GAN stands for Generative Adversarial Network, which was first developed in 2014. This brand new branch related to deep learning is amazing due to its effects and is hugely attractive to the researchers because it can create things that don't exist in the world by mimicing the huge amount of relevant data. 全名叫做生成对抗网络,最易开始发展于二零一四年,这个深度学习的分支领域广泛收到研究人员的关注原因就在于它可以 “创造” 东西,甚至这个东西并不存在,只要把足够多相关的数据给于这个机制,并使用深度学习神经网络训练,就可以凭空捏造出一个有模有样的数据出来。
最根本我们希望机器做到的事情就是自动的生成东西,其应用范围可以非常广泛:
从计算机的视角中,我们使用一个向量来告知计算机信号种类,并用此信号来生成对应的数据。最终我们希望能够让这些向量中的信号全都变成条件式,这样我们就可以良好的控制每一个对应生成的数据结果是否符合我们的预期。
但是目前我们先从简关注让计算机接收一个向量后,就可以输出一个我们预期数据的这样一个机制。
前面提到说对抗生成网络的最终目的是创造一个东西出来,而里面主要用来创造东西的机制就叫做:生成器。它也是一个神经网络,接收一个向量然后输出一个对应的结果,如下图:

从图片年可以了解到这是一个简易的条件生成器 (Conditional Generation),如果调整其中一个向量值,那么它的对应生成图片人物的头发就可能变长,类似这样的结果。
一个对抗生成网络的生成器捏造出了一个数据结果之后,需要有另一个机制去用来检测这个数据结果的优良程度怎么样,而这个机制的功能名为:分辨器。 它也是一个神经网络,只是接收的输入是生成器的输出,经过分辨器自己的神经网络处理之后,输出一个数值,这个数质越大的话,则优良程度越好,如下图: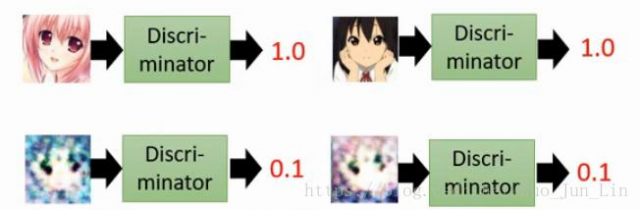
如果一分表示非常好的结果,那么上面两个二次元头像的结果就是好的,而下面只得到零点一分的两个结果则相反。
一个生成器在最一开始产生任何形式之数据的时候,并不知道自己的作品是好是坏,因此分辨器就充当老师的角色来指正作品,但是作为一个新手老师,它也不知道如何评判数据的好坏,因此需要使用到结构化学习来让自己逐渐进步,而用来使之学习的特征标签则是人类主动告知计算机的繁琐过程。
随着训练次数的增加,分辨器能够越来越好的掌握我们灌输它的肌理,并且把它自己所掌握的观念回传到生成器中,让生成器颤声些更为像样的东西出来,因此这个个输出结果就可以看到逐渐的进步。
因此在准备训练对抗神经网络时,我们需要下面几个步骤:
