当前的生成框架使用的端至端的学习,并从均匀噪声分布采样产生图像。然而,这些方法忽略图像形成的最基本的原理。图像是按照以下方式产生的:(a)结构:3D模型;(B)样式:纹理到结构的映射。在本文中,作者分解图像的生成过程,并提出了样式-结构生成对抗网络( S2GAN )。 S2GAN 有两个组成部分:结构GAN产生一个面法线图; 样式GAN取面法线图作为输入,并产生2D图像。除了真实的生成损失之外,作者通过计算与生成图像的表面法线之间的额外损失。这两个GAN首先被分别训练,然后通过共同学习合并在一起。 S2GAN 模型是可解释的,产生更逼真的图像,并且可以用来学习无监督RGBD表示。
视觉表示的无监督学习的是计算机视觉领域中最根本的问题之一。无监督学习常用两种方法:
(a)使用判别式框架,作为任务的辅助,如上下文预测 [1,2] 或temporal embedding [3,4,5,6,7,8];
(b)使用生成式框架,学习各个组成部分并尝试产生逼真的图像 [9,10,11,12]。在生成式框架的基本假设是,如果模型足够产生新颖、逼真的图像,它应该同时也是视觉任务的良好表示。大多数这些生成框架使用的是端至端的学习,以生成从控制参数的RGB图像( z 也称为噪声,因为它是从均匀分布采样的)。最近,在一些限定的领域(如人脸和卧室)已经有了印象深刻的结果 [13] 。
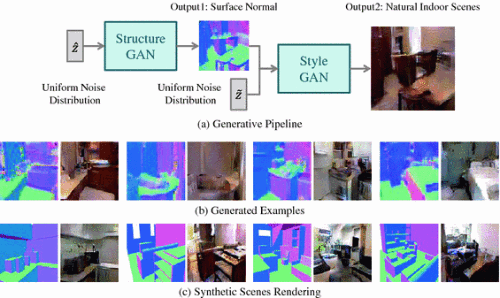
图1 为了让法线方向可视化,用蓝色代表右,用绿色代表水平面,红色代表左。
(a)生成的流程:给定从均匀分布采样的 z^ ,结构GAN产生一个面法线图作为输出。面法线图与给定的 z^ 被输入到第二层生成网络(样式GAN),并输出图像。
(b)生成的表面法线图和图像的例子。
(c)样式-GAN可以用作渲染引擎:给定一个合成的场景,可以用它来呈现逼真的图像。
然而,这些方法忽略了图像形成的最底层的基本原则之一。图像是以下两个独立现象的产物:
(1)结构 所编码场景的基本几何体,它指的是物体的表面,体素等最基本表示;
(2)样式 编码的对象的照明质感。
本文中根据图像的 IM101 基本原理和因子,将生成对抗网络(GAN)分成两个生成过程,如 图1 所示。
(1)第一,结构生成模型(即结构-GAN),采取 z^ 并产生场景的底层3D结构 y3D 。
(2)第二,条件生成网络(即样式-GAN),将 y3D 和噪声 z~ 作为输入以生成图像 yI 。作者把这个生成网络的体系结构称为 结构-样式生成对抗网络(S2GAN)。
为什么使用 S2GAN ?作者认为,以样式和结构为条件的图像生成过程有四点优势:
(1)首先,以样式和结构为条件简化了整个生成过程,能生成更逼真的高分辨率图像,使学习过程更加鲁棒和稳定。
(2)其次, S2GAN 相比其他GAN更可解释。人们甚至可以找到错误的原因,并且通过与上下文相比,理解在什么地方面法线图的生成是失败的。
(3)第三,实验结果表明, S2GAN 可以学会无人监督的RGBD表示。这可能是许多机器人和图形应用的关键。
(4)最后,样式-GAN也可以看作是一个具有学习任何给定3D输入能力的渲染引擎,它能够呈现相应的图像。基于它也能够建立应用程序,可以修改输入图像的基本三维结构并呈现一个全新的形象。
然而,学习 S2GAN 仍然不是一件容易的事。为了应对这一挑战,本文先以独立的方式学习 样式-GAN 和 结构-GAN。本文使用NYU v2 RGBD数据集 [14] 中的超过200个K个帧用于学习初始网络。另外,使用来自Kinect表面法线的ground truth去训练结构-GAN。因为透视失真更直接相关的法线而不是深度,作者使用表面法线来表示本文的图像结构。作者并行学习风格-GAN时有两个损失函数:第一个损失函数接受图像的表面和法线,并试图判断它们是否对应于真实场景。然而,只有这种损失函数不能基于明确的像素的约束将生成的图像与表面法线配对。为了实现逐像素的约束,作者做出如下假设:如果生成的图像很像真实图像,应该能够重建或预测它的三维结构,并通过添加另一判别网络实现这一目标。更具体地,所生成的图像不仅输入到判别器,也输入到表面法线的预测网络中。当完成了初始的样式-GAN和结构-GAN训练后,作者将它们合并,并执行端到端的共同学习:图像从 z^ 和 z~ 被产生,并用判别他们是真实还是生成的图像。
