1、筛选功能
可以筛选出包含关键字的行、
删除包含关键字的行、
去重功能、
根据长度筛选
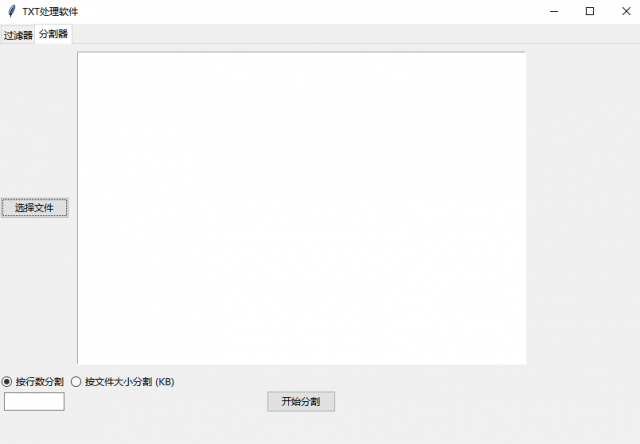
2、根据行数分割、根据大小分割。
import tkinter as tk
from tkinter import ttk
from tkinter import filedialog
import math
import os
def filter_contains():
input_text = input_textbox.get("1.0", tk.END).splitlines()
keywords = [kw.strip() for kw in keyword_textbox.get("1.0", tk.END).splitlines()]
output_text = [line for line in input_text if any(keyword in line for keyword in keywords)]
output_textbox.delete("1.0", tk.END)
output_textbox.insert(tk.END, "\n".join(output_text))
def filter_remove():
input_text = input_textbox.get("1.0", tk.END).splitlines()
keywords = [kw.strip() for kw in keyword_textbox.get("1.0", tk.END).splitlines()]
output_text = [line for line in input_text if not any(keyword in line for keyword in keywords)]
output_textbox.delete("1.0", tk.END)
output_textbox.insert(tk.END, "\n".join(output_text))
def remove_duplicates():
input_text = input_textbox.get("1.0", tk.END).splitlines()
output_text = list(dict.fromkeys(input_text))
output_textbox.delete("1.0", tk.END)
output_textbox.insert(tk.END, "\n".join(output_text))
def filter_by_length():
input_text = input_textbox.get("1.0", tk.END).splitlines()
length = int(length_entry.get())
if length_var.get() == "greater":
output_text = [line for line in input_text if len(line) > length]
else:
output_text = [line for line in input_text if len(line) < length]
output_textbox.delete("1.0", tk.END)
output_textbox.insert(tk.END, "\n".join(output_text))
def select_file():
file_path = filedialog.askopenfilename(filetypes=[("Text files", "*.txt")])
if file_path:
file_info.set(file_path)
file_size = os.path.getsize(file_path) / 1024
num_lines = sum(1 for line in open(file_path, 'r', encoding='utf-8'))
output_textbox_split.config(state="normal")
output_textbox_split.delete("1.0", tk.END)
output_textbox_split.insert(tk.END, f"文件行数: {num_lines}\n文件大小: {file_size:.2f} KB")
output_textbox_split.config(state="disabled")
def split_file():
file_path = file_info.get()
if not file_path:
output_textbox_split.config(state="normal")
output_textbox_split.insert(tk.END, "请选择文件\n")
output_textbox_split.config(state="disabled")
return
if split_var.get() == "lines":
lines_per_file = int(split_entry.get())
num_files = split_by_lines(file_path, lines_per_file)
else:
size_per_file = int(split_entry.get())
num_files = split_by_size(file_path, size_per_file)
output_textbox_split.insert(tk.END, f"分割完成,共生成{num_files}个文件\n")
def split_by_lines(file_path, lines_per_file):
with open(file_path, 'r', encoding='utf-8') as file:
file_name, file_extension = os.path.splitext(file_path)
i = 0
lines = []
for line in file:
lines.append(line)
if (i + 1) % lines_per_file == 0:
write_to_file(lines, f"{file_name}_part_{(i + 1) // lines_per_file}{file_extension}")
lines = []
i += 1
if lines:
num_parts = math.ceil((i + 1) / lines_per_file)
write_to_file(lines, f"{file_name}_part_{num_parts}{file_extension}")
def split_by_size(input_file, max_size_mb):
sub = 1
size = max_size_mb * 1024 # 分割大小约80K
with open(input_file, 'rb') as fin:
buf = fin.read(size)
while len(buf) > 0:
[des_filename, extname] = os.path.splitext(input_file)