生成器与分辨器的进步过程如下可爱的模拟对话: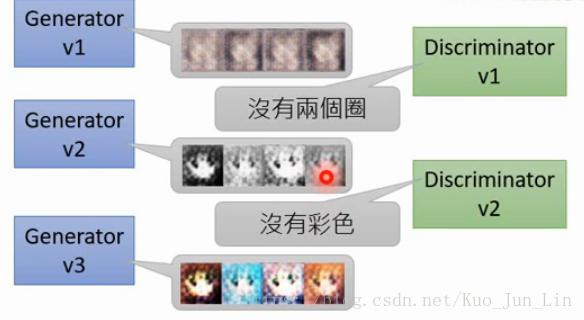
经过上面的描述理解了算法后,接下来进入到实际操作的阶段,一共分为几个步骤开始训练,训练之前有件事情必须完成: 初始化生成器与分辨器。因为他们都是神经网络,所有的参数初始化都是随机的。
并且在每次迭代中有两件事清必须做,分别如下:
固定生成器的参数,把很多个向量值作为输入放到生成器神经网络中产生一个结果,并训练分辨器的网络,使其能够理解数据库里面的数据和生成器产生出来的数据彼此之间的差异是什么,并根据这些差异给予对应的高分与低分,如下面图片: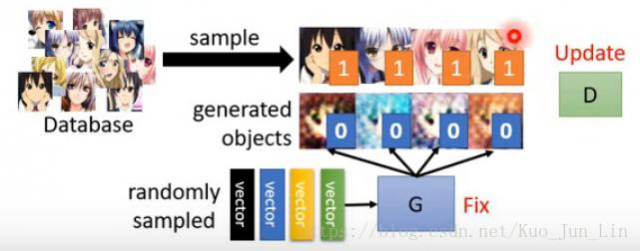
分辨器训练一轮之后升上了第二阶段,再也没有第一阶段生成器的图片能够蒙骗过分辨器的眼睛,接下来就要换成固定住分辨器的参数,转而来训练生成器的神经网络中的参数,目标是让被固定住的分辨器分辨出来的结果越高越好,这样就能够进一轮的骗过分辨器达到目的,如下面图片: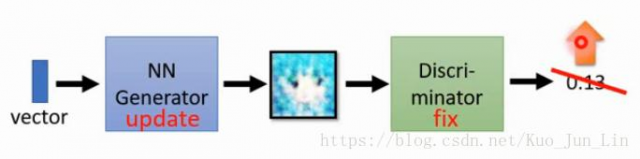
每次的迭代训练就是在事件一二中间不断的来回切换,直到最后面生成器出现的结果已经非常逼近数据库的结果了,那就可以认为是完成了训练,并且已经有能力自行创造图像。训练中用代码做出来的样子其实是把事件一二拼成一个大的神经网络,中间有一层对应到 1×n 的向量输出用以表示一张生成器创造的图片。 更多细节的公式推到内容,大力推荐关注李宏毅老师的视频。
上面我们解决的问题都是简单的输入输出问题,但是如果输入与输出的数据类型不相等,例如输入一个向量,想要的到一串文字,一张图片,一个矩阵等等,都是这类结构化学习的范畴,输出是相关的不同元素。 下面是结构化学习的相关领域列举:
假设一个分类问题中的某些类别,我们只能够提供非常少量的范例给到机器去训练,这样意味着如果我们把每一种输出当作一个类别看待的话,很多在测试集出现的类别中甚至训练集压根没出现过,因此在这种极端的,范例少的问题中如何去一般化结果,并让计算机学会创造东西,这个问题才能够迎刃而解。
生成新的东西时,计算机必须要有大局观,了解每个数据之间的关联性是什么,并且能够藉由这样的全局观考量与分析问题,最后判断出一个正确且符合预期的结果。攻克此挑战的主要两个方法结合:
其中前者背后的映射角色就是生成器,而后者角色就是分辨器,他们彼此协助之后,才能够在解题上展现效果。
前面已经得知生成器的构造说到底就是一个神经网络,训练它的过程不外乎给很多输入,经过参数的初始化之后,得出很多的结果。而生成器不像之前做的卷积神经网络输入的是一个图片,输出一个向量表示分类的归属,相反的,生成器输入的是一串向量,得到一张它随意创造的图片,训练的过程也很简单,步骤如下:
p.s. 过程如同一个监督学习,使用梯度下降即可解决
