机器学习建模高级用法!构建企业级AI建模流水线,不同环节有序地构建成工作流(pipeline)。本文以『客户流失』为例,讲解如何构建 SKLearn 流水线。

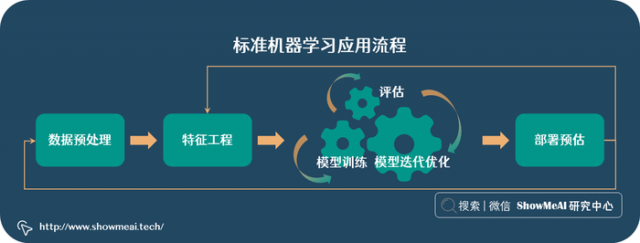
我们知道机器学习应用过程包含很多步骤,如图所示『标准机器学习应用流程』,有数据预处理、特征工程、模型训练、模型迭代优化、部署预估等环节。
在简单分析与建模时,可以对每个板块进行单独的构建和应用。但在企业级应用中,我们更希望机器学习项目中的不同环节有序地构建成工作流(pipeline),这样不同流程步骤更易于理解、可重现、也可以防止数据泄漏等问题。
常用的机器学习建模工具,比如 Scikit-Learn,它的高级功能就覆盖了 pipeline,包含转换器、模型和其他模块等。

但是,SKLearn 的简易用法下,如果我们把外部工具库,比如处理数据样本不均衡的 imblearn合并到 pipeline 中,却可能出现不兼容问题,比如有如下报错:
TypeError: All intermediate steps should be transformers and implement fit and transform or be the string ‘passthrough’ ‘SMOTE()’ (type <class ‘imblearn.over_sampling._smote.base.SMOTE’>) doesn’t
本文以『客户流失』为例,讲解如何构建 SKLearn 流水线,具体地说包含:
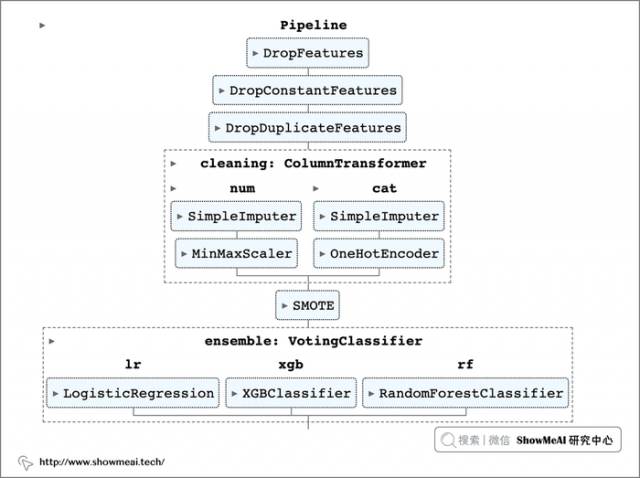
最终解决方案如下图所示:在一个管道中组合来自不同包的多个模块。
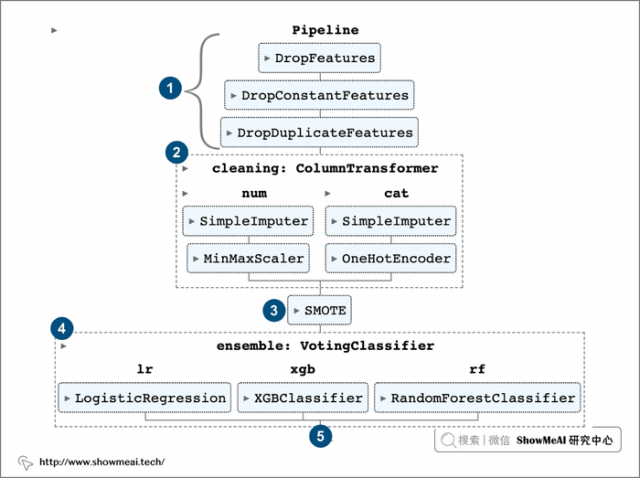
我们下面的方案流程,覆盖了上述的不同环节:

我们先导入所需的工具库。
# 数据处理与绘图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Sklearn工具库
from sklearn.model_selection import train_test_split, RandomizedSearchCV, RepeatedStratifiedKFold, cross_validate
# pipeline流水线相关
from sklearn import set_config
from sklearn.pipeline import make_pipeline, Pipeline
from imblearn.pipeline import Pipeline as imbPipeline
from sklearn.compose import ColumnTransformer, make_column_selector
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler
# 常数列、缺失列、重复列 等处理
from feature_engine.selection import DropFeatures, DropConstantFeatures, DropDuplicateFeatures
# 非均衡处理、样本采样
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
# 建模模型
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.metrics import roc_auc_score
from sklearn.inspection import permutation_importance
from scipy.stats import loguniform
# 流水线可视化
set_config(display="diagram")

我们这里用到的数据集来自 Kaggle 比赛 Newspaper churn。数据集包括15856条现在或曾经订阅该报纸的个人记录。
数据集包含人口统计信息,如代表家庭收入的HH信息、房屋所有权、小孩信息、种族、居住年份、年龄范围、语言;地理信息如地址、州、市、县和邮政编码。另外,用户选择的订阅期长,以及与之相关的收费数据。该数据集还包括用户的来源渠道。最后会有字段表征客户是否仍然是我们的订户(是否流失)。
我们先加载数据并进行预处理(例如将所有列名都小写并将目标变量转换为布尔值)。
# 读取数据
data = pd.read_excel("NewspaperChurn new version.xlsx")
#数据预处理
data.columns = [k.lower().replace(" ", "_") for k in data.columns]
data.rename(columns={'subscriber':'churn'}, inplace=True)
data['churn'].replace({'NO':False, 'YES':True}, inplace=True)
# 类型转换
data[data.select_dtypes(['object']).columns] = data.select_dtypes(['object']).apply(lambda x: x.astype('category'))
