由于爬虫抓取的数据不断增多,这两天在不断对数据库以及查询语句进行优化,其中一个表结构如下:
CREATE TABLE `newspaper_article` (
`id` varchar(50) NOT NULL COMMENT '编号',
`title` varchar(190) NOT NULL COMMENT '标题',
`author` varchar(255) DEFAULT NULL COMMENT '作者',
`date` date NULL DEFAULT NULL COMMENT '发表时间',
`content` longtext COMMENT '正文',
`status` tinyint(4) DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_status_date` (`status`,`date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
根据业务需要,添加了 idx_status_date 索引,在执行下面这个 SQL 时特别耗时:
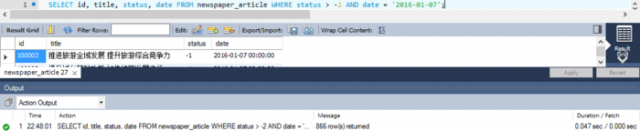
SELECT id, title, status, date FROM article WHERE status > -2 AND date = '2016-01-07';
根据观察,每天新增的数据大概在2500条以内,本以为这里指定了具体某天的日期 '2016-01-07' ,实际需要扫描的数据量应该在2500条以内才对,但实际并非如此:
实际共扫描了185589条数据,远远高于预估的2500条,且实际执行时间都将近3秒钟:

这是为什么呢?
将 idx_status_date (status, date) 改为 idx_status (status) 后,查看 MySQL 执行计划:

可以看到将多列索引改为单列索引后,执行计划要扫描的数据总量没有任何变化。结合多列索引遵循最左前缀原则,推测上面的查询语句只使用了 idx_status_date 最左边的 status 的索引。
翻了下《高性能MySQL》找到了下面这段话,证实了我的想法:
因此,这里解决思路有两种:
idx_status_date (status, date) 为索引 idx_date_status (date, status) ,并新建一个 idx_status 索引,即可达到同样的效果。优化后的执行计划:

实际执行结果:
当人们谈论索引的时候,如果没有特别指明类型,那么多半说的是 B-Tree 索引,它使用 B-Tree 数据结构来存储数据。我们使用术语“B-Tree”,是因为 MySQL 在 CREATE TABLE 和其他语句中也使用该关键字。不过,底层的存储引擎也可能使用不同的存储结构。InnoDB使用的是B+Tree。
假如有如下数据表:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f') not null,
key(last_name, first_name, dob)
);
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23' ,这个查询只能使用索引的前两列,因为这里 LIKE 是一个范围条件(但是服务器可以把其余列用于其他目的)。如果范围查询列值的数量有限,那么可以通过使用多个等于条件来代替范围条件。原文链接:http://xueliang.org/article/detail/20170326235631083
本文链接:http://task.lmcjl.com/news/17801.html


