本文是使用深度学习进行目标检测系列的第二篇,主要介绍SPP-net:Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition,即空间金字塔池化网络,用以解决卷积神经网络中固定输入大小的问题。
1. 传统的卷积神经网络的输入通常是一个固定大小(比如(224x224)的图像,因此当我们任意输入一张图像时需要对其进行缩放,作者认为这种手动的缩放可能会降低识别精度;
2. 在目标识别方面,使用深度神经网络对每个候选区域(如RCNN)抽取特征的时候,都需要重复的丢进网络里,即每来一个候选区域都进行warp(上文中RCNN用的方法,可以看成对候选区域进行缩放)操作得到相同的输入,放进CNN里抽取新的特征,这样导致计算量非常大:对于一张原始图像的候选区域有接近2000个,无疑开销很大。
3. 作者认为在卷积神经网络中卷积层并不需要固定大小的输入,而在全连接阶段需要保证输入具有固定的大小。这一点比较比较好理解,因为卷积层仅仅对图像进行局部连接,不管输入怎么能进行卷积操作,只是让特征图输出的大小和输入有关系;但是全连接层就不一样了,如果输入大小不固定肯定会出现矩阵维数不匹配的情况。
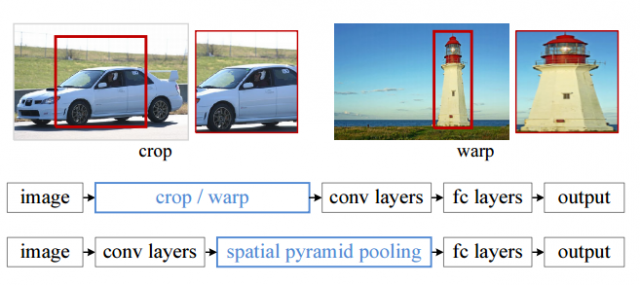
图1 传统的“crop”和“warp”方法与SPP的做法进行对比
为了展示卷积滤波器对于不同尺寸图像的作用情况,作者做了一个实验,使用AlexNet可视化第五个卷积层中某些滤波器得到的特征图的语义特征,如图2所示,图中(a)是Pascal VOC2007中的两张图像,(b)是某些滤波器得到的特征图,蓝色的箭头表示特征图中激活值比较强烈的区域以及对应的原始图像中的区域;(c)是使用相同的滤波器在ImageNet的图像中的响应情况,绿色框表示滤波器强烈的区域对应的感受野,这里的实验并没有输入同样大小的图像尺寸,但是可以看出这些滤波器依然能够反映出语义内容,比如左图的两个滤波器分别对车窗上方或者类似的区域、车胎附近圆形的或者类似的区域有强烈的反应;右图则对衣服的腋下或者类似的区域、盒子拐角处或者类似的区域有强烈的反应。

图2 特征图可视化
基于以上几点,作者设计了一个SPP层从最后的卷积层中提取特征,并统一处理大小使其适配全连接层的输入。
如第一部分所说,CNN中卷积层能够接受任意尺寸大小的输入,但是全连接层不可以,因此作者提出在CNN的最后一个卷积层后接入一个SPP(Spatial Pyramid Pooling)层代替我们平常使用的Max pooling层,SPP最主要的作用是接受任意尺寸的特征图,然后把特征图的像素按比例转化为一些固定数量的bin(可以),然后在这些bins里面进行池化。具体可以参见图3:
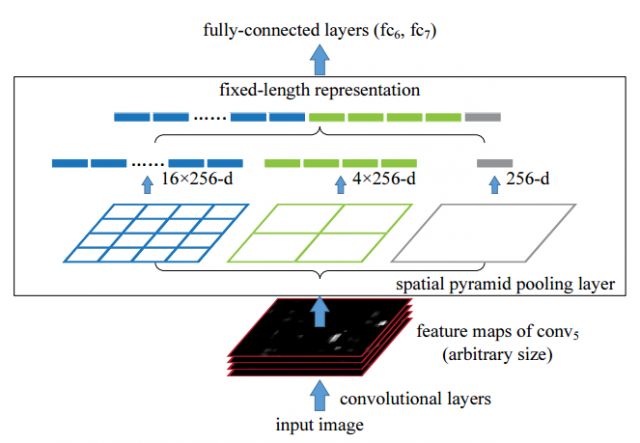
图3 SPP层示意
