通过使用mnist(AI界的helloworld)手写数字模型训练集,了解下AI工作的基本流程。
本例子,要基于mnist数据集(该数据集包含了【0-9】的模型训练数据集和测试数据集)来完成一个手写数字识别的小demo。
mnist数据集,图片大小是28*28的黑白。包含了6w 训练数据和1w验证数据。
麻雀虽小五脏俱全。通过这个CV类型的demo需求,我们会学到神经网络模型。
从数据加载,到数据预处理,再到训练模型,保存模型。然后再通过模型来预测我们输入的图片数字。
通过整个过程下来,对于像我这样初识AI深度学习者来说,可以有一个非常好的体感。
我们通过keras+tensorflow2.0来上手。
keras 框架,提供了现成的方法来获取mnist数据集
(x_train_image, y_train_label), (x_test_image, y_test_label) = mnist.load_data()
这个方法会返回两组数据集
train_image,train_label ,训练数据集、分类标签
x_test_image, y_test_label,验证数据集、分类标签
要想让机器识别一个图片,需要对图片进行像素化,将像素数据转换成 张量 矩阵数据。
mnist.load_data() 返回的就是已经转换好的张量矩阵数据。
(在python中,通过NumPy多维数组表示。)
我们这个demo属于AI for CV 方向。
CV信息首先要像素化处理,拿到张量信息。
# 转换成一维向量 28*28=784
x_train = x_train_image.reshape(60000, 784)
x_test = x_test_image.reshape(10000, 784)
# 标准化0-1
x_Test_normalize = x_test.astype('float32') / 255
x_Train_normalize = x_train.astype('float32') / 255
通过reshape方法将三维转换成二维,同时通过量化将计算数据缩小但是不影响模型训练识别。
(mnist图片数据是黑白,位深为8位,0-255表示像素信息)。
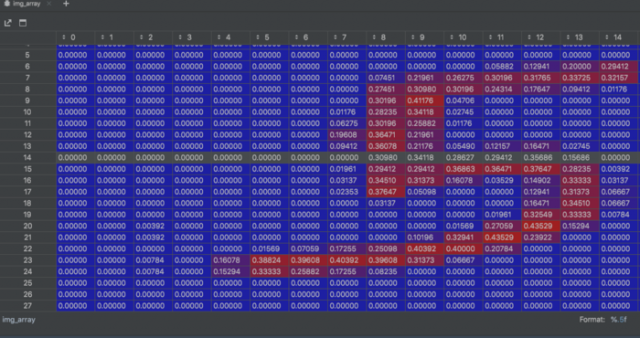
通过可视化,我们能大概看到图片的数字特征是怎么被感知到的。
同时将label标签数据转换成0-1的矩阵。
# 将训练集和测试集标签都进行独热码转化
y_TrainOneHot = np_utils.to_categorical(y_train_label)
y_TestOneHot = np_utils.to_categorical(y_test_label)
# 建立Sequential 模型
model = Sequential()
# 建立输入层、隐藏层
model.add(Dense(units=256,input_dim=784,kernel_initializer='normal',activation='relu'))
# 建立输出层
model.add(Dense(units=10,kernel_initializer='normal',activation='softmax'))
# 定义模型训练参数
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
定义神经网络模型参数。这里每一个参数都是一个非常深的学科,但是工程使用了解下就可以了。
# 开始训练
train_history = model.fit(x=x_Train_normalize, y=y_TrainOneHot,
