就在昨天 2023 年 11 月 6 日,OpenAI 举行了首个开发者大会 DevDay,即使作为目前大语言模型行业的领军者,OpenAI 卷起来可一点都不比同行差。
OpenAI 在大会上不仅公布了新的 GPT-4 Turbo 模型,还推出了几项从业务角度看可能冲击其他 AI 公司市场份额的服务,并对现有功能进行了升级和融合,基本上很多做着类似功能的第三方项目和公司都能感受到来自 OpenAI 的威胁。
接下来我就给大家总结一下这次 OpenAI 开发者大会的主要内容,每项内容还会根据我自己的经验给大家进行一些简单的解读。
首先,大会最重磅的内容自然是发布新的模型 GPT-4 Turbo。不同于 GPT-3.5 到 GPT-4 更新换代般的升级,OpenAI 最近专注于打磨现有的功能,GPT-4 Turbo 的主要更新还是将之前截止 2022 年的知识库更新到现在的 2023 年 4 月,以及支持最大 128K Token 的输入。


按照 OpenAI 的说法,现在的 GPT-4 Turbo 不仅更新了知识库,而且最高支持 300 页文档作为输入,是之前 8K Token 限制的 16 倍,而且超长文档输入内容处理的准确性也会比前辈有所提高。之前各类大语言模型最热门的第三方项目就是花式处理超长文档类的应用服务,甚至另一个热门大模型 Claude2.0 最大的卖点就是能够输入 100K Token 的超长文档。
GPT-4 能够处理更长内容的 Advanced Data Analysis(高级数据分析,效果可以查看我之前的文章)功能推出后,这些项目已经明显受到影响,现在 GPT-4 Turbo 一出,这些模型和项目剩下能够与其竞争的点就只剩下更低的价格或者直接免费了。
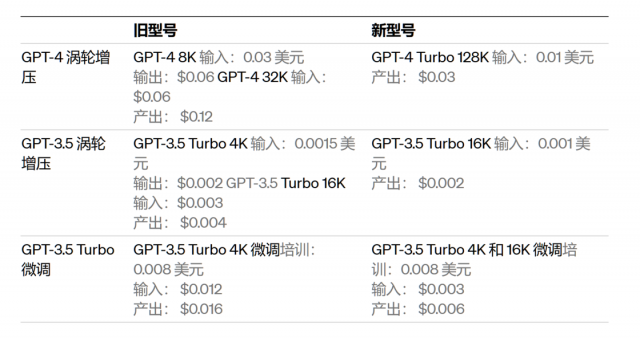
除此以外,GPT-4 Turbo 性能和处理速度比起前辈也有所提升,所以 OpenAI 也放宽了每分钟输入和输出的 Token 限制,由于性能的提升 API 调用价格也随之下降,输入和输出价格分别只有之前的 1/3 和 1/2(包括即将推出的 gpt-4-1106-preview 模型),虽然比起 GPT-3.5 还是要贵上不少,但对于必须调用的商业项目或者第三方项目来讲还是一个很大的利好,毕竟 GPT-4 的效果比起 GPT-3.5 要好上太多。