从图中可以发现,SPP用了三种不同方式来进行pooling,即对每张输入的特征图分别分成16个bins、4个bins和1个bins,然后再对每个bin里做池化,把这三种池化后的特征组合在一起就拼接成了一个新向量。有意思的是这里的1个bins恰好是某些paper中提到的“global pooling”层,能够起到降维、防止过拟合、提升精度等等作用。SPP层进行多尺度提取特征的方式其实借鉴了一些传统,比如SIFT;同时SPP本身也借鉴了BOW(Bag of Words,图像词袋模型)、SPM(Spatial Pyramid Matching)方法,这些其实很多多年前使用到的传统的特征提取或者匹配方法。
原始的RCNN进行检测时间开销的最大瓶颈在于特征提取阶段:对selective search抽取的约2000个候选框都需要重复的丢进整个网络;相比较而言,SPP对于整张图像在特征抽取阶段只需要做一次,即完整的图像先丢进网络,然后在特征图层面对selective search选取的候选区域使用SPP层进行池化,获取固定大小的维数,然后再进行全连接的计算,如图4所示,需要注意的是图4和图3非常像,实际上作者同时介绍了SPP在分类和目标检测中的应用,图3的示意更适用于分类,即对整张图像进行SPP池化获取统一的输出维度丢进全连接层;而图4更适用于目标检测,即在特征图层面对某个候选区域进行SPP池化,也就是图中的这个“window”。
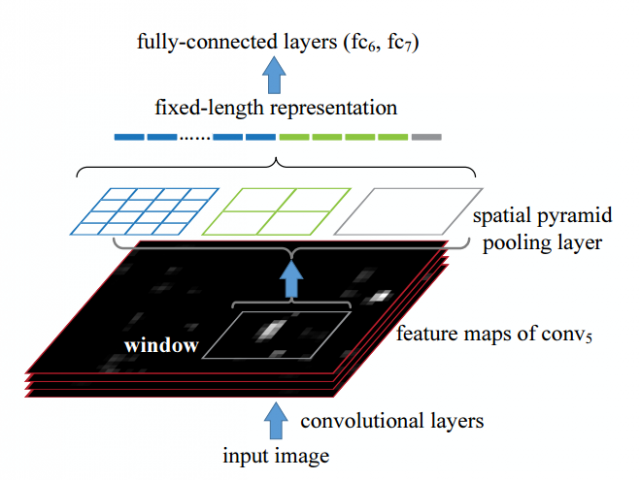
图4 SPP层用于目标检测示意
可以看出SPP进行目标检测时需要进行原始图像中候选区域的位置和特征图中候选区域位置的一个映射关系。为简化计算过程,简单来说,对于某一层大小为(p)的滤波器,进行(left lfloor frac{p}{2} right rfloor)(符号的意思是进行向下取整)的填充,那么对于特征图中响应中心坐标((x{}',y{}')),其对应原始图像中的坐标((x,y)=(Sx{}',Sy{}')),其中(S)为前面那些层的stride步伐的乘积。而对于给定的图像中的区域,获取特征图响应的左上角坐标为(x{}'=left lfloor frac{x}{s} right rfloor+1),右下角坐标为(x{}'=left lceil frac{x}{s} right rceil-1),而在padding不是(left lfloor frac{p}{2} right rfloor)的情况下需要添加关于(x)的偏移量。
SPP在基于RCNN的基础上改进进行目标检测,具体如下:
(1)使用“fast”模式的selective search对每张图像生成2000左右的候选区域;