视觉表示的无监督学习的是计算机视觉领域中最具挑战性的问题之一。无监督学习有两种主要的方法:
第一个判别式方法,使用辅助任务来从没有标记的数据中ground truth,辅助任务通常是预测两个像素块的相对位置 [2],视频中自我运动的估计 [ 15,16 ] ,物理信号 [ 17,18,19 ];
无监督学习更常见的方法是使用一个生成框架。两种类型生成框架在过去被使用。非参数方法进行图像或补片与数据库中任务的匹配,如纹理合成 [20] 或超分辨率 [21]。
在本文中,作者开发图像的参数模型。一种常见的方法是去学习可用于重构图像的低维表示。一些例子包括深度自动编码器 [22,23 ] 或受限玻尔兹曼机(RBMs) [24,25,26,27,28]。然而,在大多数的上述情况很难产生新的图像,因为在潜在空间采样不是一件容易的事。最近提出的变分自动编码器(VAE) [10,11] 通过产生具有变采样图像的方法来解决这一问题。然而,这些方法只限于简单的数据集,如MNIST。为了生成具有更丰富的信息可解释图像,有人将VAE的条件扩展到说明文字 [29] 及图形编码 [30]。除了RBMs和自动编码器,最近的文献也提出了许多新颖的生成模型 [31,32,33,34]。例如,Dosovitskiy等 [31] 提出了用CNN生成椅子的图像。
在这项工作中,作者的模型基于由Goodfellow等人提出的生成对抗网络(GANs)建立 [9]。该框架由Denton等人扩展去生成图像 [35]。具体地,他们提出使用对抗网络的拉普拉斯金字塔的粗到细方案来产生图像。然而,训练这些网络仍然是棘手和不稳定。因此,DCGAN [13] 提出了良好的训练对抗网络的做法,并在图像生成上产生了有前途的效果。有多种扩展使用了条件变量 [36,37,38]。例如,Mathieu等人 [37] 提出基于视频的上一帧来预测未来的帧。在本文中,作者通过考虑三维结构和样式的因素,进一步简化了图像生成过程。
为了训练 S2GAN ,作者将表面损失与表面三维法线预测损失 [39,40,41,42] 相结合。学习过程中还有额外的约束。这还涉及到更好生成建模,将多重损失相结合的想法 [43,44,45]。例如,Makhzani等 [4] 提出了一种对抗自动编码器,在训练自动编码器的过程中将对抗损失作为隐含层的额外约束。最后,将图像分解成两个独立的部分的想法得到了很好的研究中 [46,47,48,49],这促使作者提出分解生成过程中结构和风格的想法。作者使用NYUv2的RGBD数据分解来学习 S2GAN 模型。
生成对抗网络(GAN)[9] 包含两个模型:生成器 G 和判别器 D 。生成器 G 从均匀分布噪声获取潜在的随机矢量 z 作为输入,并尝试生成逼真的图像。判别器 D 执行二元分类来区分的图像是来自生成器 G 还是一个真实图像。因此,这两个模型是互相竞争的(也就是对抗):生成器 G 将尝试生成使得判别器 D 难以区分真伪的图像,同时判别器 D 将学习如何避免被生成器 G 生成的图像所欺骗。
在形式上采用批量梯度下降的方式优化这两个网络,批的大小为 M 。给定样本 X=(X1,...,XM) 和一系列从均匀分布中采样的 Z=(z1,...,zM) 。
GAN的训练具有2步迭代过程:
(ⅰ)固定生成器 G 的参数,优化判别器 D 的参数;
(ⅱ)固定判别器 D 的参数,优化生成器 G 的参数。
训练 D 网络的损失函数如下所示,