但是随机赋予的向量有一个坏处他可能没办法与图片的特征有效的结合在一起,需要使用 ”加密器(Encoder)“ 去训练完成图片向量化的过程,再使用该向量作为一个输入,放入一个神经网络中重新解密为一张图片,并且该解密的图片必须与原来的样子越接近越好,如下图: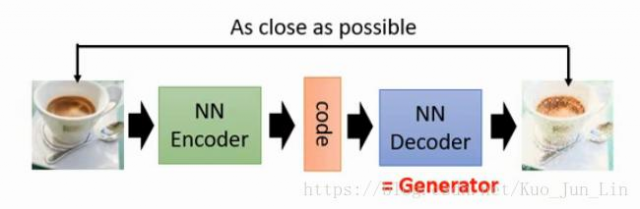
不过经过加密器生成的特征向量有些问题浮现,如果把其中部分的参数做平均相加,得出来的结果会因为神经网络本身非线性的问题而造成非线性不可预期的结果,这并非我们想要的,解决方式如下图: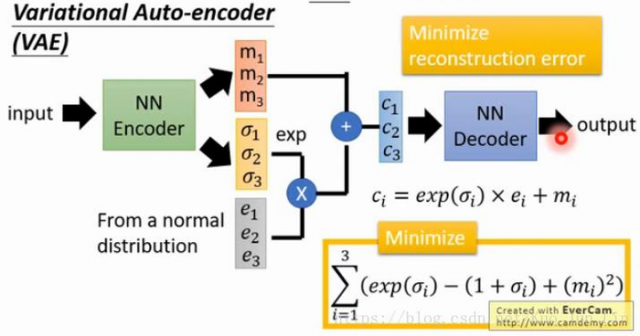
到了现在还有最后一环节需要被攻克,分辨错误的机制! 如果生成了一张图片的目的是为了最低减小误差值,那么可能结果就会牺牲一些人眼看上去难以接受的错误,这个时候前面提到的全局观在监督学习的重要性上就尤为凸显,单点数据之间的关联性成为了一个结果是否合格重要指标。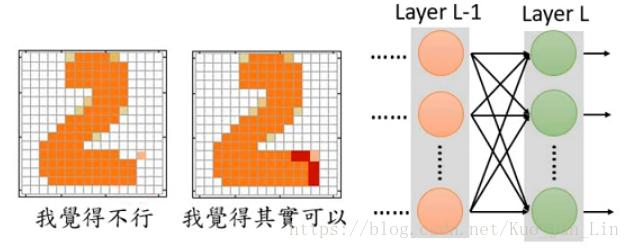
这个时候解决问题的方法就是多加几层神经网络上去,让计算机最终渐渐学到如何分辨个别单元的彼此关系,这也是为什么我们无法只用生成器去训练的原因,取而代之的两个可行方法:
使用分辨器去生成数据其实也是一个可行的办法,并能且它不像生成器的机制,每次生成数据都是单个点刻出来,顾不及全局问题,反观分辨器可能里面的神经网络包含了一个卷积核,可以用来探测是否有奇异的数据点存在,这也是相较于生成器的一大优势所在。
说到生成一张图片的方法其实就是反向操作的过程,让分辨器穷举所有图片去评判高低分,然后最高分数的图片就视为它的输出结果,这就是概念性的分辨器造图方法。
但是在训练的时候有很多事情需要注意下面几项要点:
生成器与分辨器就像太极的两边,一旦拆散了其中一对后,就需要一个类似功能的东西来填补空洞,而填补分辨器另一半的东西就是要有一个好的机制,可以逐步的让分辨器去迭代其评判能力,最后顺利模仿出数据库里面的数据模型,步骤如下:
过程像是在雕刻一般,一点一点的把雕刻师心中样貌轮廓以外的材料剔除,留下的就会是越来越接近真实的美丽结果。如果使用图像化的描述,如下图所示: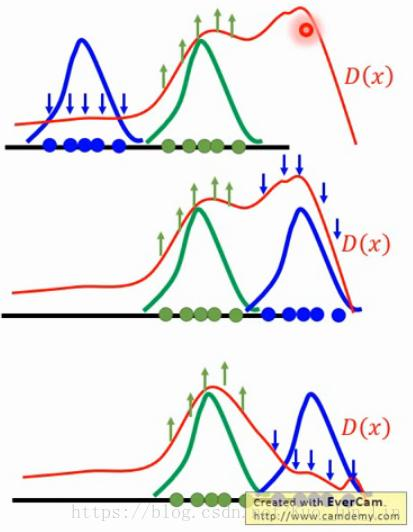
实际上也有很多论文使用的方法就是把他们分开来操作产生图片的,深入的内容需要另外钻研。
他们各有彼此的优势与劣势,是一个互助的过程,一个精巧的设计,让整个神经网络可以简单快速的工作起来,下面是个别优劣要点:
比较全面的理解了生成器与分辨器的功能之后,现在就可以比较深刻的体会到生成对抗网络的设计优美之处,这个框架巧妙地利用彼此的优点去补足勒彼此的缺点,让生成器的全局观狭隘问题在分辨器上面得以被解决,并且同时让分辨器难以生成优良的错误图像这个问题被生成器克服。
下面图片是不同生成对抗网络的模型性能比较: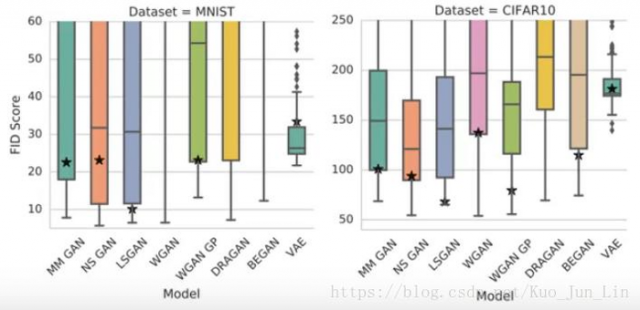
除了 VAE 之外,似乎所有其他的模型差距并不会特别的大。
本文链接:http://task.lmcjl.com/news/5362.html