(2)对每个候选区域利用SPP进行4个级别bins的池化,分别是(1times1)、(2times2)、(3times3)及(6times6)的总共50个bins进行池化,如此对于最后一个特征图的256个卷积核可以得到(256times50)的特征表示;
(3)把第二步中得到的特征接到全连接层中,然后对全连接层的输出使用二分类的SVM进行分类。
在训练SVM过程中,SVM的正类样本是真实的物体,而负类样本定义为和正类样本的IOU比最高不超过30%并且和其他的负类不超过70%的样本,和RCNN类似,SPP也选择使用hard negative mining模式的SVM进行训练,整个用于20个类训练SVM的时间小于1个小时;在测试阶段使用训练好的SVM为候选区域打分,最后使用阈值为0.3的NMS进行过滤。
在训练网络的过程中,分为前面的特征图的预训练和后接入的全连接层的微调,对于预训练部分作者提到了使用多尺度输入的训练方法,即resize原始图像成为不同尺度的输入(min(w,h)=sinS={480,576,688,864,1200}),然后得到第五个卷积层的特征图,接着进行特征融合再进行SPP池化;另外一种更好的方式是选择候选区域大小最接近(240times240)的那张图像进行输入并进行SPP提取特征。
为简化训练过程,微调仅针对全连接层。在第五个卷积层之后接入两个全连接层,最后再接入一个全连接层进行分类,类别数为21,即20+1,1是背景;对于最后一个全连接层使用标准差为0.01的高斯分布初始化参数,学习率由(1e-4)浮动到(1e-5);在微调阶段的正类样本定义为那些和真实的目标区域IOU比为([0.5,1))的样本,负类为([0.1,0.5))的样本,在每轮的mini-batch包含25%的正类样本;最后类似于RCNN也使用了bounding box回归进行偏差修正。最后作者给出了在VOC2007上的实验结果,如图5所示,其中sc表示作者使用的多尺度的训练方式,下图是作者在SPP的预训练模型上进行训练得到的结果(即作者先使用了SPP进行分类,然后拿分类的网络模型来进行检测微调)。可以看出SPP相比较RCNN最大的特点是训练速度的巨大提升。
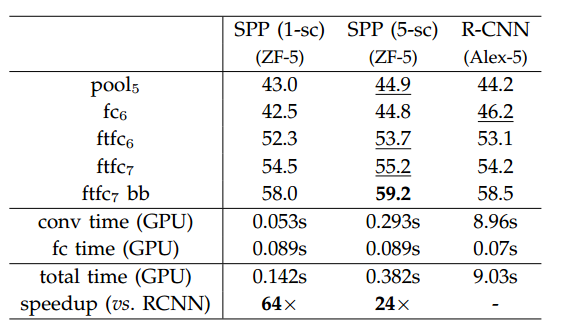
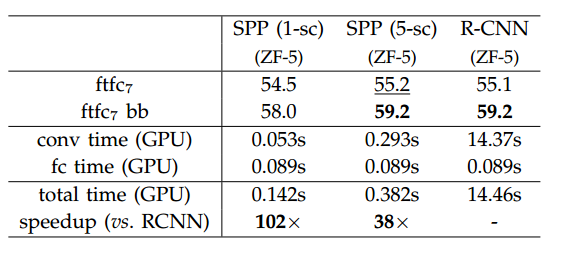
图5 VOC上SPP和RCNN实验比较
另外作者还针对试验中的其他对比方法进行了时间复杂度的分析,这里不再细说,参见原始paper。
SPP用于目标检测实际是在RCNN的基础上进行改进的,可以看出主要的目的是在时间上的巨大提升,但是从本质来看算法的精度并没有什么提升。需要注意的是SPP同样可以用于分类,作者花了很大篇幅讨论分类的SPP方法,考虑到本文是目标检测系列所以没有介绍到,下一篇主要介绍一个比较大的改进方法fast-rcnn。
本文链接:http://task.lmcjl.com/news/5763.html