LD(X,Z)=i=1∑M/2L(D(Xi),1)+i=M/2+1∑ML(D(G(zi)),0)(1)
在每个批中,图像一半是真实的,其余是在给定 zi 的情况下由生成器产生的 G(zi) 。 D(Xi)∈[0,1] 表示给定输入图像情况下的二元分类评分。 L(y∗,y)=−ylog(y∗)−(1−y)log(1−y∗) 是二元熵损失。因此损失函数的 公式1 优化判别器 D ,使之将真实图像判别为1,将生成的图像判别为0。另一方面,生成器 G 试图通过最小化如下的损失来欺骗判别器 D ,使之将生成的图像判定为真实图像,
LG(Z)=i=1∑ML(D(G(zi)),1)(2)
GAN和DCGAN直接生成从采样的 z 中生成图像。相反,本文基于生成的图像具有两个分量的事实:
(a)产生场景中的对象的基本结构;
(b)产生在该三维结构的上的纹理或样式。
根据这个简单的现象,作者将生成过程分为两个步骤:
(i)在结构GAN这个过程中从采样的 z^ 中产生表面法线;
(ii)样式GAN以表面法线和从均匀分布采样的潜在变量 z~ 为输入,来生成目标的图像。
按照以上两个步骤,根据RGBD数据和表面法线的Ground Truth来训练这两个模型。
作者可以直接应用GAN框架来学习如何生成表面法线图。输入到网络 G 将 z^ 从均匀分布取样,并输出是表面法线地图。使用100维向量来表示 z^ ,并输出尺寸 72×72×3 的图像(如 图2 )。判别器 D 将学习如何区分生成器 D 产生的表面法线图与实际的表面法线图。下面将陈述网络的架构。
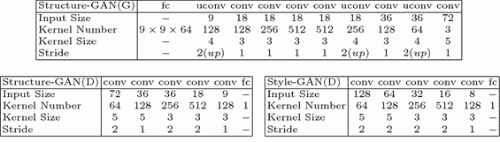
表1 网络架构。
上表:结构GAN的生成器;
下表:结构GAN的判别器(左)和样式GAN的判别器(右)。
“CONV”是指卷积层,“uconv”是部分跨度卷积(deconvolution)层,其中2(上)表示2倍的步幅跨度。“fc”指全连接层。

图2
左:4个生成的表面法线图。
右:两组Ground Truth表面法线图上的渲染结果,使用的是样式GAN而不逐像素地约束。
生成器网络 如 表1 (顶行)所示,作者给生成器赋予一个10层的模型。给定一个100维的 z^ 作为输入,这个输入被首先全连接到一个3D块(9×9×64)。然后在它的上面执行卷积操作,并最终产生表面法线图。值得注意的是,“uconv”表示部分步长(fractionally-strided)卷积 [1 ],也被称为deconvolution。作者按照在有关的设置 [13]使用批标准化 [50] 和ReLU**(除了最后层),在最后一层使用tanh**。
判别器网络 如 表1 所示,判别器使用六层的网络架构(左下)。使用图像作为输入,判别预测其是真实图像还是生成的图像。使用Leaky ReLU [51,52] 作为**函数,与文献 [13] 相同,但在这里不使用批量标准化。在作者的实验中发现,判别器网络很容易找到与批标准化的平凡解。
给定RGB图像和表面法线图,作者同时训练另一个GAN,以基于面法线来生成图像,称这种网络为样式GAN。作者首先将生成器网络修改为条件GAN [35,36]。条件信息,即表面法线图作为附加输入被施加给生成器 G 和判别器 D 。增强表面法线作为附加输入到 D 不仅使生成的图像看起来更真实,但也隐含地强制生成的图像与表面法线图相匹配。当训练判别器时,只考虑真正的RGB图像及其对应的表面法线作为正例。在给定更多的表面法线的情况下,样式GAN可以产生更高分辨率 (128×128×3) 的图像。
在形式上,给定一批RGB图像 X=(X1,...,XM) 和它们相应的表面法线图 C=(C1,...,CM) ,以及从噪声分布中抽样的 Z~=(z~1,...,z~M) 。生成函数 G(z~i) 被改写为 G(Ci,z~i) ;判别函数 D(Xi) 被改写为 D(Ci,Xi) 。
然后,原本 公式1 中判别器的损失被重写为,
