Keras是一个开源的高层神经网络API,由纯Python编写而成,其后端可以基于Tensorflow、Theano、MXNet以及CNTK。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果。Keras适用的Python版本是:Python 2.7-3.6。
Keras,在希腊语中意为“角”(horn),于2015年3月份第一次发行,它可以在Windows, Linux, Mac等系统中运行。那么,既然有了TensorFlow(或Theano、MXNet、CNTK),为什么还需要Keras呢?这是因为,尽管我们可以用TensorFlow等来创建深度神经网络系统,但Tensorflow等使用相对低级的抽象,直接编写TensorFlow代码具有一定的挑战性,而Keras在TensorFlow的基础上,增加了较易使用的抽象层,使用起来更加简单、高效。
什么样的场合适合用Keras呢?如果你有如下需求,请选择Keras:
如果想用在你的电脑上使用Keras,需要以下工具:
在这里,我们选择TensorFlow作为Keras的后端工具。使用以下Python代码,可以输出Python、TensorFlow以及Keras的版本号:
import sys import keras as K import tensorflow as tf py_ver = sys.version k_ver = K.__version__ tf_ver = tf.__version__ print("Using Python version " + str(py_ver)) print("Using Keras version " + str(k_ver)) print("Using TensorFlow version " + str(tf_ver))
在笔者的电脑上,输出的结果如下:
Using TensorFlow backend. Using Python version 3.5.1 (v3.5.1:37a07cee5969, Dec 6 2015, 01:54:25) [MSC v.1900 64 bit (AMD64)] Using Keras version 2.1.5 Using TensorFlow version 1.6.0
下面,笔者将使用IRIS数据集(鸢尾花数据集,一个经典的机器学习数据集,适合作为多分类问题的测试数据),使用Keras搭建一个深度神经网络(DNN),来解决IRIS数据集的多分类问题,作为Keras入门的第一个例子。
IRIS数据集(鸢尾花数据集),是一个经典的机器学习数据集,适合作为多分类问题的测试数据,它的下载地址为:http://archive.ics.uci.edu/ml/machine-learning-databases/iris/。
IRIS数据集是用来给鸢尾花做分类的数据集,一共150个样本,每个样本包含了花萼长度(sepal length in cm)、花萼宽度(sepal width in cm)、花瓣长度(petal length in cm)、花瓣宽度(petal width in cm)四个特征,将鸢尾花分为三类,分别为Iris Setosa,Iris Versicolour,Iris Virginica,每一类都有50个样本。
IRIS数据集具体如下(只展示部分数据,顺序已打乱):
iris数据集预览
笔者的IRIS数据集以csv格式储存,笔者将使用Pandas来读取IRIS数据集,并对目标变量进行0-1编码(One-hot Encoding),最后将该数据集分为训练集和测试集,比例为7:3。完整的Python代码如下:
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelBinarizer # 读取CSV数据集,并拆分为训练集和测试集 # 该函数的传入参数为CSV_FILE_PATH: csv文件路径 def load_data(CSV_FILE_PATH): IRIS = pd.read_csv(CSV_FILE_PATH) target_var = 'class' # 目标变量 # 数据集的特征 features = list(IRIS.columns) features.remove(target_var) # 目标变量的类别 Class = IRIS[target_var].unique() # 目标变量的类别字典 Class_dict = dict(zip(Class, range(len(Class)))) # 增加一列target, 将目标变量进行编码 IRIS['target'] = IRIS[target_var].apply(lambda x: Class_dict[x]) # 对目标变量进行0-1编码(One-hot Encoding) lb = LabelBinarizer() lb.fit(list(Class_dict.values())) transformed_labels = lb.transform(IRIS['target']) y_bin_labels = [] # 对多分类进行0-1编码的变量 for i in range(transformed_labels.shape[1]): y_bin_labels.append('y' + str(i)) IRIS['y' + str(i)] = transformed_labels[:, i] # 将数据集分为训练集和测试集 train_x, test_x, train_y, test_y = train_test_split(IRIS[features], IRIS[y_bin_labels], \ train_size=0.7, test_size=0.3, random_state=0) return train_x, test_x, train_y, test_y, Class_dict
接下来,笔者将展示如何利用Keras来搭建一个简单的深度神经网络(DNN)来解决这个多分类问题。我们要搭建的DNN的结构如下图所示:
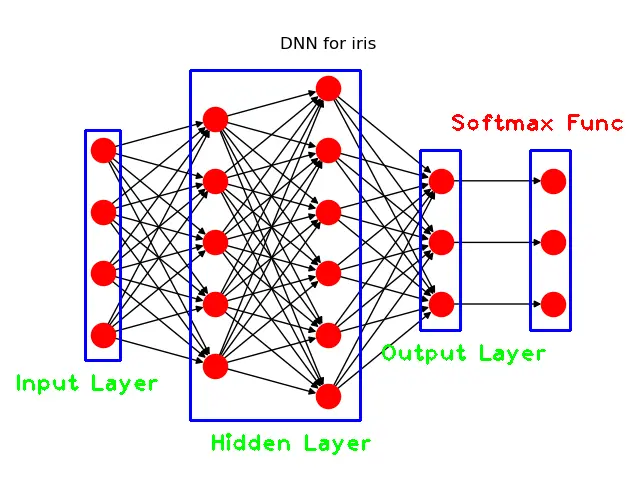
DNN模型的结构示意图
我们搭建的DNN由输入层、隐藏层、输出层和softmax函数组成,其中输入层由4个神经元组成,对应IRIS数据集中的4个特征,作为输入向量,隐藏层有两层,每层分别有5和6个神经元,之后就是输出层,由3个神经元组成,对应IRIS数据集的目标变量的类别个数,最后,就是一个softmax函数,用于解决多分类问题而创建。
对应以上的DNN结构,用Keras来搭建的话,其Python代码如下:
import keras as K # 2. 定义模型 init = K.initializers.glorot_uniform(seed=1) simple_adam = K.optimizers.Adam() model = K.models.Sequential() model.add(K.layers.Dense(units=5, input_dim=4, kernel_initializer=init, activation='relu')) model.add(K.layers.Dense(units=6, kernel_initializer=init, activation='relu')) model.add(K.layers.Dense(units=3, kernel_initializer=init, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=simple_adam, metrics=['accuracy'])
在这个模型中,我们选择的神经元激活函数为ReLU函数,损失函数为交叉熵(cross entropy),迭代的优化器(optimizer)选择Adam,最初各个层的连接权重(weights)和偏重(biases)是随机生成的。这样我们就讲这个DNN的模型定义完毕了。这么简单?Yes, that's it!
OK,定义完模型后,我们需要对模型进行训练、评估及预测。对于模型训练,我们每次训练的批数为1,共迭代100次,代码如下(接以上代码):
# 3. 训练模型 b_size = 1 max_epochs = 100 print("Starting training ") h = model.fit(train_x, train_y, batch_size=b_size, epochs=max_epochs, shuffle=True, verbose=1) print("Training finished \n")
为了对模型有个评估,感知模型的表现,需要输出该DNN模型的损失函数的值以及在测试集上的准确率,其Python代码如下(接以上代码):
# 4. 评估模型 eval = model.evaluate(test_x, test_y, verbose=0) print("Evaluation on test data: loss = %0.6f accuracy = %0.2f%% \n" \ % (eval[0], eval[1] * 100) )
训练100次,输出的结果如下(中间部分的训练展示已忽略):
Starting training Epoch 1/100 1/105 [..............................] - ETA: 17s - loss: 0.3679 - acc: 1.0000 42/105 [===========>..................] - ETA: 0s - loss: 1.8081 - acc: 0.3095 89/105 [========================>.....] - ETA: 0s - loss: 1.5068 - acc: 0.4270 105/105 [==============================] - 0s 3ms/step - loss: 1.4164 - acc: 0.4667 Epoch 2/100 1/105 [..............................] - ETA: 0s - loss: 0.4766 - acc: 1.0000 45/105 [===========>..................] - ETA: 0s - loss: 1.0813 - acc: 0.4889 93/105 [=========================>....] - ETA: 0s - loss: 1.0335 - acc: 0.4839 105/105 [==============================] - 0s 1ms/step - loss: 1.0144 - acc: 0.4857 ...... Epoch 99/100 1/105 [..............................] - ETA: 0s - loss: 0.0013 - acc: 1.0000 43/105 [===========>..................] - ETA: 0s - loss: 0.0447 - acc: 0.9767 84/105 [=======================>......] - ETA: 0s - loss: 0.0824 - acc: 0.9524 105/105 [==============================] - 0s 1ms/step - loss: 0.0711 - acc: 0.9619 Epoch 100/100 1/105 [..............................] - ETA: 0s - loss: 2.3032 - acc: 0.0000e+00 51/105 [=============>................] - ETA: 0s - loss: 0.1122 - acc: 0.9608 99/105 [===========================>..] - ETA: 0s - loss: 0.0755 - acc: 0.9798 105/105 [==============================] - 0s 1ms/step - loss: 0.0756 - acc: 0.9810 Training finished Evaluation on test data: loss = 0.094882 accuracy = 97.78%
可以看到,训练完100次后,在测试集上的准确率已达到97.78%,效果相当好。
最后是对新数据集进行预测,我们假设一朵鸢尾花的4个特征为6.1,3.1,5.1,1.1,我们想知道这个DNN模型会把它预测到哪一类,其Python代码如下:
import numpy as np # 5. 使用模型进行预测 np.set_printoptions(precision=4) unknown = np.array([[6.1, 3.1, 5.1, 1.1]], dtype=np.float32) predicted = model.predict(unknown) print("Using model to predict species for features: ") print(unknown) print("\nPredicted softmax vector is: ") print(predicted) species_dict = {v:k for k,v in Class_dict.items()} print("\nPredicted species is: ") print(species_dict[np.argmax(predicted)])
输出的结果如下:
Using model to predict species for features: [[ 6.1 3.1 5.1 1.1]] Predicted softmax vector is: [[ 2.0687e-07 9.7901e-01 2.0993e-02]] Predicted species is: versicolor