filename = f"{des_filename}_{sub}{extname}"
write_to_file(buf.decode('utf-8'),filename)
sub += 1
buf = fin.read(size)
return sub-1
def write_to_file(lines, output_path):
with open(output_path, 'w', encoding='utf-8') as output_file:
output_file.writelines(lines)
output_textbox_split.config(state="normal")
output_textbox_split.insert(tk.END, f"\n分割完成: {output_path}")
output_textbox_split.config(state="disabled")
root = tk.Tk()
root.title("TXT处理软件")
tab_parent = ttk.Notebook(root)
tab1 = ttk.Frame(tab_parent)
tab2 = ttk.Frame(tab_parent)
tab_parent.add(tab1, text="过滤器")
tab_parent.add(tab2, text="分割器")
tab_parent.pack(expand=1, fill="both")
# 过滤器部分
input_textbox = tk.Text(tab1, width=40, height=50)
input_textbox.grid(row=0, column=0, padx=10, pady=10)
output_textbox = tk.Text(tab1, width=40, height=50)
output_textbox.grid(row=0, column=2, padx=10, pady=10)
controls_frame = tk.Frame(tab1)
controls_frame.grid(row=0, column=1, padx=10, pady=10)
keyword_label = tk.Label(controls_frame, text="关键字(换行分隔):")
keyword_label.pack()
keyword_textbox = tk.Text(controls_frame, width=20, height=10)
keyword_textbox.pack(pady=5)
contains_button = tk.Button(controls_frame, text="包含关键字", command=filter_contains)
contains_button.pack(pady=5)
remove_button = tk.Button(controls_frame, text="删除包含关键字的行", command=filter_remove)
remove_button.pack(pady=5)
remove_duplicates_button = tk.Button(controls_frame, text="去重", command=remove_duplicates)
remove_duplicates_button.pack(pady=5)
length_frame = tk.Frame(controls_frame)
length_frame.pack(pady=5)
length_label = tk.Label(length_frame, text="长度:")
length_label.pack(side=tk.LEFT)
length_entry = tk.Entry(length_frame, width=5)
length_entry.pack(side=tk.LEFT)
length_var = tk.StringVar()
greater_rb = tk.Radiobutton(length_frame, text="大于", variable=length_var, value="greater")
greater_rb.pack(side=tk.LEFT)
lesser_rb = tk.Radiobutton(length_frame, text="小于", variable=length_var, value="lesser")
lesser_rb.pack(side=tk.LEFT)
filter_length_button = tk.Button(controls_frame, text="按长度筛选", command=filter_by_length)
filter_length_button.pack(pady=5)
# 分割器部分
# 选择文件按钮
select_button = ttk.Button(tab2, text="选择文件", command=select_file)
select_button.grid(row=0, column=0)
# 文件信息
file_info = tk.StringVar()
file_info_label = ttk.Label(tab2, textvariable=file_info, width=50)
file_info_label.grid(row=0, column=1, padx=10)
# 分割方式
split_var = tk.StringVar(value="lines")
split_lines_rb = ttk.Radiobutton(tab2, text="按行数分割", variable=split_var, value="lines")
split_lines_rb.grid(row=1, column=0, sticky=tk.W)
split_size_rb = ttk.Radiobutton(tab2, text="按文件大小分割 (KB)", variable=split_var, value="size")
split_size_rb.grid(row=1, column=1, sticky=tk.W)
# 分割数量输入框
split_entry = ttk.Entry(tab2, width=10)
split_entry.grid(row=2, column=0)
# 开始分割按钮
start_split_button = ttk.Button(tab2, text="开始分割", command=split_file)
start_split_button.grid(row=2, column=1, padx=10)
# 输出框
output_textbox_split = tk.Text(tab2, width=80, height=30, wrap=tk.WORD, state="disabled")
output_textbox_split.grid(row=0, column=1, padx=10, pady=10)
root.mainloop()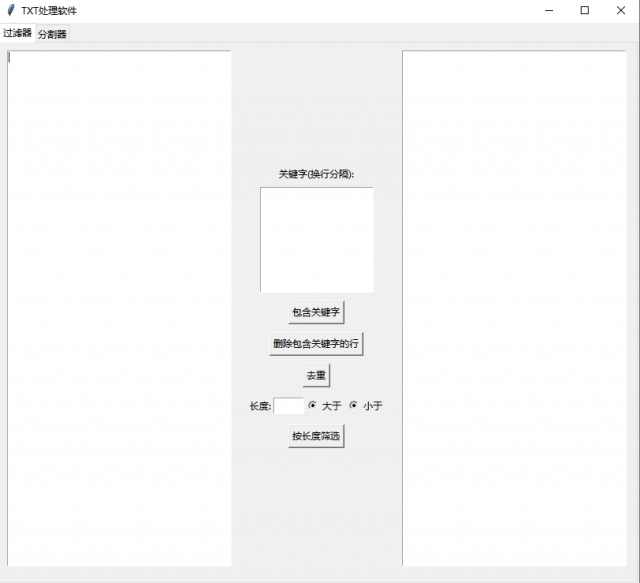
本文链接:http://task.lmcjl.com/news/1286.html


