在数学中,数字有正负之分。在C语言中也是一样,short、int、long 都可以带上正负号,例如:
//负数
short a1 = -10;
short a2 = -0x2dc9; //十六进制
//正数
int b1 = +10;
int b2 = +0174; //八进制
int b3 = 22910;
//负数和正数相加
long c = (-9) + (+12);
如果不带正负号,默认就是正数。
符号也是数字的一部分,也要在内存中体现出来。符号只有正负两种情况,用1位(Bit)就足以表示;
C语言规定,把内存的最高位作为符号位。以 int 为例,它占用 32 位的内存,0~30 位表示数值,31 位表示正负号。如下图所示:
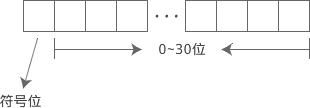 C语言规定,在符号位中,用 0 表示正数,用 1 表示负数。
C语言规定,在符号位中,用 0 表示正数,用 1 表示负数。例如 int 类型的 -10 和 +16 在内存中的表示如下:
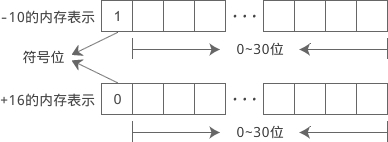
short、int 和 long 类型默认都是带符号位的,符号位以外的内存才是数值位。如果只考虑正数,那么各种类型能表示的数值范围(取值范围)就比原来小了一半。
但是在很多情况下,我们非常确定某个数字只能是正数,比如班级学生的人数、字符串的长度、内存地址等,这个时候符号位就是多余的了,就不如删掉符号位,把所有的位都用来存储数值,这样能表示的数值范围更大(大一倍)。
C语言允许我们这样做,如果不希望设置符号位,可以在数据类型前面加上
unsigned 关键字,例如:
unsigned short a = 12;
unsigned int b = 1002;
unsigned long c = 9892320;
这样,short、int、long 中就没有符号位了,所有的位都用来表示数值,正数的取值范围更大了。这也意味着,使用了 unsigned 后只能表示正数,不能再表示负数了。
如果将一个数字分为符号和数值两部分,那么不加 unsigned 的数字称为
有符号数,能表示正数和负数,加了 unsigned 的数字称为
无符号数,只能表示正数。
请读者注意一个小细节,如果是
unsigned int类型,那么可以省略 int ,只写 unsigned,例如:
unsigned n = 100;
它等价于:
unsigned int n = 100;
无符号数的输出
无符号数可以以八进制、十进制和十六进制的形式输出,它们对应的格式控制符分别为:
|
|
unsigned short |
unsigned int |
unsigned long |
|
八进制 |
%ho |
%o |
%lo |
|
十进制 |
%hu |
%u |
%lu |
|
十六进制 |
%hx 或者 %hX |
%x 或者 %X |
%lx 或者 %lX |
上节我们也讲到了不同进制形式的输出,但是上节我们还没有讲到正负数,所以也没有关心这一点,只是“笼统”地介绍了一遍。现在本节已经讲到了正负数,那我们就再深入地说一下。
严格来说,格式控制符和整数的符号是紧密相关的,具体就是:
-
%d 以十进制形式输出有符号数;
-
%u 以十进制形式输出无符号数;
-
%o 以八进制形式输出无符号数;
-
%x 以十六进制形式输出无符号数。
那么,如何以八进制和十六进制形式输出有符号数呢?很遗憾,printf 并不支持,也没有对应的格式控制符。在实际开发中,也基本没有“输出负的八进制数或者十六进制数”这样的需求,我想可能正是因为这一点,printf 才没有提供对应的格式控制符。
下表全面地总结了不同类型的整数,以不同进制的形式输出时对应的格式控制符(
--表示没有对应的格式控制符)。
|
|
short |
int |
long |
unsigned short |
unsigned int |
unsigned long |
|
八进制 |
-- |
-- |
-- |
%ho |
%o |
%lo |
|
十进制 |
%hd |
%d |
%ld |
%hu |
%u |
%lu |
|
十六进制 |
-- |
-- |
-- |
%hx 或者 %hX |
%x 或者 %X |
%lx 或者 %lX |
有读者可能会问,上节我们也使用 %o 和 %x 来输出有符号数了,为什么没有发生错误呢?这是因为:
-
当以有符号数的形式输出时,printf 会读取数字所占用的内存,并把最高位作为符号位,把剩下的内存作为数值位;
-
当以无符号数的形式输出时,printf 也会读取数字所占用的内存,并把所有的内存都作为数值位对待。
对于一个有符号的正数,它的符号位是 0,当按照无符号数的形式读取时,符号位就变成了数值位,但是该位恰好是 0 而不是 1,所以对数值不会产生影响,这就好比在一个数字前面加 0,有多少个 0 都不会影响数字的值。
如果对一个有符号的负数使用 %o 或者 %x 输出,那么结果就会大相径庭,读者可以亲试。
可以说,“有符号正数的最高位是 0”这个巧合才使得 %o 和 %x 输出有符号数时不会出错。
再次强调,不管是以 %o、%u、%x 输出有符号数,还是以 %d 输出无符号数,编译器都不会报错,只是对内存的解释不同了。%o、%d、%u、%x 这些格式控制符不会关心数字在定义时到底是有符号的还是无符号的:
-
你让我输出无符号数,那我在读取内存时就不区分符号位和数值位了,我会把所有的内存都看做数值位;
-
你让我输出有符号数,那我在读取内存时会把最高位作为符号位,把剩下的内存作为数值位。
说得再直接一些,我管你在定义时是有符号数还是无符号数呢,我只关心内存,有符号数也可以按照无符号数输出,无符号数也可以按照有符号数输出,至于输出结果对不对,那我就不管了,你自己承担风险。
下面的代码进行了全面的演示:
#include <stdio.h>
int main()
{
short a = 0100; //八进制
int b = -0x1; //十六进制
long c = 720; //十进制
unsigned short m = 0xffff; //十六进制
unsigned int n = 0x80000000; //十六进制
unsigned long p = 100; //十进制
//以无符号的形式输出有符号数
printf("a=%#ho, b=%#x, c=%ld\n", a, b, c);
//以有符号数的形式输出无符号类型(只能以十进制形式输出)
printf("m=%hd, n=%d, p=%ld\n", m, n, p);
return 0;
}
运行结果:
a=0100, b=0xffffffff, c=720
m=-1, n=-2147483648, p=100
对于绝大多数初学者来说,b、m、n 的输出结果看起来非常奇怪,甚至不能理解。按照一般的推理,b、m、n 这三个整数在内存中的存储形式分别是:

当以 %x 输出 b 时,结果应该是 0x80000001;当以 %hd、%d 输出 m、n 时,结果应该分别是 -7fff、-0。但是实际的输出结果和我们推理的结果却大相径庭,这是为什么呢?
其实这跟整数在内存中的存储形式以及读取方式有关。b 是一个有符号的负数,它在内存中并不是像上图演示的那样存储,而是要经过一定的转换才能写入内存;m、n 的内存虽然没有错误,但是当以 %d 输出时,并不是原样输出,而是有一个逆向的转换过程(和存储时的转换过程恰好相反)。
也就是说,整数在写入内存之前可能会发生转换,在读取时也可能会发生转换,而我们没有考虑这种转换,所以才会导致推理错误。那么,整数在写入内存前,以及在读取时究竟发生了怎样的转换呢?为什么会发生这种转换呢?我们将在《
整数在内存中是如何存储的,为什么它堪称天才般的设计》一节中揭开谜底。
本文链接:http://task.lmcjl.com/news/7995.html