LcondD(X,C,Z~)=i=1∑M/2L(D(Ci,Xi),1)+i=M/2+1∑ML(D(Ci,G(Ci,z~i)),0)(3)
原本 公式2 中生成器的损失被重写为,
LcondG(C,Z~)=i=1∑ML(D(Ci,G(Ci,z~i)),1)(4)
作者采用相同的迭代训练的方案,按照 图2 右边所示的那样,使用生成器 G 去生成图像。
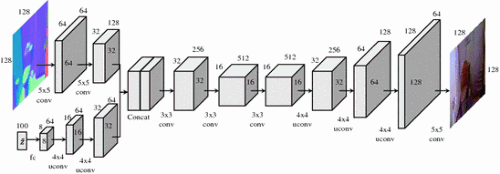
图3 样式GAN的网络架构
网络架构 生成网络如 图3 所示。给定一个 128×128×3 的表面法线图和一个 100维的 z~ 作为输入,它们被发给卷积层和deconvolution层,然后级联形成 32×32×192 的特征图。得到这些特征图后,进一步进行七层卷积和deconvolution。网络的输出是 128×128×3 的RGB图像。对于判别器,作者用了类似结构GAN的架构( 表1 右下角)。该网络的输入是表面法线和图像的级联。
样式-GaN可以使生成的图像看起来很真实,也强迫图像去隐含地匹配表面法线图。然而,如 图2 所示,图像有噪声并且边缘无法很好地与表面法线的地图的边缘对齐。因此,作者建议加入逐像素约束,引导生成器与表面法线输出相匹配。
假设生成的图像是足够真实的,那么它可以用于重建表面法线图。为了编码这个约束,作者训练一个网络估计表面法线。作者修改全卷积网络(FCN)[53] 训练分类损失 [39] 这项任务。更具体地说,量化表面法线与40个K均值聚类 [39,54] ,损失函数被定义为
LFCN(X,C)=K×K1i=1∑Mk=1∑K×KLs(Fs(Xi),Ci,k),(5)
其中 Ls 指softmax损失函数,表面法线的输出是 K×K 维,其中 K=128 ,与输入图像的大小相同。 Fk(Xi) 是第 i 个样本第 k 个像素的输出。 Ci,k(1≤k≤40) 是第 i 个样本第 k 个像素的标签。因此,损失在图像的每个像素上执行,以产生精确的表面法线。需要注意的是训练时FCN时使用提供了室内场景的图像和表面法线的ground truth的RGBD数据。该模型是从头开始训练的,而不使用ImageNet提前训练。
FCN架构 本节按照 [53] 的方法应用AlexNet [55] ,在最后3层有所修改。当给定所产生的 128×128 图像,首先在输入FCN之前将其上采样到 512×512 。在倒数第二和第三层中使用较小的核数(1024和512),最后一层是步幅2的deconvolution层,然后进一步上采样(四倍分辨率)以产生高质量的结果。
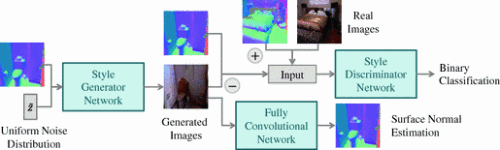
图4 样式-GAN。给定表面法线的ground truth和 z~ 作为输入,生成器学习如何产生RGB图像。监督来自两个网络:
判别器使用生成的图像、实际图像,及其所对应的法线图作为输入来执行分类;
FCN取所生成的图像作为输入,并且预测的表面法线图。
得到训练的FCN模型之后,可以用它作为对抗学习额外的约束。最终模型如 图4 所示。在训练期间,判别器 D 的分类损失梯度被传递到 G ,FCN估计的表面法线损失也可以通过所生成的图像来传递到 G 。这样一来,对抗损失 D 会使生成的图像看起来很真实,并且FCN会施加逐像素的限制,将生成的图像与表面法线图相对应。
在形式上,作者将 公式4 和 公式5 的损失方程结合起来作为生成器 G 的损失函数,
LmultiG(C,z~)=LcondG(C,Z~)+LFCN(G(C,Z~),C)(6)
其中 G(C,Z~) 表示给定一批表面法线图 C 和噪声 Z~ 所生成的图像。该模型的训练过程类似原来的对抗性学习,其中包括在每个三个迭代步骤:
(1)固定生成器 G ,根据 公式(3) 优化判别器 D 。
(2)固定FCN和判别器 D ,根据 公式6 优化生成器 G 。
