论文下载:https://pjreddie.com/media/files/papers/YOLOv3.pdf
论文代码: https://github.com/pjreddie/darknet

1、基本思想:
YOLO系算法的思想都是,首先通过特征提取网络对输入图像提取特征,得到一定大小的特征图(比如13*13),然后将输入图像划分网格成13*13个单元格,接着如果Ground Truth中某个目标的中心坐标落在哪个单元格中,那么就由该单元格来预测该目标,每个单元格都会预测固定数量的边界框(v1中是2个,v2中是5个,v3中是3个),这几个边界框中只有和Ground Truth的IOU最大的边界框才会被选定用来预测该目标。
预测得到的输出特征图有两个维度是提取到的特征,其中一个维度是平面,比如13*13,还有一个维度是深度,比如B*(5+C)(v1中是(B*5+C)),其中B表示每个单元格预测的边界框的数量,C表示边界框的对应的类别数(对于VOC数据集是20),5表示4个坐标信息和1个边界框置信得分(Objectness Score)。
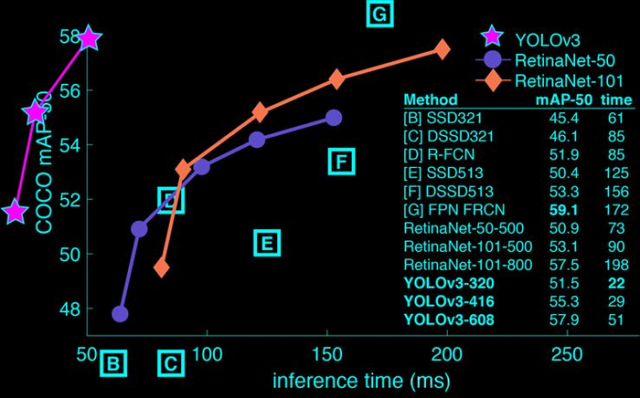
YOLO v3的模型比之前复杂不少,在速度和精度上的提升也非常明显(如图1-1),同时可以通过改变模型的结构来权衡速度与精度:
2、定位信息预测:
(1)初始化:
YOLOv3继续采用YOLO v2中的K-means聚类的方式来做Anchor Box的初始化,这种先验知识对于边界框的预测帮助很大,YOLOv3在COCO数据集上,按照输入图像的尺寸为416*416,得到9种聚类结果:(10*13); (16*30); (33*23); (30*61); (62*45); (59*119); (116*90); (156*198); (373*326)。
(2)预测:
YOLOv3延续了YOLOv2的做法,采用公式(1-1),其中(tx,ty,tw,th)就是模型的预测输出(网络学习目标),具体计算方式参看YOLOv2总结。(cx,cy) 是单元格的坐标偏移量(以单元格边长为单位),(pw,ph)是预设的Anchor Box的边长,(bx,by,bw,bh)就是最终得到的预测出的边界框的中心坐标和宽高。
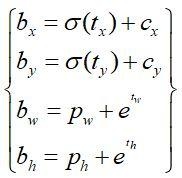
3、类别信息预测:
YOLOv3将之前版本的单标签分类改进为多标签分类,网络结构上将原来用于单标签分类的Softmax分类器(Detection层的**函数,其前一层采用Linear作为**函数,其他卷积层采用LeakyRelu作为**函数,这一点和前两版相同)换成用于多标签分类的Logistic分类器。
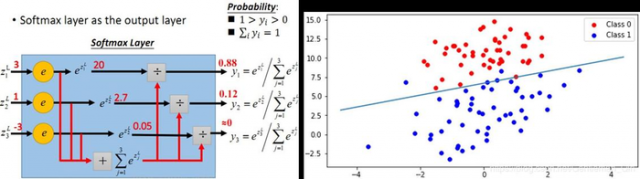
图1-2 Softmax分类器(YOLOv2)和Logistic分类器(YOLOv3)示意图:(a)、(b)
YOLOv2网络中的Softmax分类器,认为一个目标只属于一个类别,通过输出Score大小,使得每个框分配到Score最大的一个类别。但在一些复杂场景下,一个目标可能属于多个类(有重叠的类别标签),因此YOLOv3用多个独立的Logistic分类器替代Softmax层解决多标签分类问题,且准确率不会下降。
在训练过程中,使用二元交叉熵损失(Binary Cross-Entropy Loss)作为损失函数(Loss Function)来训练类别预测(v1和v2均采用了基于平方和的损失函数)。
