CVPR2018论文看点:基于度量学习分类与少镜头目标检测

简介
本文链接地址:https://arxiv.org/pdf/1806.04728.pdf
距离度量学习(DML)已成功地应用于目标分类,无论是在训练数据丰富的标准体系中,还是在每个类别仅用几个例子表示的few-shot场景中。在中,提出了一种新的DML方法,在一个端到端训练过程中,同时学习主干网络参数、嵌入空间以及该空间中每个训练类别的多模态分布。对于基于各种标准细粒度数据集的基于DML的目标分类,方法优于最先进的方法。此外,将提出的DML架构作为分类头合并到一个标准的目标检测模型中,证明了方法在处理few-shot目标检测问题上的有效性。与强基线相比,当只有少数训练示例可用时,在ImageNet-LOC数据集上获得了最佳结果。还为该领域提供了一个新的基于ImageNet数据集的场景benchmark,用于few-shot检测任务。
1、简介
提出了一种新的距离度量学习方法(DML),并证明了它在few shot目标检测和目标分类方面的有效性。用具有多个模态的混合模型表示每个类,并将这些模态的中心作为类的表示向量。与以往的方法不同,在单一的端到端训练过程中,同时学习了训练类别的嵌入空间、主干网络参数和代表性向量。
对于few shot目标检测,基于现代方法,该方法依赖于区域建议网络(RPN)来生成感兴趣的区域,并使用分类器“head”将这些RoI分类为目标类别之一或背景区域。为了通过几个训练示例学习一个健壮的检测器(单次检测示例见图1),建议使用提出的DML方法,用一个子网替换分类器头部,该子网学习为每个ROI计算类后验。这个子网的输入是由ROIs汇集的特征向量,通过将其嵌入向量与每个类别的一组代表进行比较,计算给定ROI的类后验。检测任务需要解决“开放集识别问题”,即将ROI分为结构化前景类别和非结构化背景类别。在这种情况下,联合端到端训练非常重要,因为对DML单独训练的背景ROI进行采样非常低效。

在few-shot检出实验中,引入了新的检测类别。这是通过使用从为这些类别提供的少量训练示例(k个用于k-shot检测的示例)的前景RoI中计算的嵌入向量来替换所学习的代表(对应于旧类别)来实现的。还研究了微调模型的效果和baseline的few-shot学习。与基线和以前的工作相比,关于few-shot检测任务的报告显示了有希望的结果,强调了联合优化主干和DML嵌入的有效性。图2概略地说明了few-shot检测方法。
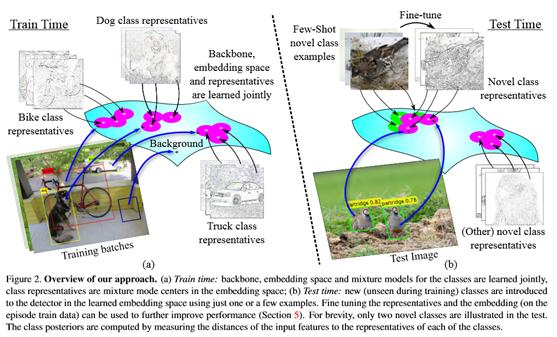
主要贡献有三个方面。首先,提出了一种新的子网结构,用于联合训练嵌入空间和该空间中的混合分布集,每个类别都有一个(多模态)混合。该体系结构对基于DML的目标分类和few-shot目标检测都有较好的改善作用。其次,提出了一种基于DML分类器头的目标检测器的设计方法,该方法能够识别新的类别,并将其转化为一种few-shot检测器。据所知,这是前所未有的。这可能是因为检测器训练批次通常被限制在每个GPU一个图像,不允许在类别内容方面进行批次控制。这种控制是目前任何使用情景训练的few-shot学习者所需要的。这反过来又使得在端到端训练的检测器中使用这些方法具有挑战性。在方法中,代表集充当“内部存储器”,在训练批次之间传递信息。第三,在few-shot分类文献中,评估方法的一种常见做法是通过平均多个少镜头任务实例(称为插曲)的性能来评估。为few-shot检测问题提供了这样一种情景基准,建立在具有挑战性的细粒度少镜头检测任务之上。
3、RePMet的结构