(3)固定生成器 G ,使用所生成的图像和真实图像微调FCN。
需要注意的是FCN模型的参数在多任务学习的开始是固定的,也就是说,起初并不微调FCN。究其原因是起初生成的图像不是很好,所以给FCN输入不好的例子会使表面法线预测更糟糕。
将结构GAN和样式GAN分别训练后,将所有网络进行合并,共同训练他们。如 图5 所示,全模型包括结构GAN的面法线生成,然后样式GAN并基于它生成图像。值得注意的是,在被发送到样式GAN之前所,生成的法线图首先被传递到具有双线性插值的上采样层。因为作者不使用ground truth的表面法线贴图来生成图像,作者删除样式GAN的FCN约束。样式GAN的判别器使用生成的法线和图像作为负样本,使用Ground Truth法线和真实图像作为正样本。
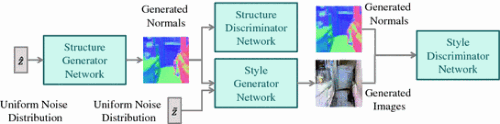
图5 完整的 S2GAN 模型。它可以在给定 z^,z~ 作为输入的情况下直接生成RGB图像。为了简单起见,在训练期间没有可视化正样例。在共同学习期间,样式GAN的损失也被向下传递到结构GAN。
对于结构-GAN,生成器网络不仅从结构GAN的判别器接收梯度,而且还从样式-GAN的生成器接受梯度。通过这种方式,网络被训练以产生逼真的、能够帮助生成更好的RGB图像的表面法线。在形式上,结构-GAN生成器网络的损失可以被表示为结合 方程2 和 方程4 ,
LjointG(Z^,Z~)=LG(Z)+λLcondG(G(Z^),Z~)(7)
其中 Z^=(z^1,...,z^M),Z~=(z~1,...,z~M), 表示两套从均匀分布中抽取的样本,分别用于结构GAN和风格GAN。 公式7 中的第一项表示结构-GAN的判别器的对抗损失,公式的第二项让样式GAN的损失也被传递下去。此处设定系数 λ=0.1 并在实验中用比样式GAN更小的学习率去学习结构GAN,这样就可以防止通过样式GAN生成RGB图像的任务过渡拟合于所产生的法线。在实验中发现,如果没有约束 λ 和学习率,损失 LG(Z~) 容易发散到较大的值,并且结构-GAN不能生成合理的表面法线图。
作者执行了两种类型的实验:
(a)定性和定量评价使用生成模型产生的图像的质量;
(b)通过将网络应用于不同的任务,如图像分类和物体检测,以评估无监督学习表示的质量。
数据集 在实验中,作者使用NYUv2数据集 [14] 。训练时使用原始视频数据,从249个训练视频场景中提取超过200K帧,然后计算表面法线 [39,42]。
参数设置 作者按照 [13] 的参数进行训练。在训练中用Adam优化模型 [56] ,momentum项 β1=0.5,β2=0.999 ,批量的大小 M=128 。所有网络的输入和输出被缩放到 [-1,1] (包括表面法线和RGB图像)。在单独训练样式GAN和结构GAN时,学习率设置为0.0002。作者用25个周期训练结构GAN。对于样式-GAN,首先用25个周期去拟合FCN模型,然后用5个周期去微调。对于共同学习,设置样式GAN的学习速率为 10−6 ,结构GAN的学习周期为 10−7 ,训练五个周期。
Baseline 就NYUv2训练集训练4个baseline模型:
(a)DCGAN [13]:它使用均匀噪声作为输入,并产生64×64的图像;
(b)DCGAN+ LAPGAN:在DCGAN之后训练LAPGAN,采用较低分辨率的图像作为输入,并且产生 128×128 图像,LAPGAN用于样式GAN相同的架构( 图3 和 表1 )。
(c)DCGANv2:训练一个与结构GAN相同架构的DCGAN(表 1)。
(d)DCGANv2 + LAPGAN:在DCGANv2之后,像B一样训练另一个LAPGAN。需要注意的是baseline(d)与本文的模型具有相同的模型复杂性。
