在深度学习中,当数据量不够大时候,常常采用下面4中方法:
1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augmentation
2. Regularization. 数据量比较小会导致模型过拟合, 使得训练误差很小而测试误差特别大. 通过在Loss Function 后面加上正则项可以抑制过拟合的产生. 缺点是引入了一个需要手动调整的hyper-parameter. 详见 https://www.wikiwand.com/en/Regularization_(mathematics)
3. Dropout. 这也是一种正则化手段. 不过跟以上不同的是它通过随机将部分神经元的输出置零来实现. 详见 http://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
4. Unsupervised Pre-training. 用Auto-Encoder或者RBM的卷积形式一层一层地做无监督预训练, 最后加上分类层做有监督的Fine-Tuning. 参考 http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.207.1102&rep=rep1&type=pdf
下面我们来讨论Data Augmentation:
不同的任务背景下, 我们可以通过图像的几何变换, 使用以下一种或多种组合数据增强变换来增加输入数据的量. 这里具体的方法都来自数字图像处理的内容, 相关的知识点介绍, 网上都有, 就不一一介绍了.
T
.
作为实现部分, 这里介绍一下在python 环境下, 利用已有的开源代码库Keras作为实践:
1 # -*- coding: utf-8 -*- 2 __author__ = 'Administrator' 3 4 # import packages 5 from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img 6 7 datagen = ImageDataGenerator( 8 rotation_range=0.2, 9 width_shift_range=0.2, 10 height_shift_range=0.2, 11 shear_range=0.2, 12 zoom_range=0.2, 13 horizontal_flip=True, 14 fill_mode='nearest') 15 16 img = load_img('C:UsersAdministratorDesktopdataAlena.jpg') # this is a PIL image, please replace to your own file path 17 x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150) 18 x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150) 19 20 # the .flow() command below generates batches of randomly transformed images 21 # and saves the results to the `preview/` directory 22 23 i = 0 24 for batch in datagen.flow(x, 25 batch_size=1, 26 save_to_dir='C:UsersAdministratorDesktopdataApre',#生成后的图像保存路径 27 save_prefix='lena', 28 save_format='jpg'): 29 i += 1 30 if i > 20: #这个20指出要扩增多少个数据 31 break # otherwise the generator would loop indefinitely
主要函数:ImageDataGenerator 实现了大多数上文中提到的图像几何变换方法.
效果如下图所示:
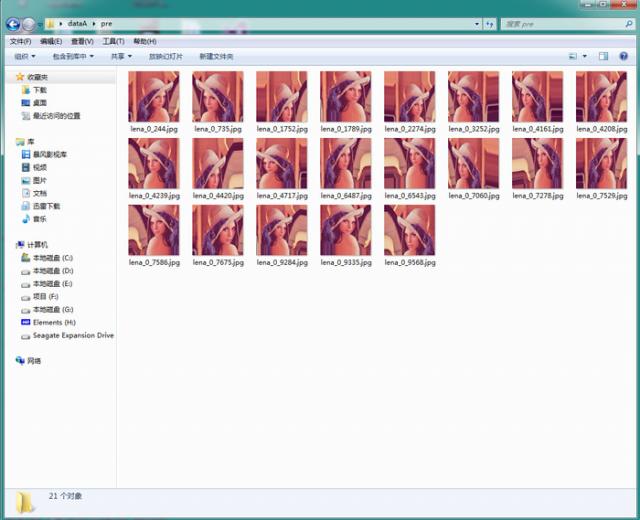
转载于:http://blog.csdn.net/mduanfire/article/details/51674098
为什么要做变形,或者说数据增强。从这个网站可以看出 http://scs.ryerson.ca/~aharley/vis/conv/ 手写字符稍微变形点,就有可能识别出错,因此数据增强可以生成一些变形的数据,让网络提前适应

1 # -*- coding: utf-8 -*- 2 __author__ = 'Administrator' 3 4 # import packages 5 from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img 6 7 datagen = ImageDataGenerator( 8 rotation_range=0.2, 9 width_shift_range=0.2, 10 height_shift_range=0.2, 11 shear_range=0.2, 12 zoom_range=0.2, 13 horizontal_flip=True, 14 fill_mode='nearest') 15 16 for k in range(33): 17 numstr = "{0:d}".format(k); 18 filename='C:\Users\Administrator\Desktop\bad\'+numstr+'.jpg'; 19 ufilename = unicode(filename , "utf8") 20 img = load_img(ufilename) # this is a PIL image, please replace to your own file path 21 x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150) 22 x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150) 23 24 # the .flow() command below generates batches of randomly transformed images 25 # and saves the results to the `preview/` directory 26 27 i = 0 28 29 for batch in datagen.flow(x, 30 batch_size=1, 31 save_to_dir='C:\Users\Administrator\Desktop\dataA\',#生成后的图像保存路径 32 save_prefix=numstr, 33 save_format='jpg'): 34 i += 1 35 if i > 20: 36 break # otherwise the generator would loop indefinitely 37 end
