这篇文章的作者是广州大学的范立生老师和他的学生汤舜璞,于2022年10月发表在 IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY。
文献提出了一种基于空洞卷积(Dilated Convolution)的CSI反馈网络,即空洞信道重建网络(Dilated Channel Reconstruction Network, DCRNet)。还设计了编码器和解码器块,提高了重建性能并降低计算复杂度。
在下行MIMO系统中,利用信道状态信息(CSI)是BS完成预编码设计的前提。在时分双工(TDD)模式下,由于信道的互易性,BS可以直接获得下行链路的CSI。然而在频分双工(FDD)模式下,因为BS由于弱互易而难以获得CSI信息,下行链路的CSI必须由UE来估计。但在大规模MIMO系统中,反馈CSI矩阵的开销随着天线数量的增加而增加,也受到用户的发射功率和上行带宽的限制。因此,需要对反馈CSI进行压缩。
传统基于CS的方法如LASSO和BM3D-AMP算法等存在一些局限性,如假设CSI是理想稀疏的,在随机工程中忽略了信道统计,迭代处理导致了较大的延迟等。
基于深度学习的方法如CsiNet等,优于传统的基于CS的算法,而且可以有效地减小网络参数。这类算法的主要限制是网络架构不能提供足够的感受野(receptive field, RecF)*,表明深层神经元不能表示原始输入的足够区域。为了克服这种限制,一些论文提出了设计更大的RecF以增加卷积大小来提高CSI重建性能,代价是增加网络的复杂度。因此,设计一种轻量级的网络架构,在较低计算复杂度下提高RecF的同时,又能保持CSI重构的性能,是非常重要的。
文章的主要贡献有:
*感受野:CNN中每一层输出的特征图上的像素点映射回输入图像上的区域大小。通俗点的解释是,特征图上一点,相对于原图的大小,也是卷积神经网络特征所能看到输入图像的区域。
考虑频分双工MIMO下行链路,在BS上有\(Nt>>1\)根天线,在每个UE上有1根天线,在OFDM中有\({N}_{\mathrm{c}}\)个子载波,第n个子载波的复值接收信号为:
\[y_n={\mathbf{h}}_n^H \mathbf{b}_n x_n+z_n,
\]
\({\mathbf{h}}_n \in \mathbb{C}^{N_{\mathrm{t}} \times 1}, (·)^H,\mathbf{b}_n \in \mathbb{C}^{N_{\mathrm{t}} \times 1}, x_n \in \mathbb{C} \text {, 和 } z_n \in \mathbb{C}\)分别表示第\(n\)个子载波上的信道增益向量、共轭转置、波束成形向量、发射信号和加性高斯白噪声(AWGN)。所有子载波的CSI可表示为矩阵\({\mathbf{H}}=\left[{\mathbf{h}}_1, {\mathbf{h}}_2, \ldots, {\mathbf{h}}_{{N}_c}\right] \in \mathbb{C}^{N_t \times {N}_c}\),其中共有\(2N_cN_t\)个元素。
BS的波束形成和预编码设计需要CSI矩阵H的反馈,但MIMO的天线数量导致巨大的开销。为了解决这个问题,需要将CSI矩阵H压缩后再反馈给BS,CSI反馈模型如图1所示。
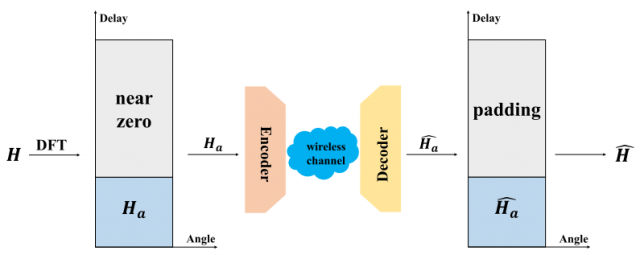
