python3.9
mysql5.7
目标网址:https://www.gushiwen.cn/
另外,需要什么类,自己pip安装
目录结构:
gushiwen.py文件代码:
import os
from fake_useragent import UserAgent
import requests
from requests import Response
from lxml import etree
import uuid
from Dao import Connection
import time
from csv import DictWriter
conn = Connection()
#首先安装 pip install fake-useragent
ua = UserAgent()
#活的随机ua
headers = {
'User-Agent':ua.random
}
url = 'https://www.gushiwen.cn'
def itempipeline(item):
"""
保存数据
:param item:
:return:
"""
print(item)
#字段字符窜,id ,title,content author
sql = 'insert into gushiwen(%s) values(%s)'
fields = ','.join(item.keys())
value_placeholds = ','.join(['%%(%s)s' % key for key in item])
print(value_placeholds)
pass
with conn as c:
c.execute(sql % (fields,value_placeholds),item)
#写入一个csv文件
# csv_file = open('gushiwen.csv','a')
header_fields = ('id', 'title', 'century', 'author', 'content', 'time')
def itempipeline4csv(item):
has_header = os.path.exists('gushiwen.csv') # 是否第一次写入csv的头
with open('gushiwen.csv','a') as f:
writer = DictWriter(f,fieldnames=header_fields)
if not has_header:
writer.writeheader() # 写入第一行的标题
writer.writerow(item)
def parse(html):
data = {}
root = etree.HTML(html)
divs = root.xpath('//div[@class="main3"]/div[@class="left"]/div[@class="sons"]') #list
for div in divs:
title = div.xpath('.//p[1]/a/b/text()')
if title != []:
data['id'] = uuid.uuid4().hex
data['title'] = ''.join(title)
data['century'] = ''.join(div.xpath('.//p[2]/a[1]/text()'))
data['author'] = ''.join(div.xpath('.//p[2]/a[2]/text()'))
#如果该内容页没数据,则寻找p标签里面的内容
if ''.join(div.xpath('.//div[@class="contson"]/text()')).split() == []:
data['content'] = ''.join(div.xpath('.//div[@class="contson"]/p/text()'))
else:
data['content'] = ''.join(div.xpath('.//div[@class="contson"]/text()'))
data['time'] = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
itempipeline(data) #调用方法插入数据
# itempipeline4csv(data) #调用方法生成csv文件
#获取下一页链接
next_url = url+root.xpath('//*[@]/@href')[0]
get_gushiwen(next_url)
# print(next_url)
#定义函数
def get_gushiwen(url):
res:Response =requests.get(url,headers=headers)
if res.status_code == 200:
parse(res.text)
# for div in divs:
else:
raise Exception('请求失败!')
if __name__ == '__main__':
get_gushiwen(url)
# print(headers)
Dao文件代码:
import pymysql
from pymysql.cursors import DictCursor
class Connection():
def __init__(self):
self.conn = pymysql.Connect(
host='localhost',
port=3306,
user='root',
password='root',
db='test',
charset='utf8'
)
def __enter__(self):
#DictCursor 针对查询结果进行字典话(dict)
return self.conn.cursor(cursor=DictCursor)
def __exit__(self, exc_type, exc_val, exc_tb):
if exc_type:
self.conn.rollback() #回滚事务
#日志收集异常信息,上报给服务器
else:
self.conn.commit() #提交事务
#关闭数据库
def close(self):
try:
self.conn.close()
except:
pass
运行如图:
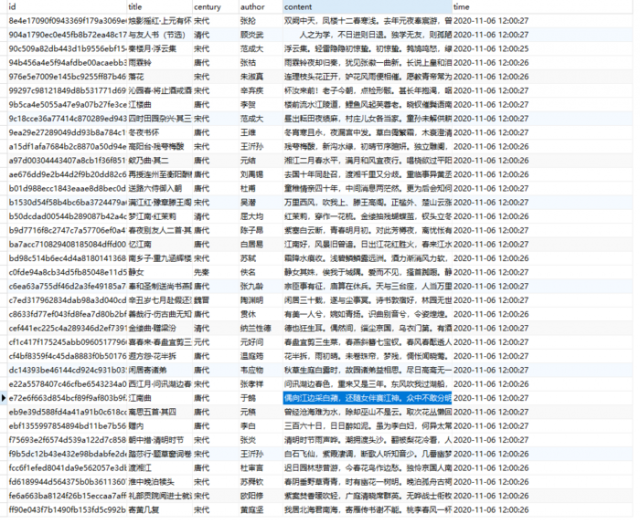
本博客仅做学习交流,不负任何法律责任
本文链接:http://task.lmcjl.com/news/6628.html