validation_split=0.2, epochs=10, batch_size=200, verbose=2)
# 显示训练过程
show_train_history(train_history, 'accuracy', 'val_accuracy')
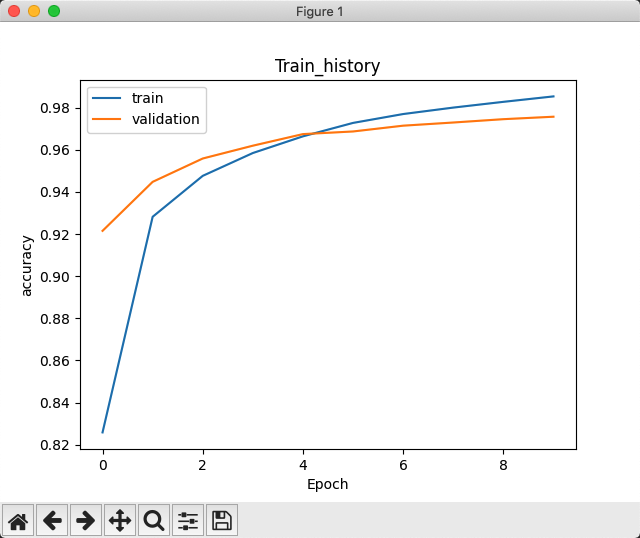
随着训练次数不断增加,整个精确度也越来越高。
我们看下训练过程的日志。
Epoch 1/10
240/240 - 3s - loss: 0.1211 - accuracy: 0.8309 - val_loss: 0.0564 - val_accuracy: 0.9228 - 3s/epoch - 11ms/step
Epoch 2/10
240/240 - 1s - loss: 0.0492 - accuracy: 0.9312 - val_loss: 0.0392 - val_accuracy: 0.9470 - 831ms/epoch - 3ms/step
Epoch 3/10
240/240 - 1s - loss: 0.0360 - accuracy: 0.9495 - val_loss: 0.0313 - val_accuracy: 0.9570 - 890ms/epoch - 4ms/step
Epoch 4/10
240/240 - 1s - loss: 0.0286 - accuracy: 0.9598 - val_loss: 0.0278 - val_accuracy: 0.9610 - 900ms/epoch - 4ms/step
Epoch 5/10
240/240 - 1s - loss: 0.0239 - accuracy: 0.9675 - val_loss: 0.0243 - val_accuracy: 0.9679 - 1s/epoch - 5ms/step
Epoch 6/10
240/240 - 1s - loss: 0.0204 - accuracy: 0.9723 - val_loss: 0.0224 - val_accuracy: 0.9698 - 1s/epoch - 5ms/step
Epoch 7/10
240/240 - 1s - loss: 0.0177 - accuracy: 0.9772 - val_loss: 0.0210 - val_accuracy: 0.9714 - 1s/epoch - 4ms/step
Epoch 8/10
240/240 - 1s - loss: 0.0155 - accuracy: 0.9805 - val_loss: 0.0201 - val_accuracy: 0.9729 - 984ms/epoch - 4ms/step
Epoch 9/10
240/240 - 1s - loss: 0.0137 - accuracy: 0.9833 - val_loss: 0.0189 - val_accuracy: 0.9742 - 1s/epoch - 5ms/step
Epoch 10/10
240/240 - 1s - loss: 0.0122 - accuracy: 0.9861 - val_loss: 0.0182 - val_accuracy: 0.9751 - 975ms/epoch - 4ms/step
可以看到,每一轮训练,loss 的值在逐步变小,accuracy 在逐步增加。
每一次训练,模型中的损失函数在计算出一个参数给到优化器进行反向传播,不断的调整神经元的权重。
模型训练好之后,需要用测试数据集来验证模型的准确度。
scores = model.evaluate(x_Test_normalize, y_TestOneHot)