CSI矩阵H首先通过离散傅里叶变换(DFT)从空间域和频域变换到角域和延迟域,即:
\[\tilde{H}=F_cHF_t^H,
\]
其中,\(F_c,F_t\)分别为\(Nc × Nc\)和$Nt × Nt \(的DFT变换矩阵。由于多径到达有延迟区间,矩阵\)\tilde{H}\(在角延迟域中是稀疏的,它可以分为两部分,一部分是\)H_a\(,其中有\)N_a\(行由非零元素组成(\)N_a < N_c\(),另一部分其余\)N_c−N_a\(行由近零元素组成。把信道矩阵\)H\(压缩为\)H_a$,而且信息损失可以忽略不计。
为了进一步压缩CSI矩阵,还要应用基于深度学习的自编码压缩和恢复模块,如图1所示,通过编码器压缩CSI矩阵输出较小的码字向量:
\[\begin{align*} \boldsymbol{v}=\mathcal {E}(\theta _{1},\boldsymbol{H}_{\boldsymbol{a}}), \tag{3} \end{align*}
\]
其中,\(\mathcal {E}(·)\)代表压缩操作,\(\theta_1\)代表编码器的参数。压缩后的CSI矩阵通过专用的信道反馈给BS,然后BS通过解码器恢复CSI矩阵:
\[\begin{align*} \hat{\boldsymbol{H}}_{\boldsymbol{a}}=\mathcal {D}(\theta _{2},\boldsymbol{v}), \tag{4} \end{align*}
\]
其中,\(\mathcal {D}(·)\)代表压缩操作,\(\theta_2\)代表解码器的参数。CSI反馈的目的是为了最小化平均重构误差:
\[\begin{align*} \min _{(\theta _{1},\theta _{2})} \mathbb {E}||\boldsymbol{H}_{\boldsymbol{a}}-\hat{\boldsymbol{H}}_{\boldsymbol{a}}||_{2}, \tag{5} \end{align*}
\]
基于卷积神经网络的自编码器可以有效地提取CSI矩阵的空间局部相关性,基于空洞卷积的DCRNet结构如图2所示。
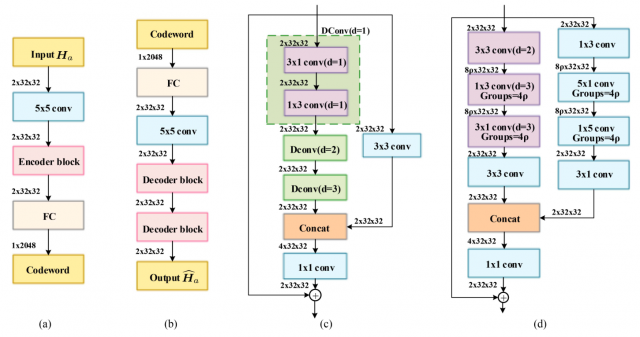
在(a)编码器中,输入\(H_a\)的维度为\(2×N_a×N_t\),两个独立的通道分别代表CSI矩阵的实部和虚部,首先使用5×5的头卷积来提取和融合CSI矩阵实部和虚部的特征信息;然后通过一个编码块来提取深度的抽象信息,与ACRNet不同,为了减少复杂度, DCRNet 中的编码器只需要一个单元就可以得到17 × 17的 RecF,只比ACRNet中RecF的小一点;随后利用全连接层来把\(2×N_a×N_t\)的矩阵压缩成一维的码字向量,压缩比\(\mathcal {η}∈(0,1)\);最后码字通过无线信道传输到BS的解码器。
在(b)解码器中,输入码字经过全连接层进行重塑操作;随后5×5的头卷积用来增强信道恢复性能;之后两个空洞卷积解压块来恢复压缩的信息。其中批归一化和参数整流线性单元(parametric rectified linear unit,PReLU)激活函数应用到每一层卷积之中,带有可学习参数\(α\)的PReLU为:
\[\begin{align*} \text{PReLU}(x)=\left\lbrace \begin{array}{ll}x, & x \geq 0 \\ \alpha x, & x< 0. \end{array}\right. \tag{6} \end{align*}
\]
与传统卷积不同,空洞卷积带有特定的间隔\(d\),也称作空洞率。二维空洞卷积运算可以写作:
\[\begin{align*} (\boldsymbol{I}\circledast \boldsymbol{K})[i,j]=\sum _{u}\sum _{v} {\boldsymbol{I}[i+du,j+dv]\cdot \boldsymbol{K}[u,v]}, \tag{7} \end{align*}
\]
其中\(\circledast,\boldsymbol{I},\boldsymbol{K}\)分别表示空洞卷积操作、二维输入和卷积核,\(u,v\)为卷积核\(\boldsymbol{K}\)的指数,空洞率为\(d\)的空洞卷积有效卷积核大小表示为:
\[\begin{align*} k_{i}^{\prime }=k_{i}+(k_{i}-1)(d-1), \tag{8} \end{align*}
\]
其中\(k_i,{k^{'}}_i\)为当前使用的卷积核大小和有效的卷积核大小。图3展示了空洞率不同的空洞卷积,在同样的卷积核大小下,当\(d>1\)时,空洞卷积比普通卷积能够提供更大的感受野,可以实现块稀疏CSI矩阵的稀疏采样。
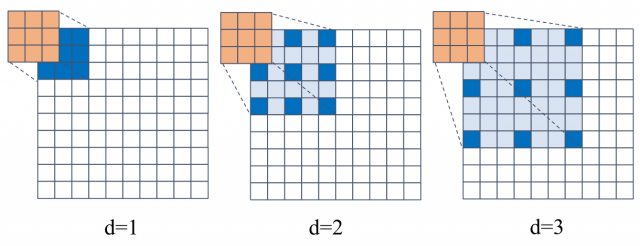
虽然随着空洞率的增加RecF会变大,但连续使用相同空洞率的空洞卷积会造成网格效应和信息损失。根据混合空洞卷积和非对称卷积技术,在编码器块中采用了d = 1、d = 2和d = 3的非对称3×3卷积,如图2所示。可以验证编码块可以获得大小为13 × 13的RecF,等于CsiNet+的大小。这不仅可以帮助编码块提取大规模信息,关注局部细节而不产生网格效应,还可以降低计算复杂度。
由于连接不同卷积的特征可以产生CSI的多分辨率以提高系统性能,因此对编码块执行连接操作,如图2(c)所示。采用标准3 × 3滤波器作为空洞卷积的补充,编码块的输入将通过两个并行分支,一个是空洞卷积,另一个是标准3 × 3卷积。然后将它们的输出进行连接,通过1 × 1卷积将通道数量减少到2。最后根据残差学习的思想,使编码块的输入添加到1 × 1卷积的输出中。
在图2(d)中,与编码块的设计原则类似,在第一个分支中,使用d = 2的3 × 3空洞卷积将特征维数增加到\(8ρ\),其中\(ρ≥1\)为网络宽度扩展率。通过调整扩展率\(ρ\),可以使DCRNet-\(ρ\) x适用于不同计算能力的模块,然后使用3×1和1×3且d=3的空洞卷积代替标准9×9的卷积,可以有效的减少计算复杂度。随后使用3×3的卷积来减少特征通道数到2。
在第二个分支中,不像在编码块中只使用一个标准卷积,这里使用了分组卷积和宽度扩展运算,因为BS的计算资源不像UE是有限的,而且宽度扩展运算对于CSI反馈同样重要。其中,1 × 3和3 × 1滤波器分别用于增加和减少特征维数,5 × 1和1 × 5分组卷积作用与第一个分支中的相似。两个分支的输出将被连接在一起,并通过1 × 1的卷积。
由于使用了空洞卷积和多分辨率思想,DCRNet比ACRNet的感受野宽得多,而且FLOPs更低,在性能和计算复杂度之间取得了很好的平衡。