另外这次 GPT-4 Turbo 模型还有一个值得关注的新特性,那就是在一定时间之内可以实现可重现输出 —— 也就是相同的问题每次都会得到一模一样的答案。
之前阻碍很多人把 GPT 真正用于自己的工作或者项目里面的一大因素就是它随心所欲的输出,即使是相同的问题,每次都有可能得到不同的答案,不同的格式也很难将 GPT 融入到工作流程或者程序里面,现在 GPT-4 Turbo 有了一定程度的复现能力(虽然目前还是 Beta 中的 Beta),还能返回某段时间内不同生成内容的概率,这个特性对于商业用户开发人员来讲要比其他更新来的更加实用。
最后是一个用户体验上的改进,也能极大增加 ChatGPT 的能力,那就是将目前分开的功能融合在一起。目前 GPT-4 有高级数据分析、联网搜索、AI 画图和插件等功能,但是用户每次只能选择其中的一个,不同功能之间也无法互相调用。
现在 OpenAI 宣布即将把这些功能都整合到一起,用户只需要在使用的时候用自然语言说出自己想要调用的功能,或者直接说出自己的需求,ChatGPT 就会根据需求或者在合适的时候自动调用对应的功能,这极大拓宽了用户使用 ChatGPT 的使用场景和灵活度,像是之前没有办法实现的「搜索信息然后生成图片」或者「在代码解释器中的库能够联网」等需求现在都可以轻松实现。
JSON 是一种特定格式表示的数据结构,用来方便开发者和程序传递与处理数据,形式如 {"项目 A 的名称": "项目 A 的内容", "项目 B 的名称": "项目 B 的内容"}
对于想要用 GPT 进行正儿八经项目和需求的公司和个人,这次 OpenAI 宣布的更新也是十分实用。首先新模型在必须遵守指令的任务上表现会更好更稳定,比如能够比之前输出更加固定的指定内容(如 JSON 和特殊排版),接着 OpenAI 还在 API 调用的参数上添加了新的 JSON 模式,能够保证 GPT 始终会按要求返回格式正确的 JSON,这让更多用户能够更放心地选择使用 GPT 执行任务,也不用每次都在 Prompt 里面反复提醒 GPT 一定要返回 JSON 格式了。JSON 模式在 GPT-4 和 GPT-3.5 上都可以启用(包括未来发布的 1106 版本模型)。

另外 OpenAI 在另一个常见的大语言模型与项目结合方式 —— Function Calling 上也做出了优化,Function Calling 函数调用可以让用户把自己项目上的功能和特性「介绍」给 GPT,接着 GPT 就能在合适的时机调用这些功能并从用户自己的项目上获取到返回信息。
目前 GPT-4 的插件商店里面的插件就是使用这个特性。本次 GPT-4 Turbo 不仅优化了准确性,提高调用函数的正确率以及调用时机的正确率,而且能够在一次对话中同时调用多个函数(目前每次只能调用一个),这极大节省了每次运行的时间和资源。之后即使普通用户也能感受到调用插件时明显更快错误率更低。

这两个功能更新明显是面向更加专业的用户,让 GPT 在第三方项目和商业产品上表现更好更稳定,这样也能极大提升普通用户和公司在自己的项目里面使用大语言模型的动力,顺便把第三方的工具框架干掉(微软:???)。
OpenAI 给专业用户和商业公司的惊喜还不止这些,这次发布会还发布了一卡车的工具,一个新的 Assistants API 以及微调模型的权限来帮助有更高需求的用户和公司打造专属于它们的模型。
首先是现在使用 Assistants API 能够调用 GPT 上几乎所有的新功能,Assistants API 本身就是一个特别训练的 AI,可以让你用自然语言调用包括高级数据分析、函数调用、AI 画图、图片识别、语音生成和插件等等几乎所有 OpenAI 目前能够提供的功能。
用户还可以调用 Assistants API 直接来检索自己的数据库和文档库,甚至不需要将数据库和文档库矢量化就可以将自己的数据转化为 GPT 的知识库。当然,OpenAI 反复强调所有的用户数据都不会用于训练自己的模型,并且会定时删除。这项功能不用等,现在你就可以直接进入 OpenAI Assistants Playground 进行试用。

OpenAI 还宣布会制作一个新的微调界面,让开发者可以微调 GPT-3.5 甚至 GPT-4 模型。另外大佬公司们如果有特别大的项目(几十亿 Token 以上)OpenAI 也不介意多赚点钱,针对金主的特定领域和需求训练定制的 GPT-4,包括修改模型训练过程的每个步骤,从执行额外的特定领域预训练,到运行为特定领域量身定制的自定义 RL 后训练过程。
客户将拥有对其自定义模型的独占访问权限。根据 OpenAI 现有的企业隐私政策,自定义模型不会提供给其他客户或与其他客户共享,也不会用于训练其他模型,提供给 OpenAI 用于训练自定义模型的专有数据也不会在任何其他对话中重复使用。