提出一种子网结构和相应的损失,使能够训练一个DML嵌入与多模态混合分布用于计算类后验在产生的嵌入空间。然后这个子网成为一个基于DML的分类器头部,它可以附加在分类器或检测主干的顶部。需要注意的是,DML子网是与生成功能的主干一起训练的。图3描述了所提出的子网的体系结构。
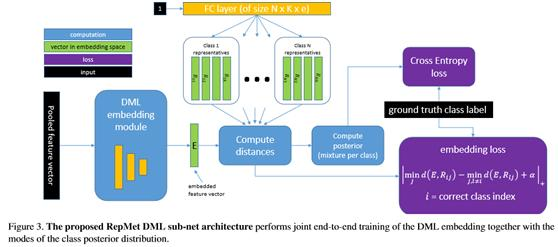
训练是分批组织的,但是为了简单起见,将把子网的输入称为由给定图像(或ROI)的主干计算的单个(池化的)特征向量。主干的例子有Inception V3或FPN(没有R-CNN)。首先使用了一个DML嵌入模块,它由几个具有批标准化(BN)和ReLU非线性的全连通(FC)层组成(在实验中使用了2-3个这样的层)。嵌入模块的输出是一个矢量,其中共同的作为一组额外的训练参数,持有一组“代表”。每个向量Rij表示学习判别混合分布在嵌入空间的第j阶模态的中心,对于总N类中的第i类。假设每个类的分布中有固定数量的K模(峰),所以1≤j≤K。
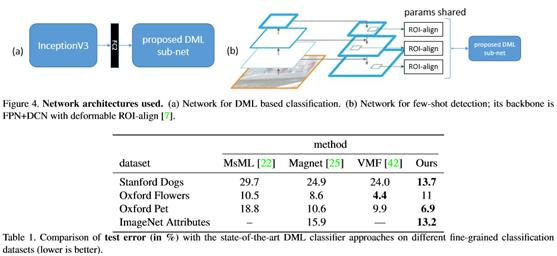
图4说明了所提出的DML子网是如何集成到用于基于DML的分类和few-shot检测实验的完整网络体系结构中的。
4、结果
已经评估了提出的DML子网在一系列分类和one-shot检测任务上的实用性。
4.1、基于度量学习的分类
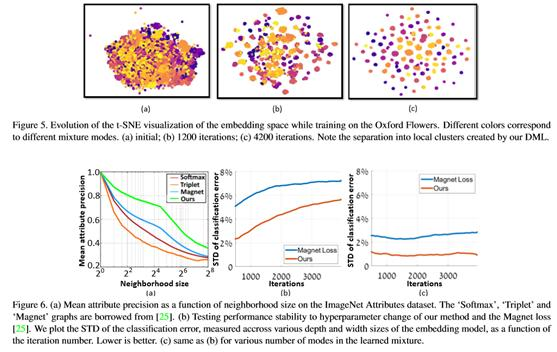
精细分类:在一组细粒度分类数据集上测试了方法,这些数据集广泛应用于最先进的DML分类工作中:Stanford Dogs、Oxford- iiit Pet、Oxford 102 Flowers和ImageNet Attributes。表1中报告的结果表明,方法在除Oxford Flowers外的所有数据集上都优于最先进的DML分类方法。图5显示了训练实例在嵌入空间中随训练迭代的t-SNE图的演变。
属性分布:验证了在DML分类训练之后,具有相似属性的图像在嵌入空间中更加接近(即使训练期间没有使用属性注释)。使用了与DML相同的实验方案。
对于这个数据集中的每个图像,对于每个属性,计算具有这个属性的邻居在不同邻域基数上的比例。图6(a)显示了与[25]和其他方法相比得到的改进结果。
图6(b)和图6©表明,与[25]相比,方法对超参数的变化具有更强的鲁棒性。这些图分别描述了每一种方法和每一次训练迭代时,通过改变嵌入网络体系结构得到的分类误差的标准差和每个类的代表数。
4.2、few-shot目标检测
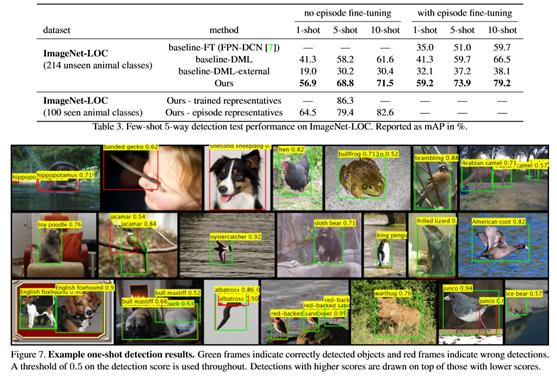
表3(在它看不见类的部分)中报告了对本文方法和一组不可见类的baseline的评估。对5路检测任务(500个这样的任务)计算平均平均精度(mAP),单位为%。通过联合收集和评估(计算精度和召回度的得分阈值)在所有500个测试集中检测到的全部包围框集合,每个包围框包含50张查询图像,计算出地图。此外,对于每一种测试方法(方法和基线),重复实验,同时仅在情节训练图像上微调网络的最后一层(对于模型和使用DML的基线,对最后一层嵌入层和代表进行微调)。表3还报告了微调后的结果。图7显示了单镜头检测测试结果的示例。
6、总结和结论
在这项工作中,提出了一种新的DML方法,与其他基于DML的方法相比,在目标分类方面取得了最先进的性能。利用这种方法,设计了一种最早的few-shot方法,与目前最先进的few-shot方法进行了比较。
本文链接:http://task.lmcjl.com/news/5731.html