样式GAN的可视化 在显示完整的 S2GAN 模型的图像生成结果之前,先在NYUv2测试集表面法线的Ground Truth上给出可视化样式GAN的结果。如 图6 的前三行所示,可以产生很好的与表面法线输入所对应的渲染效果。通过与原始RGB图像进行比较,作者的方法可以生成具有相同的结构图像的不同样式(照明,颜色,质地)。作者还就样式GAN的结果比较有/无像素方面的限制的情况,如 图7 所示,如果训练模型,而不逐像素的约束,输出是欠光滑、更有噪音的图像。
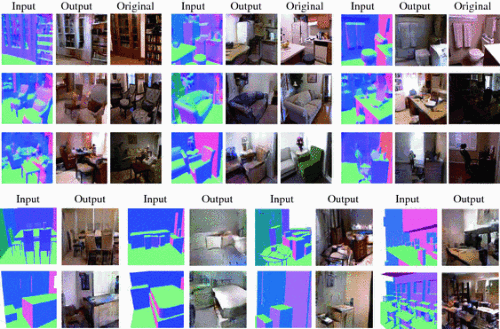
图6 一表面法线的ground truth为条件的样式GAN的结果(前3行)和合成的场景(后2行)。对于ground truth的法线,显示了输入法线、生成的图像、原始所对应的图像。

图7 逐像素约束与不逐像素约束的图像进行比较。
渲染场景的合成 样式GAN的一个应用是渲染合成的场景。作者使用 [57] 中的3D模型去生成合成场景。将场景对应于NYUv2测试集,并通过旋转、缩放进行一些修改。如 图6 的最后两行所示,可以得到三维模型非常逼真的渲染效果。
S2GAN 的可视化 现在展示整个生成模型的结果。在给定噪声 z^ 和 z~ ,全模型生成表面法线图(72×72)和RGB图像(128×128),如 图8(a) 所示。作者比较的baseline包括DCGAN 图8(b) 和DCGAN + LAPGAN 图8(c) 。作者的方法可以产生更加结构化的室内场景,也就是更容易找出对象的结构。作者还发现,LAPGAN对于改善定性结果没有太大帮助。

图8 (a)表面法线与 S2GAN 生成的图像;(b)中DCGAN的结果;(c)中DCGAN + LAPGAN的结果。
对于每一对图像,在左侧的结果是DCGAN生成的,右侧被施加以LAPGAN。
在隐空间徜徉 本文的模型的一个很大的优点是,它是可解释的。给定两个随机均匀分布中的向量 z^,z~ 作为结构和样式的网络输入。在这里,作者进行了两个实验:(一)固定 z~ (样式),并通过操作 z^ 图像的结构;(ⅱ)固定 z^ (结构),通过操作 z~ 改变图像的样式。具体地,给出一系列初始的 z^ 和 z~ ,随机从中选取十个点,对这些点每次增加0.1,进行6-7次。实验表明可以通过插值得到平滑的输出过渡,如 图9 所示。在 图9 的前两行的样本中,通过对 z^ 插值可以使立方体逐渐“长大”,但立方体的样式是不变的,因为固定了 z~ 。对于 图9 的最后一行,固定图像的结构,对 z~ 进行插值,图中房间的窗口正逐渐关闭。

图9 在隐空间徜徉:本文的潜在空间是更加可解释的,通过插值获得的输入产生的结果是平滑过渡的。
用户研究 作者收集了1000对本文的方法和DCGAN随机生成的图像,并让AMT工人来判断哪一个是更逼真的图像。71%的情况下,他们认为本文的方法生成更好的图像。

图10 生成图像的最近邻测试。
最近邻测试 为了估计生成的图像的新颖性,对它们进行了最近邻测试。将在Places数据集 [58] 上预先训练的AlexNet应用为特征提取器,从数据集中提取生成的图像以及真实图像(不论训练集还是测试集)的 Pool5 特征,结果显示为 图10 。每一行中,第一个图像由模型生成,该模型用于搜索。图中展示了前7个检索到的真实图像。虽然这些图像在语义上是相关的,但与最近邻相比,生成的图像具有不同的风格和结构。
为了定量地评价所生成的图像,作者将预先训练好的有监督的AlexNet [58] 施加到Places和ImageNet数据集 [59] ,对它们执行分类和检测。这种做法的动机是:如果生成的图像是不够现实的,state of art 的分类器和探测器的状态应该无法识别它们。然后作者比较了在开始时提到的三个基准方法:DCGAN,DCGANv2和DCGANv2 + LAPGAN,为每一个版本的GAN提供10K的图像并对其进行评估。