# 取出特征列和标签列
X = data.drop("churn", axis=1)
y = data["churn"]
# 训练集验证集切分
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
预处理过后的数据应如下所示:

我们构建的 pipeline 流程的第一步是『数据清洗』,删除对预测没有帮助的列(比如 id 类字段,恒定值字段,或者重复的字段)。
# 步骤1:数据清洗+字段处理
ppl = Pipeline([
('drop_columns', DropFeatures(['subscriptionid'])),
('drop_constant_values', DropConstantFeatures(tol=1, missing_values='ignore')),
('drop_duplicates', DropDuplicateFeatures())
])
上面的代码创建了一个 pipeline 对象,它包含 3 个步骤:drop_columns、drop_constant_values、drop_duplicates。
这些步骤是元组形态的,第一个元素定义了步骤的名称(如 drop_columns),第二个元素定义了转换器(如 DropFeatures())。
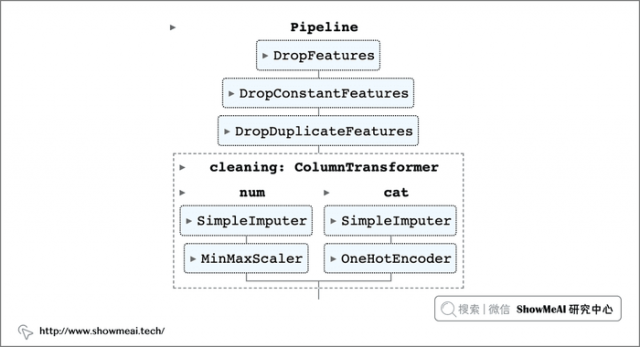
在前面剔除不相关的列之后,我们接下来做一下缺失值处理和特征工程。 可以看到数据集包含不同类型的列(数值型和类别型 ),我们会针对这两个类型定义两个独立的工作流程。
# 数据处理与特征工程pipeline
ppl = Pipeline([
# ① 剔除无关列
('drop_columns', DropFeatures(['subscriptionid'])),
('drop_constant_values', DropConstantFeatures(tol=1, missing_values='ignore')),
('drop_duplicates', DropDuplicateFeatures()),
# ② 缺失值填充与数值/类别型特征处理
('cleaning', ColumnTransformer([
# 2.1: 数值型字段缺失值填充与幅度缩放
('num',make_pipeline(
SimpleImputer(strategy='mean'),
MinMaxScaler()),
make_column_selector(dtype_include='int64')
),
# 2.2:类别型字段缺失值填充与独热向量编码
('cat',make_pipeline(
SimpleImputer(strategy='most_frequent'),
OneHotEncoder(sparse=False, handle_unknown='ignore')),
make_column_selector(dtype_include='category')
)])
)
])
添加一个名为clearning 的步骤,对应一个 ColumnTransformer 对象。
在 ColumnTransformer 中,设置了两个新 pipeline:一个用于处理数值型,一个用于类别型处理。 通过 make_column_selector 函数确保每次选出的字段类型是对的。
在『用户流失』和『欺诈识别』这样的问题场景中,一个非常大的挑战就是『类别不平衡』——也就是说,流失用户相对于非流失用户来说,数量较少。
这里我们会采用到一个叫做 im``blearn 的工具库来处理类别非均衡问题,它提供了一系列数据生成与采样的方法来缓解上述问题。 本次选用 SMOTE 采样方法来对少的类别样本进行重采样。
添加 SMOTE 步骤后的 pipeline 如下:
# 总体处理pipeline
ppl = Pipeline([
# ① 剔除无关列
('drop_columns', DropFeatures(['subscriptionid'])),
('drop_constant_values', DropConstantFeatures(tol=1, missing_values='ignore')),
('drop_duplicates', DropDuplicateFeatures()),
# ② 缺失值填充与数值/类别型特征处理
('cleaning', ColumnTransformer([
# 2.1: 数值型字段缺失值填充与幅度缩放
('num',make_pipeline(
SimpleImputer(strategy='mean'),
MinMaxScaler()),
make_column_selector(dtype_include='int64')
),
# 2.2:类别型字段缺失值填充与独热向量编码
('cat',make_pipeline(
SimpleImputer(strategy='most_frequent'),
OneHotEncoder(sparse=False, handle_unknown='ignore')),
make_column_selector(dtype_include='category')
)])
),
# ③ 类别非均衡处理:重采样
('smote', SMOTE())
