YOLO(You Only Look Once)论文
近些年,R-CNN等基于深度学习目标检测方法,大大提高了检测精度和检测速度。
例如在Pascal VOC数据集上Faster R-CNN的mAP达到了73.2。而YOLO和SSD在达到较高的检测精度的同时,检测速度都在40FPS以上。这里主要对YOLO做简单介绍。
整个YOLO的网络结构如图,前面20层使用了改进的GoogleNet,得到14×14×1024的tensor,接下来经过4个卷积层分别进行3×3的卷积操作和1×1的降维操作,最后经过两个全连接层后输出为7×7×30的tensor。检测目标就能从7×7×30的tensor中得到。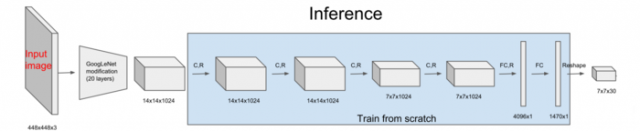
作者首先取出前面的20层网络,另外再加上一个average-pooling层和一个全连接层,在ImageNet训练集上进行图像分类任务的欲训练,top-5达到88%的准确度。然后将经过图像分类训练的前20层网络加上后面的网络层进行检测任务的训练。
7×7×30 tensor的解释:
其实这里的7×7并不是将输入图像划分为7×7的网格,实际上指经过多个卷积层处理过后的特征map是7×7大小的,而且其中的每个cell是互相有重叠的,但是为了便于直观理解,直接将原始图像用7×7的网格进行划分。可以看到每个cell向量的前5维分别代表了一个检测框的x坐标,y坐标,宽度和高度,检测框中有目标物体的置信度(P(Object) ∗ IOU)。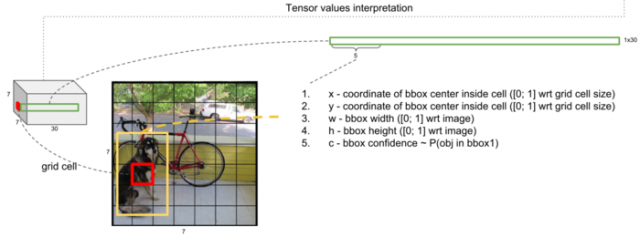