Logistic分类器主要用到Sigmoid函数,该函数可以将输入约束在0到1的范围内,当一张图像经过特征提取后的某一边界框类别置信度经过sigmoid函数约束后如果大于0.5,就表示该边界框负责的目标属于该类。
4、多尺度特征融合(针对小目标):
低层的特征语义信息比较少,但是目标位置信息准确;高层的特征语义信息比较丰富,但是目标位置信息比较粗略。
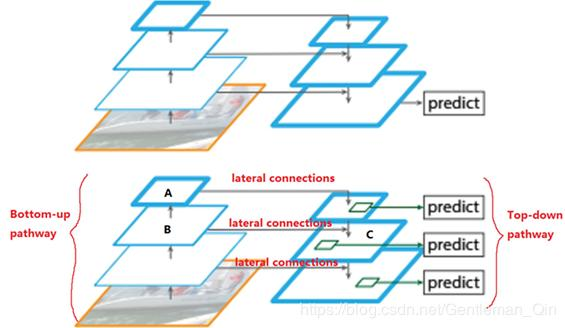
YOLOv2网络结构中有一个特殊的转换层(Passthrough Layer),假设最后提取的特征图的大小是13*13,转换层的作用就是将前面的26*26的特征图和本层的13*13的特征图进行
堆积(扩充特征维数据量),而后进行融合,再用融合后的特征图进行检测。这么做是为了加强算法对小目标检测的精确度。为达更好效果,YOLOv3将这一思想进行了加强和改进。

YOLO v3采用(类似FPN)上采样(Upsample)和融合做法,融合了3个尺度(13*13、26*26和52*52),在多个尺度的融合特征图上分别独立做检测,最终对于小目标的检测效果提升明显。(有些算法采用多尺度特征融合的方式,但是一般是采用融合后的单一特征图做预测,比如YOLOv2,FPN不一样的地方在于其预测是在不同特征层进行的。)
在YOLOv3中, Anchor Box由5个变为9个,其初始值依旧由K-means聚类算法产生。每个尺度下分配3个Anchor Box,每个单元格预测3个Bounding Box(对应3个Anchor Box)。每个单元格输出(1+4+C)*3个值(4个定位信息、1个置信度得分和C个条件类别概率),这也是每个尺度下最终输出的特征张量的深度(Depth)。
虽然YOLO v3中每1个单元格预测3个边界框,但因为YOLO v3采用了多尺度的特征融合,所以边界框的数量要比之前版本多很多(每个尺度下都需要预测相同数量的边界框)。以输入图像为416*416为例,YOLOv2中一张图片需要预测13*13*5=845个边界框,而YOLOv3中需要预测(13*13+26*26+52*52)*3=10647个边界框。
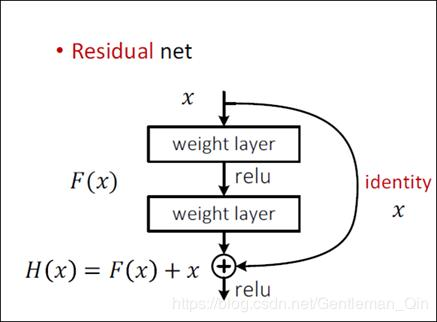
YOLOv3一方面采用全卷积(YOLOv2中采用池化层做特征图的下采样, v3中采用卷积层来实现),另一方面引入残差(Residual)结构,如图1-4。Res结构可以很好的控制梯度的传播,避免出现梯度消失或者爆炸等不利于训练的情形。这使得训练深层网络难度大大减小,因此才可以将网络做到53层,精度提升比较明显。(YOLO v2中是类似VGG的直筒型网络结构,层数过多会引起梯度问题,导致不易收敛,检测准确率下降,所以Darknet-19仅19层)。
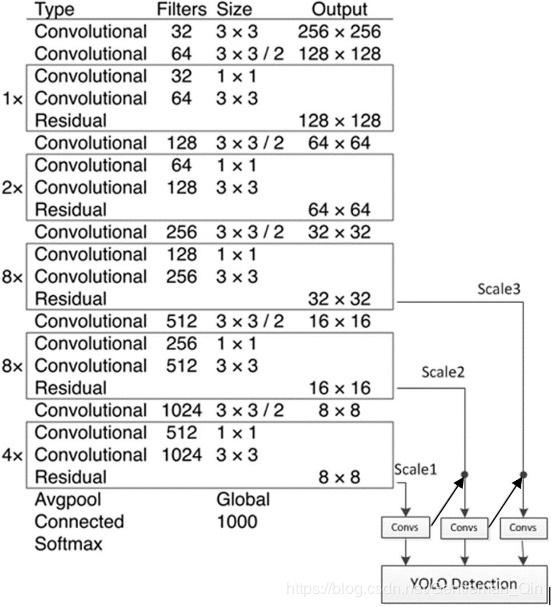
5、网络结构(基于Darknet-53):
Darknet-53是特征提取网络,YOLOv3使用了其中的卷积层(共53个,位于各个Res层之前)来提取特征,而多尺度特征融合和检测支路并没有在该网络结构中体现,因此补画在网络结构图中(如图1-5所示),检测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255。
YOLOv3在网络训练方面还是采用YOLOv2中的多尺度训练(Multi-Scale Training)方法。同时仍然采用了一连串的3*3、1*1卷积,3*3的卷积负责增加特征图通道数(Channels),而1*1的卷积负责压缩3*3卷积后的特征表示。