View Code
1 # -*- coding: utf-8 -*- 2 __author__ = 'Administrator' 3 4 # import packages 5 from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img 6 7 datagen = ImageDataGenerator( 8 rotation_range=10, 9 width_shift_range=0.2, 10 height_shift_range=0.2, 11 rescale=1./255, 12 shear_range=0.2, 13 zoom_range=0.2, 14 horizontal_flip=True, 15 fill_mode='nearest') 16 import os 17 18 import sys 19 reload(sys) 20 sys.setdefaultencoding('utf8') 21 22 ufilename = unicode("C:\Users\Administrator\Desktop\测试" , "utf8") 23 24 for filename in os.listdir(ufilename): #listdir的参数是文件夹的路径 25 print ( filename) #此时的filename是文件夹中文件的名称 26 pathname='C:\Users\Administrator\Desktop\测试\'+filename; 27 #ufilename = unicode(pathname , "utf8") 28 img = load_img(pathname) # this is a PIL image, please replace to your own file path 29 x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150) 30 x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150) 31 # the .flow() command below generates batches of randomly transformed images 32 # and saves the results to the `preview/` directory 33 i = 0 34 for batch in datagen.flow(x, 35 batch_size=1, 36 save_to_dir='C:\Users\Administrator\Desktop\result\',#生成后的图像保存路径 37 save_prefix=filename, 38 save_format='jpg'): 39 i += 1 40 if i > 100: 41 break # otherwise the generator would loop indefinitely 42 43 44 # datagen = ImageDataGenerator( 45 # rotation_range=0.2, 46 # width_shift_range=0.2, 47 # height_shift_range=0.2, 48 # rescale=1./255, 49 # shear_range=0.1, 50 # zoom_range=0.4, 51 # horizontal_flip=True, 52 # fill_mode='nearest') 53 # 54 # ufilename = unicode("C:\Users\Administrator\Desktop\训练" , "utf8") 55 # for filename in os.listdir(ufilename): #listdir的参数是文件夹的路径 56 # print ( filename) #此时的filename是文件夹中文件的名称 57 # pathname='C:\Users\Administrator\Desktop\训练\'+filename; 58 # # ufilename = unicode(pathname , "utf8") 59 # img = load_img(pathname) # this is a PIL image, please replace to your own file path 60 # x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150) 61 # x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150) 62 # 63 # # the .flow() command below generates batches of randomly transformed images 64 # # and saves the results to the `preview/` directory 65 # 66 # i = 0 67 # 68 # for batch in datagen.flow(x, 69 # batch_size=1, 70 # save_to_dir='C:\Users\Administrator\Desktop\result\',#生成后的图像保存路径 71 # save_prefix=filename, 72 # save_format='jpg'): 73 # i += 1 74 # if i > 100: 75 # break # otherwise the generator would loop indefinitely
View Code
https://github.com/mdbloice/Augmentor
本文链接:http://task.lmcjl.com/news/12536.html


