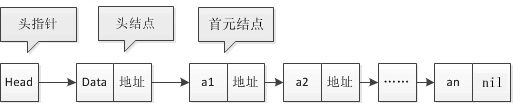
图:单向链表
type Node struct {
Data int
Next *node
}
其中成员 Data 用来存放结点中的有用数据,Next 是指针类型的成员,它指向 Node struct 类型数据,也就是下一个结点的数据类型。
package main
import "fmt"
type Node struct {
data int
next *Node
}
func Shownode(p *Node) { //遍历
for p != nil {
fmt.Println(*p)
p = p.next //移动指针
}
}
func main() {
var head = new(Node)
head.data = 1
var node1 = new(Node)
node1.data = 2
head.next = node1
var node2 = new(Node)
node2.data = 3
node1.next = node2
Shownode(head)
}
运行结果如下:
{1 0xc00004c1e0}
{2 0xc00004c1f0}
{3 <nil>}
package main
import "fmt"
type Node struct {
data int
next *Node
}
func Shownode(p *Node){ //遍历
for p != nil{
fmt.Println(*p)
p=p.next //移动指针
}
}
func main() {
var head = new(Node)
head.data = 0
var tail *Node
tail = head //tail用于记录头结点的地址,刚开始tail的的指针指向头结点
for i :=1 ;i<10;i++{
var node = Node{data:i}
node.next = tail //将新插入的node的next指向头结点
tail = &node //重新赋值头结点
}
Shownode(tail) //遍历结果
}
运行结果如下:
{9 0xc000036270}
{8 0xc000036260}
{7 0xc000036250}
{6 0xc000036240}
{5 0xc000036230}
{4 0xc000036220}
{3 0xc000036210}
{2 0xc000036200}
{1 0xc0000361f0}
{0 <nil>}
package main
import "fmt"
type Node struct {
data int
next *Node
}
func Shownode(p *Node){ //遍历
for p != nil{
fmt.Println(*p)
p=p.next //移动指针
}
}
func main() {
var head = new(Node)
head.data = 0
var tail *Node
tail = head //tail用于记录最末尾的结点的地址,刚开始tail的的指针指向头结点
for i :=1 ;i<10;i++{
var node = Node{data:i}
(*tail).next = &node
tail = &node
}
Shownode(head) //遍历结果
}
运行结果如下:
{0 0xc0000361f0}
{1 0xc000036200}
{2 0xc000036210}
{3 0xc000036220}
{4 0xc000036230}
{5 0xc000036240}
{6 0xc000036250}
{7 0xc000036260}
{8 0xc000036270}
{9 <nil>}
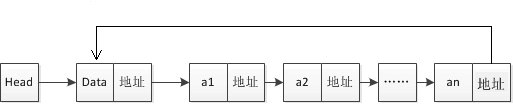
图:循环链表

图:双向链表
本文链接:http://task.lmcjl.com/news/16352.html