YOLOv3的完整网络结构示意图如图1-6所示,
其中左半部分是Darknet-53网络,下面详细分析。
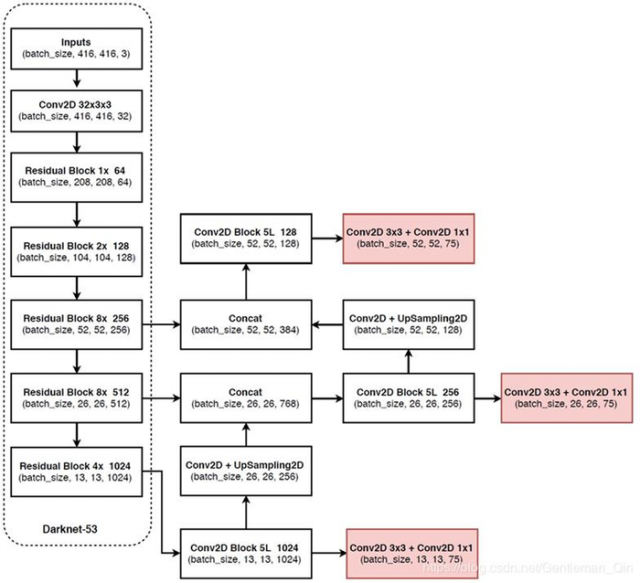
(1)卷积层:
YOLOv3网络的输入像素为416*416,通道数为3的图片(Random参数置1时可以自适应以32为基础的变化)。每一个卷积层都会对输入数据进行BN操作。每个卷积层卷积采用32个卷积核,每个卷积核大小为3*3,步伐为1。
(2)Res层:
一共选用五种具有不同尺度和深度的Res层,它们只进行不同层输出间的求残差操作。
(3)Darknet-53结构:
从第0层一直到74层,一共有53个卷积层,其余为Res层。作为YOLOv3进行特征提取的主要网络结构,Darknet使用一系列的3*3和1*1的卷积的卷积层(这些卷积层是从各主流网络结构选取性能比较好的卷积层进行整合得到。)
(4)YOLO层(对应v2中的Region层):
从75层到105层为YOLOv3网络的特征融合层,分为三个尺度(13*13、26*26和52*52),每个尺度下先堆积不同尺度的特征图,而后通过卷积核(3*3和1*1)的方式实现不同尺度特征图之间的局部特征融合,(YOLOv2中采用FC层实现全局特征融合)。最终输出的是特征图是深度为75的张量(3*(1+4+20)=75),其中20是VOC数据集的类别数。
A.输入:13*13的特征图 ,一共1024个通道;
B.操作:进行一系列卷积操作,特征图大小不变,通道数减少为75个;
C.输出:输出13*13大小的特征图,75个通道,然后在此基础上进行分类和定位回归。
A.输入:对79层的13*13、512通道的特征图进行卷积操作,生成13*13、256通道
的特征图,然后进行上采样,生成26*26、256通道的特征图,然后将其与61层的26*26、512通道的中尺度特征图进行合并;
B.操作:进行一系列卷积操作,特征图大小不变,通道数最后减少为75个。
C.输出:26*26大小的特征图,75个通道,然后在此进行分类和定位回归。
A.输入:对91层的26*26、256通道的特征图进行卷积操作,生成26*26、128通道的特征图,然后进行上采样生成52*52、128通道的特征图,然后将其与36层的52*52、256通道的中尺度特征度合并;
B.操作:进行一系列卷积操作,特征图大小不变,通道数最后减少为75个;
C.输出:52*52大小的特征图,75个通道,然后在此进行分类和位置回归。

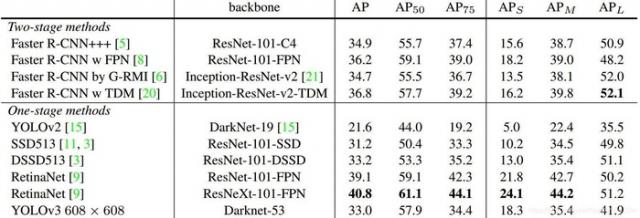
以下关于YOLOv3的性能上的对比实验:
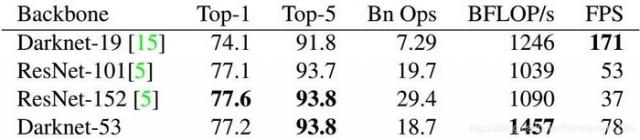
从表1-1中可以看出,Darknet-53比Darknet-19效果好很多,同时在效果更好的情况下,是resnet-101效率的1.5倍,几乎与Resnet-152的效果相同的情况下,保持2倍于Resnet-152的效率。
从表1-2中可以看出,YOLOv2对于小目标的检测效果比较差。YOLOv3在检测时通过引入多尺度特征融合,使得APs比YOLOv2高出不少,表明对小目标检测有更好性能。
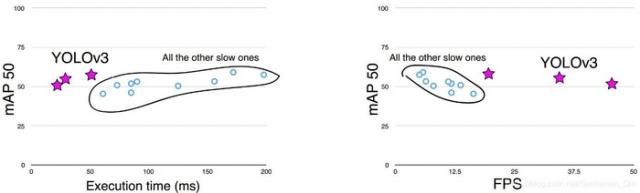
从表1-3中可以看出,在保证相同Map的情况下,YOLOv3在检测速度上具有较大优势。
本文链接:http://task.lmcjl.com/news/1551.html