])
在最终构建集成分类器模型之前,我们查看一下经过 pipeline 处理得到的特征名称和其他信息。
pipeline 对象提供了一个名为 get_feature_names_out() 的函数,我们可以通过它获取特征名称。但在使用它之前,我们必须在数据集上拟合。 由于第 ③ 步 SMOTE 处理仅关注我们的标签 y 数据,我们暂时忽略它并专注于第 ① 和 ② 步。
# 拟合数据,获取pipeline构建的特征名称和信息
ppl_fts = ppl[0:4]
ppl_fts.fit(X_train, y_train)
features = ppl_fts.get_feature_names_out()
pd.Series(features)
结果如下所示:
0 num__year_of_residence
1 num__zip_code
2 num__reward_program
3 cat__hh_income_$ 20,000 - $29,999
4 cat__hh_income_$ 30,000 - $39,999
...
12122 cat__source_channel_TMC
12123 cat__source_channel_TeleIn
12124 cat__source_channel_TeleOut
12125 cat__source_channel_VRU
12126 cat__source_channel_iSrvices
Length: 12127, dtype: object
由于独热向量编码,许多带着 cat_ 开头(代表 category)的特征名已被创建。
下一步我们训练多个模型,并使用功能强大的集成模型(投票分类器)来解决当前问题。
# 逻辑回归模型
lr = LogisticRegression(warm_start=True, max_iter=400)
# 随机森林模型
rf = RandomForestClassifier()
# xgboost
xgb = XGBClassifier(tree_method="hist", verbosity=0, silent=True)
# 用投票器进行集成
lr_xgb_rf = VotingClassifier(estimators=[('lr', lr), ('xgb', xgb), ('rf', rf)],
voting='soft')
定义集成模型后,我们也把它集成到我们的 pipeline 中。
# 总体处理pipeline
ppl = imbPipeline([
# ① 剔除无关列
('drop_columns', DropFeatures(['subscriptionid'])),
('drop_constant_values', DropConstantFeatures(tol=1, missing_values='ignore')),
('drop_duplicates', DropDuplicateFeatures()),
# ② 缺失值填充与数值/类别型特征处理
('cleaning', ColumnTransformer([
# 2.1: 数值型字段缺失值填充与幅度缩放
('num',make_pipeline(
SimpleImputer(strategy='mean'),
MinMaxScaler()),
make_column_selector(dtype_include='int64')
),
# 2.2:类别型字段缺失值填充与独热向量编码
('cat',make_pipeline(
SimpleImputer(strategy='most_frequent'),
OneHotEncoder(sparse=False, handle_unknown='ignore')),
make_column_selector(dtype_include='category')
)])
),
# ③ 类别非均衡处理:重采样
('smote', SMOTE()),
# ④ 投票器集成
('ensemble', lr_xgb_rf)
])
大家可能会注意到,我们在第1行中使用到的 Pipeline 替换成了 imblearn 的 imbPipeline 。这是很关键的一个处理,如果我们使用 SKLearn 的 pipeline,在拟合时会出现文初提到的错误:
TypeError: All intermediate steps should be transformers and implement fit and transform or be the string 'passthrough' 'SMOTE()' (type <class 'imblearn.over_sampling._smote.base.SMOTE'>) doesn't
到这一步,我们就把基本的 pipeline 流程构建好了。
我们构建的整条建模流水线中,很多组件都有超参数可以调整,这些超参数会影响最终的模型效果。对 pipeline 如何进行超参数调优呢,我们选用随机搜索 RandomizedSearchCV 对超参数进行调优,代码如下。
大家特别注意代码中的命名规则。
# 超参数调优
params = {
'ensemble__lr__solver': ['newton-cg', 'lbfgs', 'liblinear'],
