我学习pytorch框架不是从框架开始,从代码中看不懂的pytorch代码开始的
可能由于是小白的原因,个人不喜欢一些一下子粘贴老多行代码的博主或者一些弄了一堆概念,导致我更迷惑还增加了畏惧的情绪(个人感觉哈),我觉得好像好多人都是喜欢给说的明明白白的,难听点就是嚼碎了喂我们。这样也行啊(有点恶心哈),但是有些东西即使嚼碎了我们也弄不明白,毕竟有一些知识是很难的(嚼碎后的知识我们都难以理解)
我知道了这些,也在尽力写博客时写的容易理解,但是自身实力有限,还做不到写博客写的既有条理又容易理解,请谅解,若有什么好的意见或者博客中的错误,欢迎指出,毕竟自己也是借助别人的博客和实践中的代码,写的更适于自己的理解
参考博客:https://blog.csdn.net/e01528/article/details/84075090 https://blog.csdn.net/qq_27825451/article/details/90550890
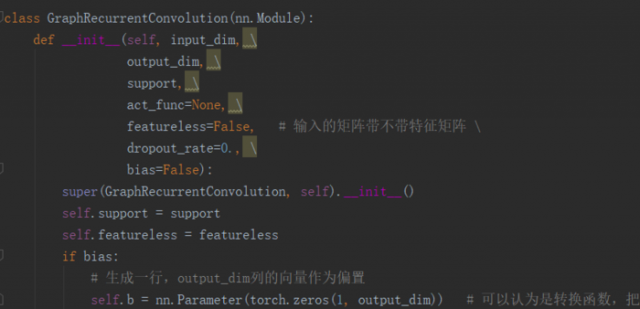
torch.nn.Module:所有网络的基类(官方文档),即我们自己定义网络或层,需要继承Module。常用的继承方法是:super(GraphConvolution, self).__init__(),其中GraphConvolution是自己定义的类或者模型或者说layer。其实nn.Module中无模型和层之分,层也当成一个模型来计算。
在GraphConvolution中的构造函数中需要自己定义可学习的参数和可学习的参数层(卷积层、全连接层),参数封装成parameter类型。因为训练模型需要的参数类型是parameter
forward(self,x)函数:前向传播函数,实现模型,即各个层的连接逻辑(哪个层接哪个层)。其输入可以是一个或多个variable变量,对x的任何操作也是variable变量。不需要写反向传播函数,因为torch.nn.Module可以利用autograd自动实现反向传播。
调用规则:调用layer(input)即可得到input对应的结果。就是输入函数所需的参数函数会给返回一个结果。规则:layers.__call__(input),在__call__函数中,主要调用的是layer.forward(x),就是layer(x)=layer.forward(x)
torch.mul(a,b)即矩阵a和矩阵b元素对应相乘,又叫Hadamard乘积。torch.mm(a,b):矩阵a乘以矩阵b。x.mm(a):矩阵x和矩阵a乘积。
torch常用函数可参考
https://www.jianshu.com/p/d678c5e44a6b https://www.jianshu.com/p/54708c840ec4
torch.range(start,end,step):返回一个以start开始以end结束,以step为公差的等差数列。输出时end包含在内。step可以省略,但是必须有start和end。返回的值是float32类型
torch.range(1,5):结果:tensor([1.,2.,3.,4.,5.]) torch.range(1,5,2):结果:tensor([1.,3.,5.])
torch.arange(start,end,step):返回一个以start开始以end结束,以step为公差的等差数列。输出时不包含end。end、step都可以省略。返回的值是int64类型
torch.arange(5):结果:tensor([1,2,3,4])
torch.squeeze():压缩张量维度;torch.unsqueeze():扩张张量维度
参考博客,感谢博主 https://blog.csdn.net/flysky_jay/article/details/81607289
https://www.cnblogs.com/Archer-Fang/p/10647986.html#4449096
本文链接:http://task.lmcjl.com/news/12233.html