如果我们仔细地比对IRIS数据集,就会发现,这个预测结果令人相当满意,这个鸢尾花样本的预测结果,以人类的眼光来看,也应当是versicolor。
到此为止,笔者就把这个演示例子给讲完了,作为入门Keras的第一步,这个例子还是可以的。回顾该模型,首先我们利用Pandas读取IRIS数据集,并分为训练集和测试集,然后用Keras搭建了一个简单的DNN模型,并对该模型进行训练及评估,最后看一下该模型在新数据集上的预测能力。从中,读者不难体会到Keras的优越性,因为,相比TensorFlow,搭建同样的DNN模型及模型训练、评估、预测,其Python代码无疑会比Keras来得长。
最后,附上该DNN模型的完整Python代码:
# iris_keras_dnn.py # Python 3.5.1, TensorFlow 1.6.0, Keras 2.1.5 # ======================================================== # 导入模块 import os import numpy as np import keras as K import tensorflow as tf import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelBinarizer os.environ['TF_CPP_MIN_LOG_LEVEL']='2' # 读取CSV数据集,并拆分为训练集和测试集 # 该函数的传入参数为CSV_FILE_PATH: csv文件路径 def load_data(CSV_FILE_PATH): IRIS = pd.read_csv(CSV_FILE_PATH) target_var = 'class' # 目标变量 # 数据集的特征 features = list(IRIS.columns) features.remove(target_var) # 目标变量的类别 Class = IRIS[target_var].unique() # 目标变量的类别字典 Class_dict = dict(zip(Class, range(len(Class)))) # 增加一列target, 将目标变量进行编码 IRIS['target'] = IRIS[target_var].apply(lambda x: Class_dict[x]) # 对目标变量进行0-1编码(One-hot Encoding) lb = LabelBinarizer() lb.fit(list(Class_dict.values())) transformed_labels = lb.transform(IRIS['target']) y_bin_labels = [] # 对多分类进行0-1编码的变量 for i in range(transformed_labels.shape[1]): y_bin_labels.append('y' + str(i)) IRIS['y' + str(i)] = transformed_labels[:, i] # 将数据集分为训练集和测试集 train_x, test_x, train_y, test_y = train_test_split(IRIS[features], IRIS[y_bin_labels], \ train_size=0.7, test_size=0.3, random_state=0) return train_x, test_x, train_y, test_y, Class_dict def main(): # 0. 开始 print("\nIris dataset using Keras/TensorFlow ") np.random.seed(4) tf.set_random_seed(13) # 1. 读取CSV数据集 print("Loading Iris data into memory") CSV_FILE_PATH = 'E://iris.csv' train_x, test_x, train_y, test_y, Class_dict = load_data(CSV_FILE_PATH) # 2. 定义模型 init = K.initializers.glorot_uniform(seed=1) simple_adam = K.optimizers.Adam() model = K.models.Sequential() model.add(K.layers.Dense(units=5, input_dim=4, kernel_initializer=init, activation='relu')) model.add(K.layers.Dense(units=6, kernel_initializer=init, activation='relu')) model.add(K.layers.Dense(units=3, kernel_initializer=init, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=simple_adam, metrics=['accuracy']) # 3. 训练模型 b_size = 1 max_epochs = 100 print("Starting training ") h = model.fit(train_x, train_y, batch_size=b_size, epochs=max_epochs, shuffle=True, verbose=1) print("Training finished \n") # 4. 评估模型 eval = model.evaluate(test_x, test_y, verbose=0) print("Evaluation on test data: loss = %0.6f accuracy = %0.2f%% \n" \ % (eval[0], eval[1] * 100) ) # 5. 使用模型进行预测 np.set_printoptions(precision=4) unknown = np.array([[6.1, 3.1, 5.1, 1.1]], dtype=np.float32) predicted = model.predict(unknown) print("Using model to predict species for features: ") print(unknown) print("\nPredicted softmax vector is: ") print(predicted) species_dict = {v:k for k,v in Class_dict.items()} print("\nPredicted species is: ") print(species_dict[np.argmax(predicted)]) main()
本文链接:http://task.lmcjl.com/news/1545.html