按照 OpenAI 的说法,这个功能只会开放给很有限的公司和组织,而且非常昂贵。低情商说法就是不是真正的富哥和大佬就不要点这个申请链接。
当然,普通用户也可以在某种程度上定制模型。OpenAI 在现有插件开发的基础上升级为 GPTs,插件商店也会升级为像是苹果应用商店一样的平台。
用户可以使用自然语言对 GPT 进行编程,给 GPT 指定一个特定的指令,或者特殊的知识,以及像是上面函数调用类似的与自己项目或者第三方服务结合的能力,这些编程是在模型之上的额外数据,所以不会像上面微调甚至定制模型那样深入。
好处是上手难度同样很低,加上 GPT 用自然语言就可以进行编程,OpenAI 还提供了专门负责创建插件的 AI 让用户使用自然语言创建自定义 GPT。未来可以想象每个用户都可以拥有一个专属于自己的 GPT,甚至能像是现在 Steam 创意工坊和虚幻引擎商店一样成为一个新产业。

为了让用户和公司更加放心使用生成型人工智能产品,Google、Microsoft、Amazon 和 Adobe 这些拥有 AI 服务的大厂,都相继宣布为「陷入人工智能生成产品纠纷」的客户提供法律援助和相关费用报销。
虽然各家政策背后都有不少的条件和限制,比如:必须是企业用户、用途必须「商业上合理」、还有必须是大厂认为合理的情况下等等,但这已经成为一个趋势。
作为 AI 领域最大的大厂,OpenAI 现在也宣布跟进这个政策,推出 Copyright Shield—— 如果用户面临有关版权侵权的法律索赔,OpenAI 现在将介入保护客户并支付由此产生的费用,当然条件是仅适用于 ChatGPT Enterprise 和开发人员平台的正式发布功能。

现在 GPT-4 很多惊艳的功能都是只能在官方网页版或者客户端中体验,现在 OpenAI 给它们都做了对应的 API,包括视觉识别 GPT-4 Turbo With Vision,DALL·E 3 AI 画图以及谁听谁震惊的下一代语音合成框架 TTS。

虽然目前这些 API 还要付费,价格比起同类产品往往也要贵一点。但也能看出 OpenAI 横扫 AI 领域的野望,而且目前看来它也有这个能力,这些功能绝大部分都比肩同类最好的产品,甚至视觉识别和语音合成这两方面在我体验后可以称之为「次世代」。
我认为不考虑价格的话,很可能其他产品甚至连和它对比的意义都没有。我强烈建议大家自己亲自体验一次,特别是语音合成效果特别惊艳,各种功能的体验也可以查看我之前的文章。


另外 OpenAI 还在不断进步,不仅要推出下一代的语音识别框架 WhisperV3,而且 DALL·E 3 还即将采用和 Stable Diffusion 一致的解释器 —— 这意味着两家的模型能够通用。这些 API 的提供和改进基本上能够影响到 AI 行业的每一家公司,这也是好事,更强更激烈的竞争最终还是能够带来更快的进步,以及对消费者来讲更高的性价比。

以上就是 OpenAI 在首次开发者大会上发布的主要内容了,这次推出的所有更新和新功能基本上都在推进 GPT 在聊天以外的实际应用,并且以 GPT 为核心,打造更加丰富的生态和能力。可以看出 OpenAI 是非常想成为不仅是大语言模型,而是 AI 领域的 Top1,也非常想让 GPT 真正融入到这个领域的实际项目里,而不是只能作为一个聊天机器人。
AI 目前已经过了夺人眼球的阶段,现在 OpenAI 走在一条非常正确的道路上,放弃追求每代都必须有巨大提升,而是专注于让 GPT 更加可用,更加实用,更多能用,满足更多人的需求,让更多人真正能利用 AI 帮到自己,提升自己,才能在未来将人工智能变成如水电网般自然的基础设施。
本文链接:http://task.lmcjl.com/news/697.html


