utils.py:
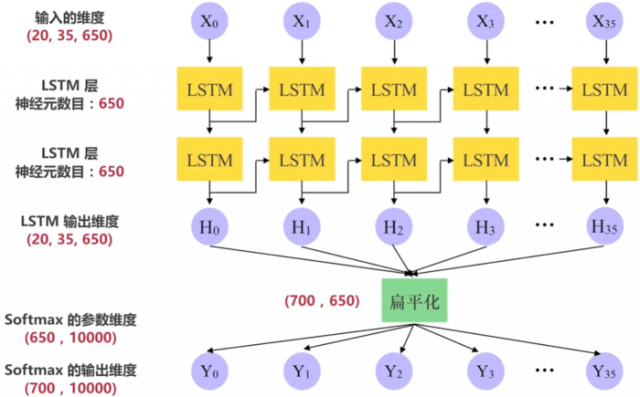
# -*- coding: UTF-8 -*- """ 实用方法 """ import os import sys import argparse import datetime import collections import numpy as np import tensorflow as tf """ 此例子中用到的数据是从 Tomas Mikolov 的网站取得的 PTB 数据集 PTB 文本数据集是语言模型学习中目前最广泛的数据集。 数据集中我们只需要利用 data 文件夹中的 ptb.test.txt,ptb.train.txt,ptb.valid.txt 三个数据文件 测试,训练,验证 数据集 这三个数据文件是已经经过预处理的,包含10000个不同的词语和语句结束标识符 <eos> 的 要获得此数据集,只需要用下面一行命令: wget http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz 如果没有 wget 的话,就安装一下: sudo apt install wget 解压下载下来的压缩文件: tar xvf simple-examples.tgz ==== 一些术语的概念 ==== # Batch size : 批次(样本)数目。一次迭代(Forword 运算(用于得到损失函数)以及 BackPropagation 运算(用于更新神经网络参数))所用的样本数目。Batch size 越大,所需的内存就越大 # Iteration : 迭代。每一次迭代更新一次权重(网络参数),每一次权重更新需要 Batch size 个数据进行 Forward 运算,再进行 BP 运算 # Epoch : 纪元/时代。所有的训练样本完成一次迭代 # 假如 : 训练集有 1000 个样本,Batch_size=10 # 那么 : 训练完整个样本集需要: 100 次 Iteration,1 个 Epoch # 但一般我们都不止训练一个 Epoch ==== 超参数(Hyper parameter)==== init_scale : 权重参数(Weights)的初始取值跨度,一开始取小一些比较利于训练 learning_rate : 学习率,训练时初始为 1.0 num_layers : LSTM 层的数目(默认是 2) num_steps : LSTM 展开的步(step)数,相当于每个批次输入单词的数目(默认是 35) hidden_size : LSTM 层的神经元数目,也是词向量的维度(默认是 650) max_lr_epoch : 用初始学习率训练的 Epoch 数目(默认是 10) dropout : 在 Dropout 层的留存率(默认是 0.5) lr_decay : 在过了 max_lr_epoch 之后每一个 Epoch 的学习率的衰减率,训练时初始为 0.93。让学习率逐渐衰减是提高训练效率的有效方法 batch_size : 批次(样本)数目。一次迭代(Forword 运算(用于得到损失函数)以及 BackPropagation 运算(用于更新神经网络参数))所用的样本数目 (batch_size 默认是 20。取比较小的 batch_size 更有利于 Stochastic Gradient Descent(随机梯度下降),防止被困在局部最小值) """ # 数据集的目录 data_path = "data" # 保存训练所得的模型参数文件的目录 save_path = './save' # 测试时读取模型参数文件的名称 load_file = "train-checkpoint-69" parser = argparse.ArgumentParser() # 数据集的目录 parser.add_argument('--data_path', type=str, default=data_path, help='The path of the data for training and testing') # 测试时读取模型参数文件的名称 parser.add_argument('--load_file', type=str, default=load_file, help='The path of checkpoint file of model variables saved during training') args = parser.parse_args() # 如果是 Python3 版本 Py3 = sys.version_info[0] == 3 # 将文件根据句末分割符 <eos> 来分割 def read_words(filename): with tf.gfile.GFile(filename, "r") as f: if Py3: return f.read().replace("n", "<eos>").split() else: return f.read().decode("utf-8").replace("n", "<eos>").split() # 构造从单词到唯一整数值的映射 # 后面的其他数的整数值按照它们在数据集里出现的次数多少来排序,出现较多的排前面 # 单词 the 出现频次最多,对应整数值是 0 # <unk> 表示 unknown(未知),第二多,整数值为 1 def build_vocab(filename): data = read_words(filename) # 用 Counter 统计单词出现的次数,为了之后按单词出现次数的多少来排序 counter = collections.Counter(data) count_pairs = sorted(counter.items(), key=lambda x: (-x[1], x[0])) words, _ = list(zip(*count_pairs)) # zip(*)将元组解压为列表 # 单词到整数的映射 word_to_id = dict(zip(words, range(len(words)))) return word_to_id # 将文件里的单词都替换成独一的整数 def file_to_word_ids(filename, word_to_id): data = read_words(filename) return [word_to_id[word] for word in data if word in word_to_id] # 加载所有数据,读取所有单词,把其转成唯一对应的整数值 def load_data(data_path): # 确保包含所有数据集文件的 data_path 文件夹在所有 Python 文件 # 的同级目录下。