在论文中每个cell有两个检测框,6到10维向量代表了另外一个检测框的x坐标,y坐标,宽度和高度,检测框中有目标物体的置信度。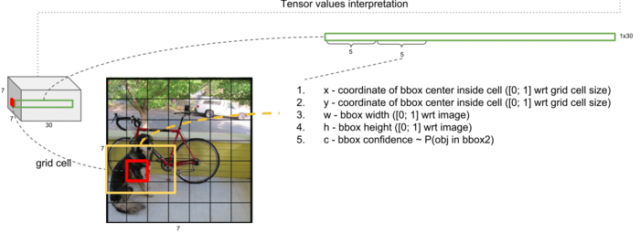
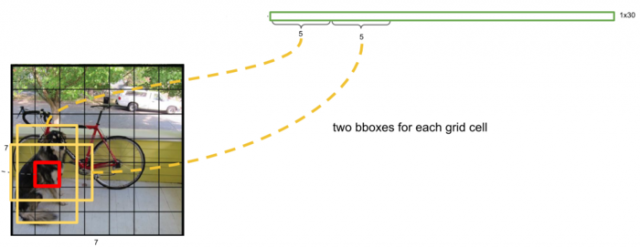
cell还剩下20维向量,代表这个cell中的物体属于20个类别的概率值。将cell两个检测框的置信度分别乘以20类别的概率值。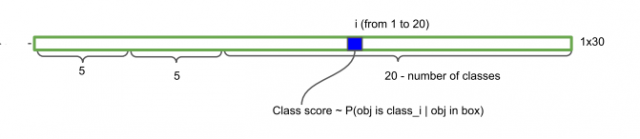
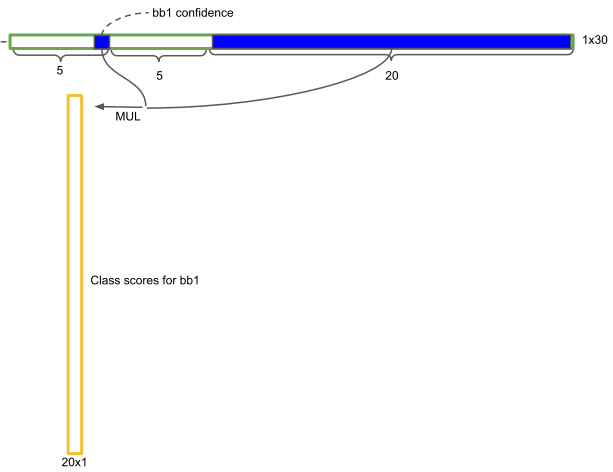
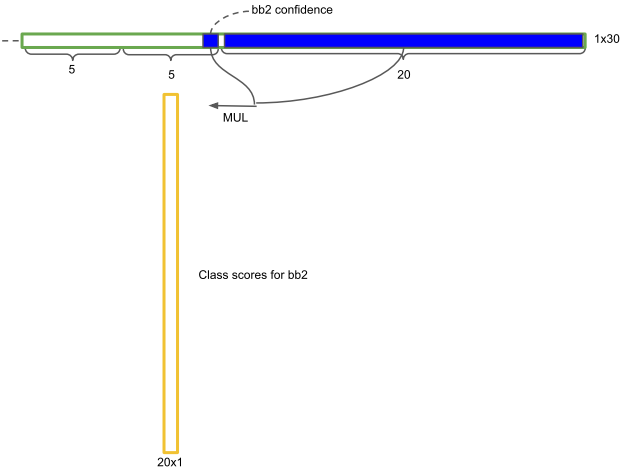
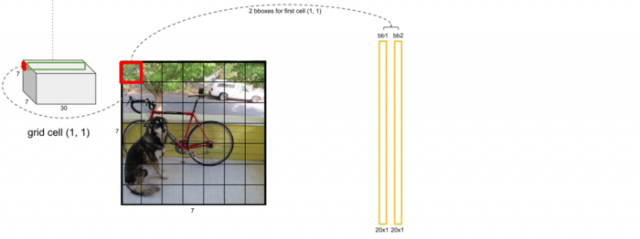
最后得到了7×7×2=98个检测框的20个类别的概率值。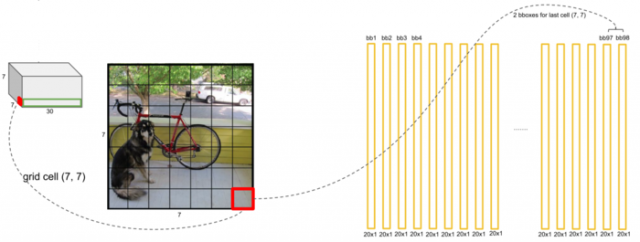
接下来要从候选的检测框中找出最后的目标框:
对每个类别,进行阈值比较、降序排列、对有重叠的候选框使用非极大值抑制(NMS)操作。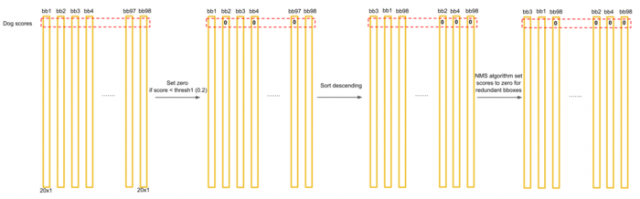
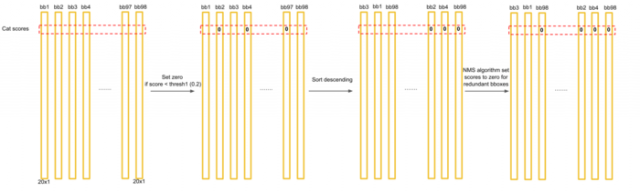
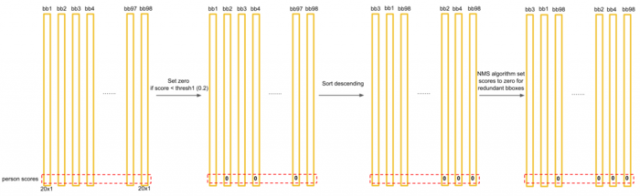