print('accuracy=', scores[1])
accuracy= 0.975600004196167
mode.save()
model.save('model.h5') #也可以保存到具体的文件中
保存的模型里面具体是什么,了解神经网络原理之后,大概能明白。其实模型里最重要的是 神经元的权重值
这个demo的模型我放到这里了。
(https://gitee.com/wangqingpei/blogimages/blob/master/mnist-helloworld/test/model-mnist/model.h5)
我们准备几个手写的数字测试下。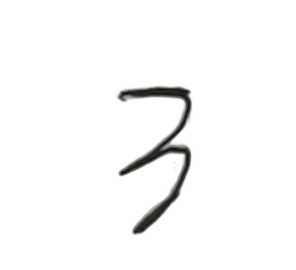
读取本地图片文件
def get_local_image():
img = Image.open('3.png')
img = img.convert('L').resize((28, 28))
img_array = np.array(img)
# 将像素值转换为0-1之间的浮点数
img_array = img_array.astype('float32') / 255.0
img_array_result = np.reshape(img_array, (1, 784))
return img_array_result
加载模型进行预测
def autoNumberWord():
model = load_model("/Users/wangqingpei/Downloads/test/model-mnist/model.h5")
img = get_local_image()
prediction = model.predict(img)
prediction_result = np.argmax(prediction)
print('本地文件预测:', prediction_result)
240/240 - 1s - loss: 0.0130 - accuracy: 0.9843 - val_loss: 0.0183 - val_accuracy: 0.9755 - 848ms/epoch - 4ms/step
Epoch 10/10
240/240 - 1s - loss: 0.0116 - accuracy: 0.9866 - val_loss: 0.0177 - val_accuracy: 0.9761 - 873ms/epoch - 4ms/step
313/313 [==============================] - 1s 2ms/step - loss: 0.0167 - accuracy: 0.9767
accuracy= 0.9767000079154968
1/1 [==============================] - 0s 116ms/step
Backend MacOSX is interactive backend. Turning interactive mode on.
本地文件预测: 3
在学习过程中,遇到问题要改变习惯,用chartGPT。~_~
在学习这个demo的时候,关于加载本地图片的地方我搞了半天不行,后来求助chartGPT,还是很方便的。
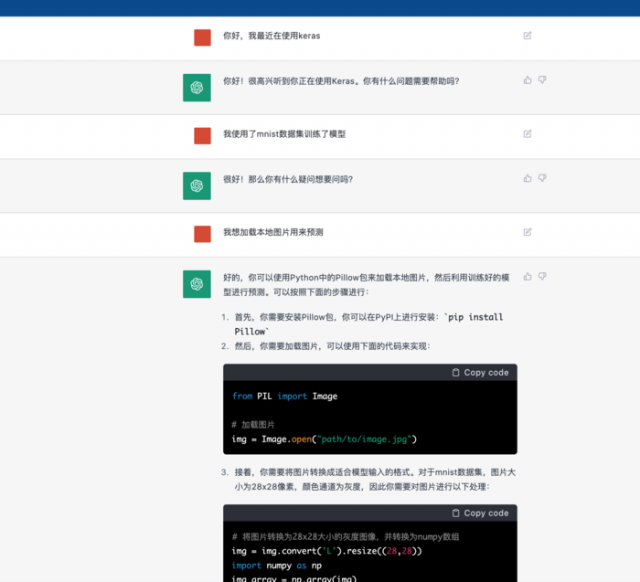

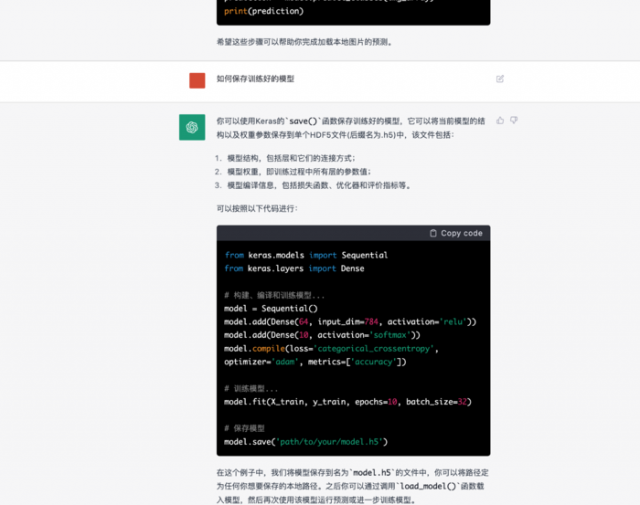
未来AI工具肯定是越来越产品化,易使用。
但是,要想跟AI对话,需要对特定的领域有一定的理解。Prompt Engineer 也一定是趋势。
本文链接:http://task.lmcjl.com/news/5576.html


