一、基本概念
RNN针对的数据是时序数据。RNN它解决了前馈神经网络,无法体现数据时序关系的缺点。在RNN网络中,不仅同一个隐含层的节点可以相互连接,同时隐含层的输入不仅来源于输入层的输入还包括了上一个隐含层的输出。
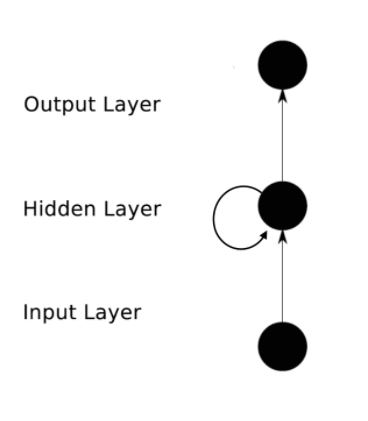
RNN中主要有以下几个参数:
(1)Xt表示第t隐含层的输入层的输入, St表示第t隐含层的隐含状态,Yt表示第t隐含层的输出
(2)U表示Xt的参数,W表示St-1的参数,V表示St的参数
(3)St = f(UXt+WSt-1) Yt = VSt
RNN实现了参数共享,也就是不管哪一层它的U,W和V参数的值都是一样的,这样就大大减少了需要训练的参数个数。
二、RNN的作用
(1)主要运用于序列化数据
(2)在NLP领域中的词性标注,词向量表达以及语句合法性检查有了很好的应用
(3)典型应用场景:
1、语言模型与文本生成:可以通过输入词向量序列来预测下一个单词可能是什么,也可以判断一个语句正确的可能性。
2、机器翻译:将一种语言翻译成另一种语言:进而文本生成的区别在于它的输入需要完整的语句序列。
3、语言识别
4、图像描述生成
三、RNN的训练
(1)采用BP算法
(2)实现参数共享
(3)因为RNN的网络与与前面的若干步相关,所以它在实现BP算法的时候采用了BPTT算法。但是BPTT算法有一定的局限性,一般它不能解决依赖性超过十步的问题。并且还会存在梯度爆炸和梯度消失的问题。
四、RNN拓展和改进模型
(1)Simple RNN(SRNN)
1、这是一个三层的神经网络
2、有一层和隐含层对应每一个节点固定相连的上下文单元层。这个上下文单元层的权值也是固定。它记录了序列化数据前一步的状态
3、该神经网络采用了前向传播算法
(2)Deep(Bidirectional) RNN
1、和Bidirecrtional RNN的区别在于Deep(Bidirectional) RNN的每一步的输入由多层网络。
Bidirectional RNN: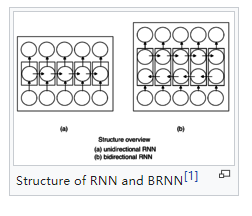
deep(Bidirectional) RNN:
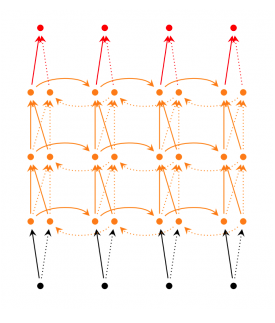
(3)Echo State Networks
1、它的网络有三部分组成:输入,存储池,输出。最大的特别之处就在于他用存储池代替了RNN中的隐含层
2、存储池里面是一些相互连接的节点单元
3、Echo State Network的关键是训练四个参数:输入权值参数Win,存储池中的节点的连接矩阵W,输出层到存储池的反馈Wback,输入层、存储池和输出层的相互连接Wout。
4、训练的过程用简单的线性回归
(4)GRU(Gated Recurent Unit RNN)
1、GRU的改进主要是两个方面:序列中的不同位置处的输入数据对于当前状态的影响是不一样的,所以需要对不同位置的输入数据赋予不同的权重;其次出现的错误的原因可能是某一个或某几个位置数据的影响,因此只需要更新相应位置的数据的权重。
2、GRU的图:
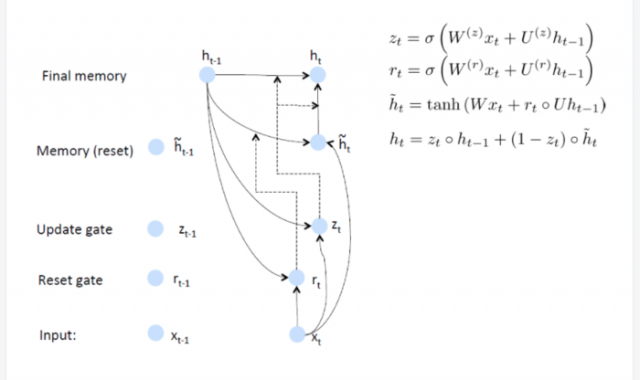
(5)LSTM
1、LSTM非常适合长序列依赖问题
2、它和RNN的主要区别在于隐含层的训练方式,它采用了独特的cell结构。
3、LSTM和GRU的比较
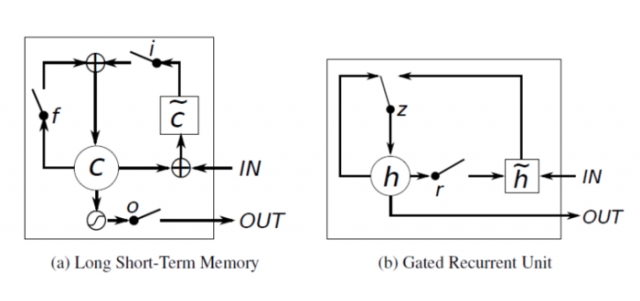
区别在于:
a、GRU有一个reset gate能够控制前一个的隐状态对当前状态的影响
b、LSTM有input gate和forget gate能够控制新状态的产生,而GRU只有update gate能够控制新状态的产生。
c、LSTM多了output gate能够调节输出的大小,而GRU则没有这个单元
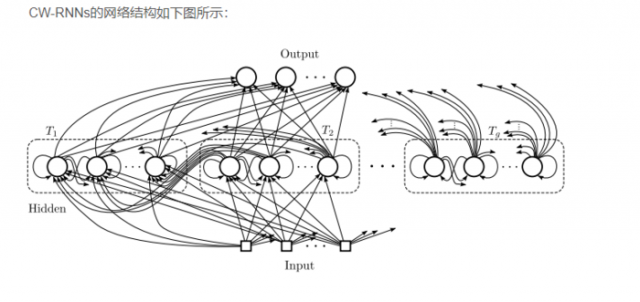
(6)Clockwork RNN
1、有三层的神经网络
2、隐含层网络被分成若干个块,每个块内的节点数大小相等,每一个块内的节点实现了全连接。
3、每一个块都有一个时钟周期,然后按照节点排序,时钟周期大的块内的节点能够全连接时钟周期小的块内的节点。
4、每一次只有满足(t mod Ti) = 0的隐含层块才会执行,这样就大大降低了网络的训练难度,提高了效率。
本文链接:http://task.lmcjl.com/news/12083.html


