本节内容为解析库的使用,内容涵盖:XPath、BeautifulSoup和PyQuery基础内容。
· 正则表达来提取比较繁琐。
· 对于网页的节点来说,它可以定义 id、class 或其他的属性,而且节点之间还具有层次关系,在网页中可以通过 XPath 或 CSS 选择器来定位一个或多个节点,进而提取相关内容或属性。
· 解析库包括:LXML、BeautifulSoup、PyQuery
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在XML文档中查找信息的语言。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于 HTML 文档的搜索。
· 常用规则
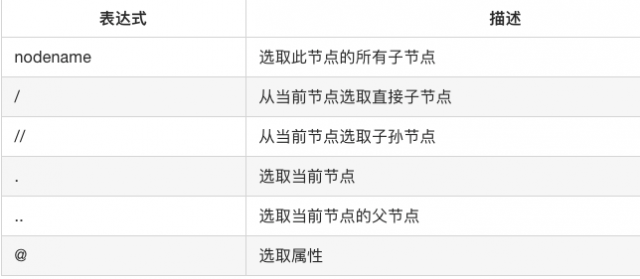
//title[@lang=’eng’] #选择所有名称为 title,同时属性 lang 的值为 eng 的节点。
借助网页的结构和属性等特性来解析网页的工具,能自动转换编码
from bs4 import BeautifulSoup soup = BeautifulSoup('<p>Hello</p>', 'lxml') #对象初始化 print(soup.p.string) #调用方法解析
通过属性选择元素
通用格式:
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print(soup.title.name) print(soup.p.attrs) #获取属性 print(soup.p.attrs['name']) print(soup.p.string) #获取内容
如果返回结果是单个节点,那么可以直接调用 string、attrs 等属性来获得其文本和属性,如果返回结果是多个节点的生成器,则可以转为列表后取出某个元素,然后再调用 string、attrs 等属性来获取其对应节点等文本和属性。
通过调用find_all()、find() 等方法,然后传入相应等参数就可以灵活地进行查询了。
#find_all() API find_all(name , attrs , recursive , text , **kwargs)
select()方法
总结:
推荐使用 LXML 解析库,必要时使用 html.parser。
节点选择筛选功能弱但是速度快。
建议使用 find()、find_all() 查询匹配单个结果或者多个结果。
如果对 CSS 选择器熟悉的话可以使用 select() 选择法。
##本系列内容为《python3爬虫开发实战》学习笔记。本系列博客列表如下:
持续更新...
对应代码请见:..
本文链接:http://task.lmcjl.com/news/6618.html