生成图像的分类 作者应用AlexNet [58] 对生成的图像进行分类。如果生成的图像不够真实,Place-AlexNet在分类过程中会产生较大的想赢。因此,可以使用Place-AlexNet的SOFTMAX输出的无穷范数 ∣∣⋅∣∣∞ 最大值(即,最大概率)表示图像质量。作者计算了所有生成的图像该指标的结果,并显示了不同模型的均值,如 图11(a) 所示。 S2GAN 比baseline好大约2%。
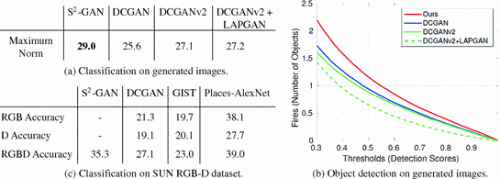
图11
(a)生成图像分类结果的最大范数;
(b)生成图像的目标检测在不同阈值下所检测到的数目;
(c)本文方法生成的图像在SUN RGB-D下的场景分类,并与其他方法进行比较(无微调)。
生成图像的物体检测 作者使用在NYUv2数据集微调的Fast-RCNN [60] 应用到ImageNet预训练的AlexNet上。然后将检测器应用到生成的图像上。如果图像足够现实,探测器应该检测到更多的对象(门,床,沙发,桌子,柜台等)。因此,此处要探讨的是图像的探测器能否找到更多的前景对象。作者绘制了如 图11(b) 所示的曲线(x轴表示检测阈值,y轴表示检测数的均值),表明检测器可以在 S2GAN 所产生的图像上检测到更多的前景物体。在阈值为0.3的情况下, S2GAN 产生的每张图像平均检测到2.2个物体,由DCGAN生成的图像平均每个图像检测到1.72个物体。
现在探索通过样式GAN的判别网络能否被迁移到场景分类、目标识别之类的任务,如场景分类和目标检测。因为该网络的输入是RGB图像和表面法线图,本文的模型可被应用于在RGBD数据识别任务。作者在SUN RGB-D数据集上的场景分类以及NYUv2数据集上的目标检测进行实验 [14,61,62,63] 。
场景分类 将SUN RGB-D数据集拆分为训练集和测试集,包括19个类别,训练图像有4852张,测试图像有4660张。作者使用本文的模型,以RGB图像和法线作为输入,提取在倒数第二层和最后一层的特征,并在SVM上训练,然后与DCGAN判别网络 [61] 以及两个baseline方法:GIST [64] 以及Place-AlexNet [58] 进行比较。对于只用RGB数据训练的网络,作者遵循 [61,65] 的方法,直接使用它们来对深度表示提取特征,然后从RGB和深度提取的特征输入到SVM分类器。值得注意的是,所有的实验都没有对数据集进行微调。如 图11(c) 所示,本文的模型是比DCGAN更好8.2%,距离Places-AlexNet还有3.7%。
目标检测 在此任务中,对NYUv2数据集RGBD对象检测。作者follow了Fast-RCNN的流程 [60] 并使用 [66] 提供的代码和参数设置。在这个例子中,作者使用表面法线来表示深度。为了实现模型检测,作者在卷积层的顶部堆叠了两层全连接层(4096维)并对网络进行端到端的微调。在这里与四个baseline模型进行了对比:具有相同架构从头开始训练的网络,用DCGAN预先训练的网络,DCGANv2,和用ImageNet预先训练的AlexNet。对于只用RGB数据预先训练的网络,作者对RGB和表面法线分别微调他们,并在测试期间平均它们的检测结果 [66] 。在除了AlexNet之外的模型上使用了批量标准化[50]。实验结果见 表2 。本文的做法比原来的训练方法提升了1.5%。

表2 在NYU测试集上的检测结果
作者提出将图像生成过程分解为样式与结构GAN,使模型更加可解释,且生成比baseline图像更逼真的图像。此外,本文的方法还可以以一种无监督的方式,学习RGBD的表示。
这项工作是由 ONR MURI N000141010934, ONR MURI N000141612007和谷歌。作者也要感谢David Fouhey和Kenneth Marino许多有益的讨论。
本文链接:http://task.lmcjl.com/news/5419.html


