变分自编码器(VAE)与生成对抗网络(GAN)是复杂分布上无监督学习最具前景的两类方法。本文中,作者在MNIST上对这两类生成模型的性能进行了对比测试。
本项目总结了使用变分自编码器(Variational Autoencode,VAE)和生成对抗网络(GAN)对给定数据分布进行建模,并且对比了这些模型的性能。你可能会问:我们已经有了数百万张图像,为什么还要从给定数据分布中生成图像呢?正如Ian Goodfellow在NIPS 2016教程中指出的那样,实际上有很多应用。我觉得比较有趣的一种是使用GAN模拟可能的未来,就像强化学习中使用策略梯度的智能体那样。
VAE
变分自编码器柯林斯用于对先验数据分布进行建模从名字上就可以看出,它包括两部分:。编码器和解码器编码器将数据分布的高级特征映射到数据的低级表征,低级表征叫作本征向量(latent vector)。解码器吸收数据的低级表征,然后输出同样数据的高级表征。
从数学上来讲,让X作为编码器的输入,z作为本征向量,X'作为解码器的输出。
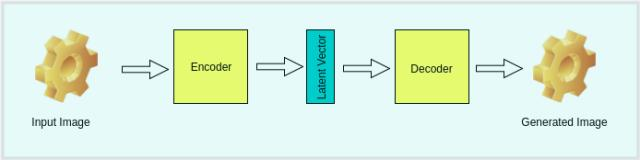
图1 VAE的架构
这与标准自编码器有何不同?关键区别在于我们对本征向量的约束。如果是标准自编码器,那么我们主要关注重建损失(即重建损失),即:
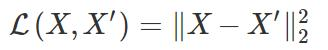
而在变分自编码器的情况中,我们希望本征向量遵循特定的分布,通常是单位高斯分布(unit Gaussian distribution),使下列损失得到优化:
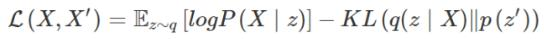
其中,P(Z')N(0,I)中我指单位矩阵(身份MATRX)中,q(z|X)是本征向量的分布。KL(A,B)是分布乙到甲的KL散度。
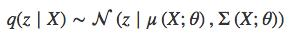
其中,状语从句:由神经网络来计算。
由于损失函数中还有其他项,因此存在模型生成图像的精度和本征向量的分布与单位高斯分布的接近程度之间存在权衡(折衷)。这两部分由两个超参数λ_1和λ_2来控制。
甘斯
GAN是根据给定的先验分布生成数据的另一种方式,包括同时进行的两部分:判别器和生成器。
判别器用于对“真”图像和“伪”图像进行分类,生成器从随机噪声中生成图像(随机噪声通常叫作本征向量或代码,该噪声通常从均匀分布(均匀分布)或高斯分布中获取)。
生成器的任务是生成可以以假乱真的图像,令判别器也无法区分出来。也就是说,生成器和判别器是互相对抗的。判别器非常努力地尝试区分真伪图像,同时生成器尽力生成更加逼真的图像,使判别器将这些图像也分类为「真」图像。
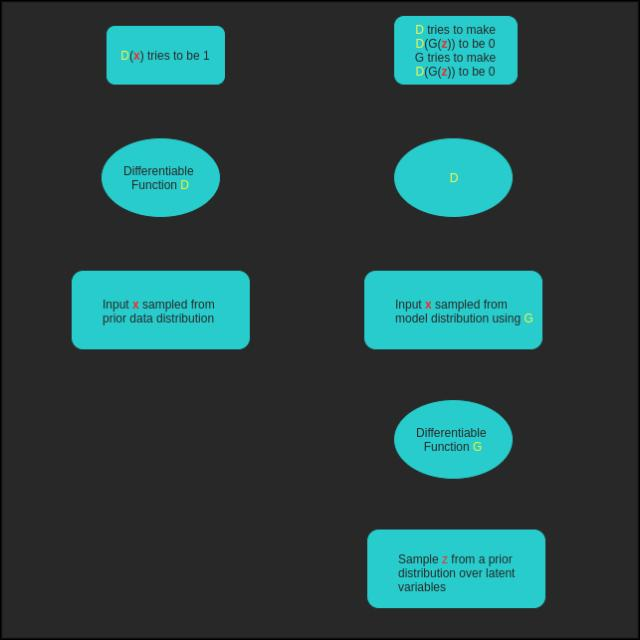
图2 GAN的典型结构
训练GAN的难点
训练GAN时我们会遇到一些挑战,我认为其中最大的挑战在于本征向量/代码的采样。代码只是从先验分布中对本征变量的噪声采样。有很多种方法可以克服该挑战,包括:使用VAE对本征变量进行编码,学习数据的先验分布。这听起来要好一些,因为编码器能够学习数据分布,现在我们可以从分布中进行采样,而不是生成随机噪声。
训练细节
我们知道两个分布p(真实分布)和q(估计分布)之间的交叉熵通过以下公式计算:
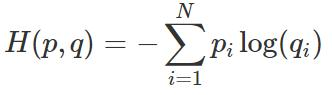
对于二元分类:
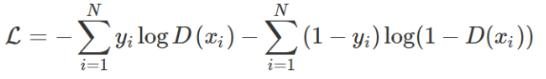
对于GAN,我们假设分布的一半来自真实数据分布,一半来自估计分布,因此:
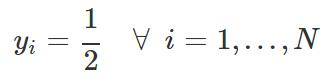
训练GAN需要同时优化两个损失函数。
按照极小极大值算法:
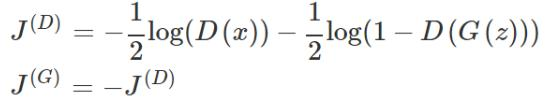
这里,判别器需要区分图像的真伪,不管图像是否包含真实物体,都没有注意力。当我们在CIFAR上检查GAN生成的图像时会明显看到这一点。
VAE生成的图像与GAN生成的图像相比,前者更加模糊。这个结果在预料之中,因为VAE生成模型的所有输出都是分布的平:均。为了减少图像的模糊,我们可以使用L1损失来代替L2损失。
我们可以重新定义判别器损失目标,使之包含标签。这被证明可以提高主观样本的质量。
如:在MNIST或CIFAR-10(两个数据集都有10个类别)。
参考:
原文链接:HTTPS://kvmanohar22.github.io/Generative-Models/
项目链接:HTTPS://github.com/kvmanohar22/Generative-Models
最新进展:关于变分自编码器(VAE)与生成对抗网络(GAN)的最新研究理论,参考我的上个博客。
在CVPR2018会议上,DeepMInd科学家分享了结合GANs和VAEs各自优势的GAN hybrids模型,两者不仅可以提高VAE的采样质量和改善表示学习,另一方面也可提高GAN的稳定性和丰富度,
本文链接:http://task.lmcjl.com/news/5420.html