根据COST2100实现室内5.3GHz和室外300MHz的训练和测试场景,BS处有\(N_t=32\)个均匀线性天线阵列和\(N_c=1024\)个子载波,原始大小为\(2×32×1024\)的CSI矩阵在转换到角延迟域处理之后,得到\(2×32×32\)的CSI矩阵,训练集、验证集和测试集分别为100000、30000和20000。
使用Kaiming initialization来产生每个卷积层和全连接层的权重,还采用了余弦退火学习率来增强网络性能,初始学习率的范围在\(\gamma _{min}=5×10^{-5}\)到\(\gamma _{max}=2×10^{-3}\)之间,学习率可以表示为:
\[\begin{align*} \gamma _{t} =\gamma _{min}+\frac{1}{2}(\gamma _{max}-\gamma _{min})\left(1+\cos \left({\frac{t-T_{w}}{T-T_{w}}\pi }\right)\right), \tag{9} \end{align*}
\]
其中,\(t\)是第\(t\)个训练时期,\(γ_t\)是当前的学习率,\(T_w\)和\(T\)分别是预热时期和总时期的数量,分别设置为30和2500。
使用归一化均方误差(NMSE)来评估输入CSI矩阵\({\boldsymbol{H}_{\boldsymbol{a}}}\)和输出CSI矩阵\(\hat{\boldsymbol{H}_{\boldsymbol{a}}}\)的区别,由下式给出:
\[\text{NMSE}=\mathbb {E}\left\lbrace {\left\Vert \boldsymbol{H}_{\boldsymbol{a}}-\hat{\boldsymbol{H}_{\boldsymbol{a}}}\right\Vert _{2}^{2}}\Big/{\left\Vert \boldsymbol{H}_{\boldsymbol{a}}\right\Vert _{2}^{2}}\right\rbrace,
\]
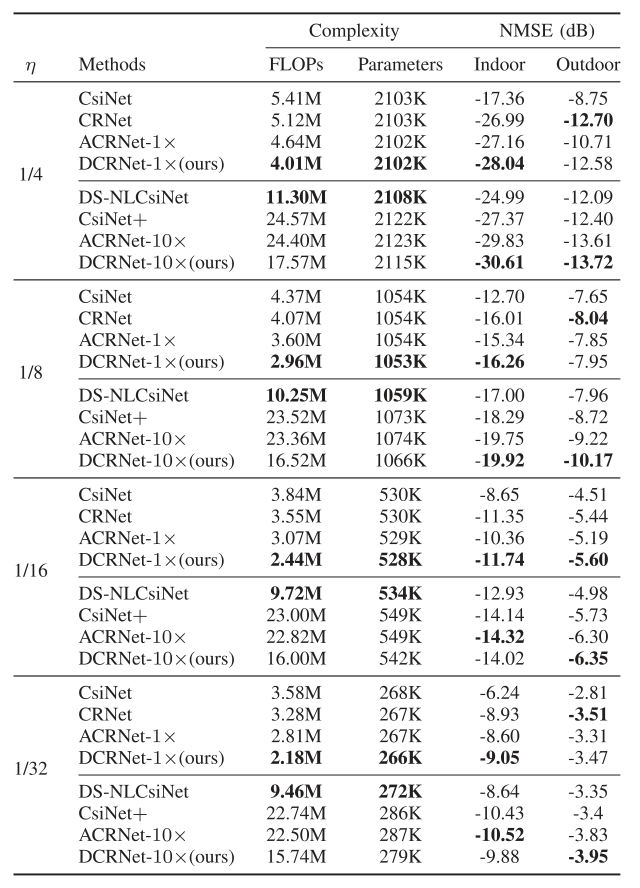
将DCRNet与基于DL的CSI反馈网络进行比较,分为低复杂度网络组:CsiNet、CRNet、ACRNet和DCRNet,和高复杂度且高性能组:DCRNet10×、DS-NLCsiNet、SOTA CsiNet+和ACRNet10×。
表1列出了上述几种CSI反馈网络的性能比较,其中压缩率\(η\)分别设置为1/4、1/8、1/16和1/32,最佳结果以粗体显示。从表1中,可以发现DCRNet-1×具有最低的计算复杂度和最少的参数,而且可以在室内场景下实现了不同压缩率下的SOTA性能,在室外场景下,DCRNet-1×仍然可以以最低的FLOP实现几乎相同的SOTA性能。
文献提出了DCRNet,网络采用空洞卷积来增加RecF,同时降低计算复杂度。仿真结果表明了DCRNet1×在计算资源有限的情况下优于其它轻量级网络,而且DCRNet-10×以比传统网络低得多的计算复杂度实现了几乎相同的重建性能。
原文链接:https://www.cnblogs.com/tanyuyang/p/17362660.html
本文链接:http://task.lmcjl.com/news/12082.html