最后候选框的最终分数得到最终的类别和分数: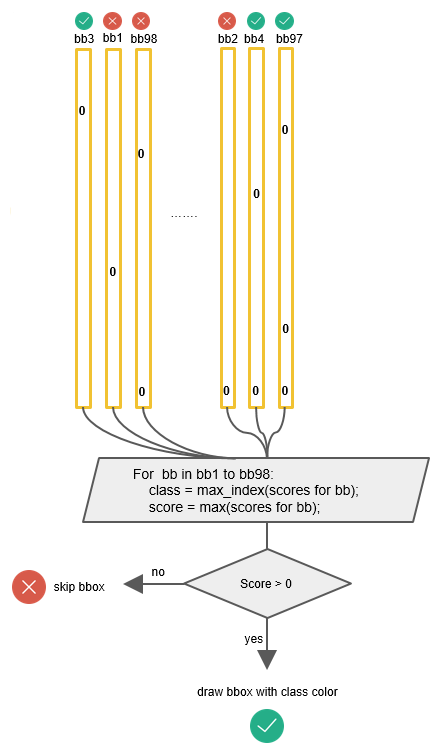
标出检测框:
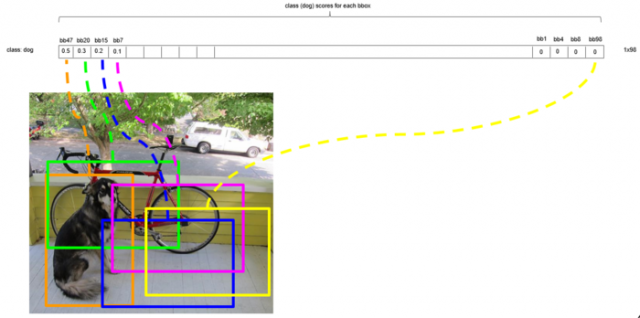
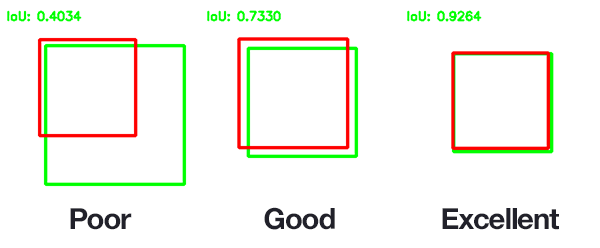
用bbox_max代表分数最大的候选框,将其与其他候选框bbox_cur进行比较,如果IoU(bbox_max,bbox_cur)>0.5,将候选框bbox_cur的分数置为0。
第一轮循环后,由于橙色框(bbox_max)和绿色框的重叠度大于0.5,所以将绿色候选框的分数置0。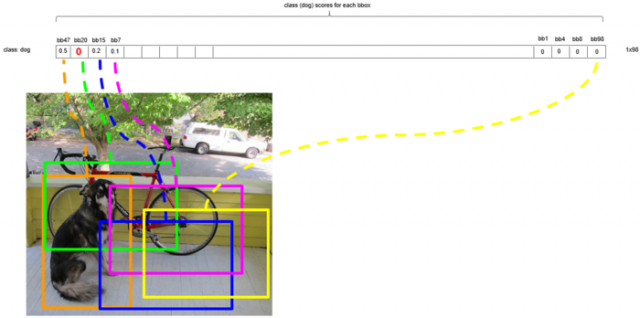
第二轮循环,将剩下的第二大分数的候选框设为bbox_max(图中的蓝色框)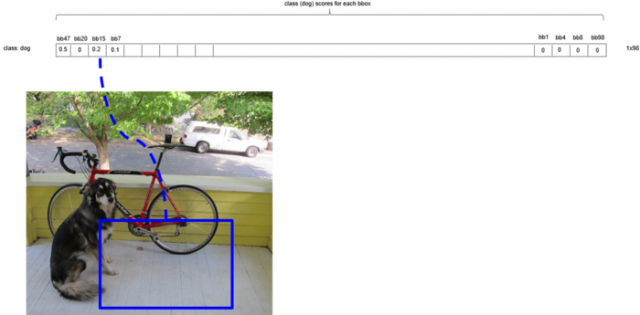
同样的道理,由于蓝色框(bbox_max)和粉色框的重叠度大于0.5,所以将粉色候选框的分数置0。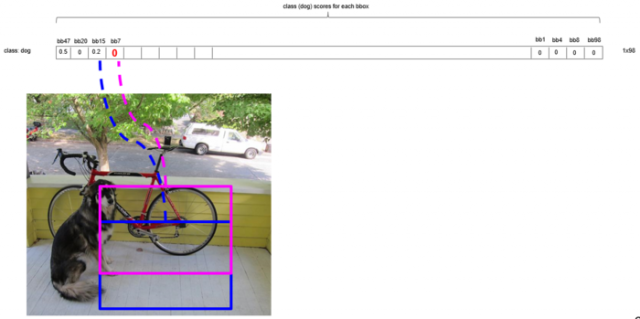
使用非极大值抑制循环结束后,很多情况下,都只有少数的几个候选框大于0。
后来作者对YOLO进行了改进,公布了YOLO v2,论文
在精度(73.4 mAP on Pascal voc)和速度两个方面都有提高,并且提出了能够检测9000类物体的方法。
具体改进的地方有:
本文链接:http://task.lmcjl.com/news/1544.html