当然了,你也可以自定义文件夹名和路径 if not os.path.exists(data_path): raise Exception("包含所有数据集文件的 {} 文件夹 不在此目录下,请添加".format(data_path)) # 三个数据集的路径 train_path = os.path.join(data_path, "ptb.train.txt") valid_path = os.path.join(data_path, "ptb.valid.txt") test_path = os.path.join(data_path, "ptb.test.txt") # 建立词汇表,将所有单词(word)转为唯一对应的整数值(id) word_to_id = build_vocab(train_path) # 训练,验证和测试数据 train_data = file_to_word_ids(train_path, word_to_id) valid_data = file_to_word_ids(valid_path, word_to_id) test_data = file_to_word_ids(test_path, word_to_id) # 所有不重复单词的个数 vocab_size = len(word_to_id) # 反转一个词汇表:为了之后从 整数 转为 单词 id_to_word = dict(zip(word_to_id.values(), word_to_id.keys())) print(word_to_id) print("===================") print(vocab_size) print("===================") print(train_data[:10]) print("===================") print(" ".join([id_to_word[x] for x in train_data[:10]])) print("===================") return train_data, valid_data, test_data, vocab_size, id_to_word # 生成批次样本 def generate_batches(raw_data, batch_size, num_steps): # 将数据转为 Tensor 类型 raw_data = tf.convert_to_tensor(raw_data, name="raw_data", dtype=tf.int32) data_len = tf.size(raw_data) batch_len = data_len // batch_size # 将数据形状转为 [batch_size, batch_len] data = tf.reshape(raw_data[0: batch_size * batch_len], [batch_size, batch_len]) epoch_size = (batch_len - 1) // num_steps # range_input_producer 可以用多线程异步的方式从数据集里提取数据 # 用多线程可以加快训练,因为 feed_dict 的赋值方式效率不高 # shuffle 为 False 表示不打乱数据而按照队列先进先出的方式提取数据 i = tf.train.range_input_producer(epoch_size, shuffle=False).dequeue() # 假设一句话是这样: “我爱我的祖国和人民” # 那么,如果 x 是类似这样: “我爱我的祖国” x = data[:, i * num_steps:(i + 1) * num_steps] x.set_shape([batch_size, num_steps]) # y 就是类似这样(正好是 x 的时间步长 + 1): “爱我的祖国和” # 因为我们的模型就是要预测一句话中每一个单词的下一个单词 # 当然这边的例子很简单,实际的数据不止一个维度 y = data[:, i * num_steps + 1: (i + 1) * num_steps + 1] y.set_shape([batch_size, num_steps]) return x, y # 输入数据 class Input(object): def __init__(self, batch_size, num_steps, data): self.batch_size = batch_size self.num_steps = num_steps self.epoch_size = ((len(data) // batch_size) - 1) // num_steps # input_data 是输入,targets 是期望的输出 self.input_data, self.targets = generate_batches(data, batch_size, num_steps)
本文链接:http://task.lmcjl.com/news/12367.html


