属性获取,电影名称可以通过img标签的alt属性获取,可以参照下图:

2).解析电影名称与id,通过print(nowplaying_list)查看结果。
nowplaying_list = []
for item in nowplaying_movie_list:
nowplaying_dict = {}
nowplaying_dict['id'] = item['data-subject']
for tag_img_item in item.find_all('img'):
nowplaying_dict['name'] = tag_img_item['alt']
nowplaying_list.append(nowplaying_dict)
print(nowplaying_list)
其运行结果如下图所示:

4.《狂暴巨兽》的短评网址为: https://movie.douban.com/subject/26430636/comments?start=0&limit=20。其中26430636是电影id,start=0是第0条评论。
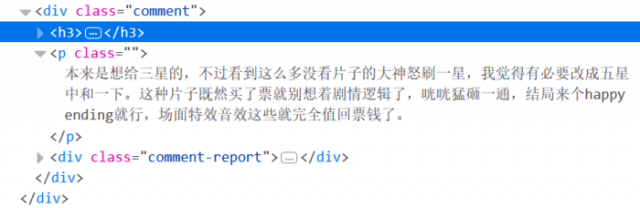
1).短评页面的html代码,其中评论的数据是 div标签的comment属性,如下图所示:
2).对此标签进行解析,代码如下:
requrl = 'https://movie.douban.com/subject/' + nowplaying_list[0]['id'] + '/comments' +'?' +'start=0' + '&limit=20'
resp = request.urlopen(requrl)
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
comment_div_lits = soup.find_all('div', class_='comment')
eachCommentList = [];
for item in comment_div_lits:
if item.find_all('p')[0].string is not None:
eachCommentList.append(item.find_all('p')[0].string)
print(eachCommentList)
其运行结果如下图所示:

5.对获取的短评数据进行处理并清除标点符号、英文等无用信息。使用python中正则表达式的re库实现。
import re filterdata=re.findall(u'[\u4e00-\u9fff]+', comments) cleaned_comments= ''.join(filterdata) print(cleaned_comments)
其运行结果如下图所示:

6.接着进行词频统计,使用结巴分词jieba库进行中文分词操作。可以使用print( words_df.head())查看分词之后的结果。
import jieba #分词包
import pandas
segment = jieba.lcut(cleaned_comments)
words_df=pandas.DataFrame({'segment':segment})
print(words_df.head())
其运行效果如下图所示:
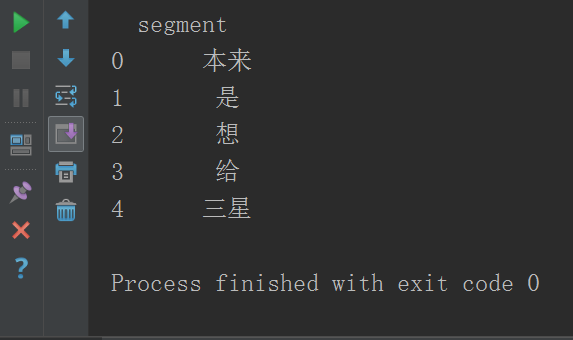
7.进行词频统计,使用numpy计算包。
import numpy #numpy计算包
words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
print(words_stat.head())
其结果如下图所示:
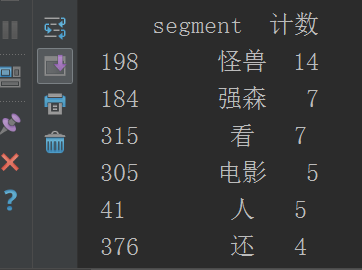
8.对上面爬取的数据进行文本分析,生成词云。
# 生成词云
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import codecs
import numpy as np
from PIL import Image
file = codecs.open('dianying.txt', 'r', 'utf-8')
image=np.array(Image.open('F:/pei.jpg'))
font=r'C:\Windows\Fonts\simkai.ttf'
word=file.read()
print(word)
my_wordcloud = WordCloud(font_path=font,mask=image,background_color='white',max_words = 100,max_font_size = 100,random_state=50).generate(word)
#根据图片生成词云
iamge_colors = ImageColorGenerator(image)
#显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
#保存生成的图片,当关闭图片时才会生效,中断程序不会保存
my_wordcloud.to_file('pei.jpg')
其结果如下图所示:

9.爬取数据的源代码
import re #正则表达式
import jieba #分词包
import pandas
import numpy #numpy计算包
from urllib import request
from bs4 import BeautifulSoup as bs
resp = request.urlopen('https://movie.douban.com/cinema/nowplaying/guangzhou/')
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')
# print(nowplaying_movie_list[0])
nowplaying_list = []
for item in nowplaying_movie_list:
nowplaying_dict = {}
nowplaying_dict['id'] = item['data-subject']
for tag_img_item in item.find_all('img'):
nowplaying_dict['name'] = tag_img_item['alt']
nowplaying_list.append(nowplaying_dict)
# print(nowplaying_list)
requrl = 'https://movie.douban.com/subject/' + nowplaying_list[0]['id'] + '/comments' +'?' +'start=0' + '&limit=20'
resp = request.urlopen(requrl)
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
comment_div_lits = soup.find_all('div', class_='comment')
eachCommentList = [];
for item in comment_div_lits:
if item.find_all('p')[0].string is not None:
eachCommentList.append(item.find_all('p')[0].string)
# print(eachCommentList)
comments = ''
for k in range(len(eachCommentList)):
comments = comments + (str(eachCommentList[k])).strip()
# print(comments)
filterdata=re.findall(u'[\u4e00-\u9fff]+', comments)
cleaned_comments= ''.join(filterdata)
# print(cleaned_comments)
segment = jieba.lcut(cleaned_comments)
words_df=pandas.DataFrame({'segment':segment})
# print(words_df.head())
words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
print(words_stat)
10.总结
通过对豆瓣电影官网中广州站正在上映的《狂暴巨兽》电影的短评的数据爬取实战,一方面巩固了老师课堂上所讲的基础知识,另一方面,增强了自己的实战技能。但是,在此次实践过程中,遇到许多问题,一方面问题是,对python这门语言不熟悉,需要学习。再次就是这次做实验用到了老师一些在课堂上没有涉及到的知识,如:词云,需要查阅与参考资料。最后就是在这一过程中遇到了如下一下问题(如下图所示),最后通过安装wordcloud-1.4.1-cp36-cp36m-win32.whl即可。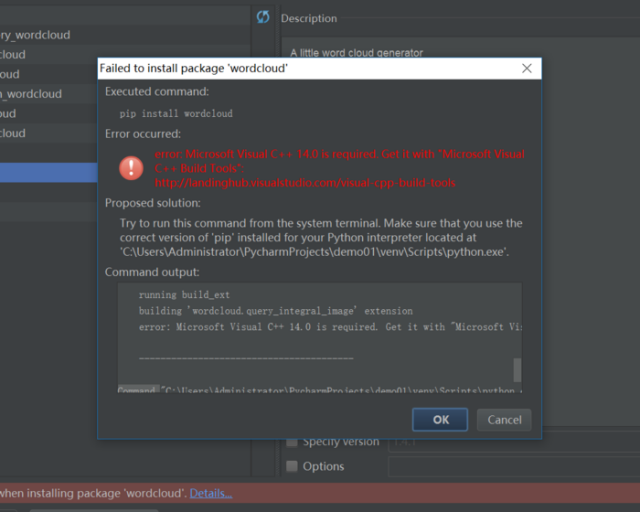
本文链接:http://task.lmcjl.com/news/6547.html