'ensemble__lr__penalty': ['none', 'l1', 'l2', 'elasticnet'],
'ensemble__lr__C': loguniform(1e-5, 100),
'ensemble__xgb__learning_rate': [0.1],
'ensemble__xgb__max_depth': [7, 10, 15, 20],
'ensemble__xgb__min_child_weight': [10, 15, 20, 25],
'ensemble__xgb__colsample_bytree': [0.8, 0.9, 1],
'ensemble__xgb__n_estimators': [300, 400, 500, 600],
'ensemble__xgb__reg_alpha': [0.5, 0.2, 1],
'ensemble__xgb__reg_lambda': [2, 3, 5],
'ensemble__xgb__gamma': [1, 2, 3],
'ensemble__rf__max_depth': [7, 10, 15, 20],
'ensemble__rf__min_samples_leaf': [1, 2, 4],
'ensemble__rf__min_samples_split': [2, 5, 10],
'ensemble__rf__n_estimators': [300, 400, 500, 600],
}
# 随机搜索调参
rsf = RepeatedStratifiedKFold(random_state=42)
clf = RandomizedSearchCV(ppl, params,scoring='roc_auc', verbose=2, cv=rsf)
clf.fit(X_train, y_train)
# 输出信息
print("Best Score: ", clf.best_score_)
print("Best Params: ", clf.best_params_)
print("AUC:", roc_auc_score(y_val, clf.predict(X_val)))
解释一下上面代码中的超参数命名:
ensemble__ ):我们的 VotingClassifier 的名称lr__ ):我们集成中使用的模型的名称solver ):模型相关超参数的名称因为这里是类别不平衡场景,我们使用重复分层 k-fold ( RepeatedStratifiedKFold)。
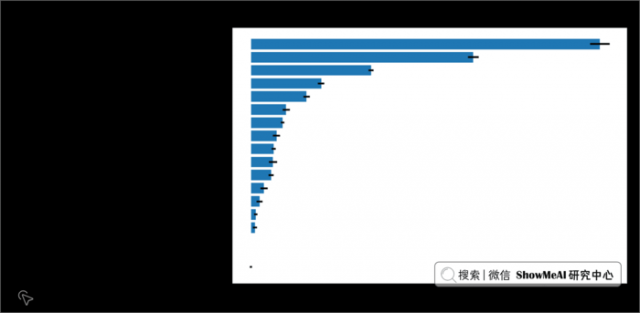
为了不让我们的模型成为黑箱模型,我们希望对模型做一些解释,其中最重要的是归因分析,我们希望了解哪些特征是重要的,这里我们对特征重要度进行绘制。
# https://inria.github.io/scikit-learn-mooc/python_scripts/dev_features_importance.html
# 绘制特征重要度
def plot_feature_importances(perm_importance_result, feat_name):
""" bar plot the feature importance """
fig, ax = plt.subplots()
indices = perm_importance_result['importances_mean'].argsort()
plt.barh(range(len(indices)),
perm_importance_result['importances_mean'][indices],
xerr=perm_importance_result['importances_std'][indices])
ax.set_yticks(range(len(indices)))
ax.set_title("Permutation importance")
tmp = np.array(feat_name)
_ = ax.set_yticklabels(tmp[indices])
# 获取特征名称
ppl_fts = ppl[0:4]
ppl_fts.fit(X_train, y_train)
features = ppl_fts.get_feature_names_out()
# 用乱序法进行特征重要度计算和排列,以及绘图
perm_importance_result_train = permutation_importance(clf, X_train, y_train, random_state=42)
plot_feature_importances(perm_importance_result_train, features)
上述代码运行后的结果图如下,我们可以看到特征 hh_income 在预测中占主导地位。 由于这个特征其实是可以排序的(比如 30-40k 比 150-175k 要小),我们可以使用不同的编码方式(比如使用 LabelEncoding 标签编码)。
以上就是完整的机器学习流水线构建过程,大家可以看到,pipeline 可以把不同的环节集成在一起,一次性运行与调优,代码和流程都更为简洁紧凑,效率也更高。

本文链接:http://task.lmcjl.com/news/5732.html


