目录
这个图描述神经网络挺形象的
增加各个层
compiling:compile
train:fit
predict:predict
evaluate loss:evaluate
sequence这里比较方便一点
以输入为2,输出层只有1为例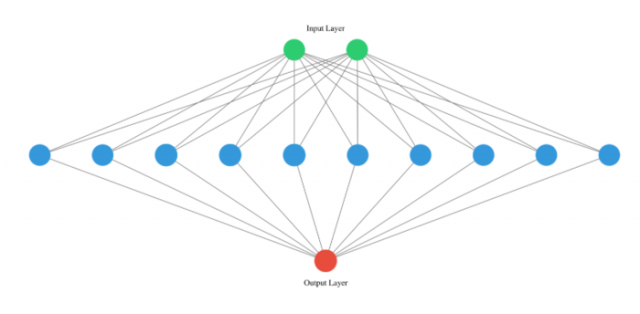
# Import the Sequential model and Dense layer
from keras.models import Sequential
from keras.layers import Dense
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer with 10 neurons
model.add(Dense(10, input_shape=(2,), activation="relu"))
# Add a 1-neuron output layer
model.add(Dense(1))
# Summarise your model
model.summary()
一个比较完整的栗子
# Instantiate a Sequential model
model = Sequential()
# Add a Dense layer with 50 neurons and an input of 1 neuron
model.add(Dense(50, input_shape=(1,), activation='relu'))
# Add two Dense layers with 50 neurons and relu activation
model.add(Dense(50, activation='relu'))
model.add(Dense(50, activation='relu'))
# End your model with a Dense layer and no activation
model.add(Dense(1))
# Compile your model
model.compile(optimizer = 'adam', loss = 'mse')
print("Training started..., this can take a while:")
# Fit your model on your data for 30 epochs
model.fit(time_steps, y_positions, epochs = 30)
# Evaluate your model
print("Final lost value:",model.evaluate(time_steps, y_positions))
# Predict the twenty minutes orbit
twenty_min_orbit = model.predict(np.arange(-10, 11))
# Plot the twenty minute orbit
plot_orbit(twenty_min_orbit)
那输出的dense层的激活函数是sigmoid就可以了
# Import the sequential model and dense layer
from keras.models import Sequential
from keras.layers import Dense
# Create a sequential model
model = Sequential()
# Add a dense layer
model.add(Dense(1, input_shape=(4,), activation='sigmoid'))
# Compile your model
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
# Display a summary of your model
model.summary()
# Train your model for 20 epochs,假设这里划分好了数据集
model.fit(X_train, y_train, epochs=20)
# Evaluate your model accuracy on the test set
accuracy = model.evaluate(X_test, y_test)[1]
# Print accuracy
print('Accuracy:',accuracy)
多分类的话,就是输出的激活函数不是sigmoid了,而是softmax了
所以写一个多分类的流程
就是
定义输入层和隐藏层
定义更多的隐藏层
定义输出层,输出层的结点数量大于一
定义一个含有三个隐藏层神经网络,输出为4分类
# Instantiate a sequential model
model = Sequential()
# Add 3 dense layers of 128, 64 and 32 neurons each
model.add(Dense(128, input_shape=(2,), activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
# Add a dense layer with as many neurons as competitors
model.add(Dense(4, activation='softmax'))
# Compile your model using categorical_crossentropy loss
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# Train your model on the training data for 200 epochs
model.fit(coord_train, competitors_train, epochs=200)
# Evaluate your model accuracy on the test data
accuracy = model.evaluate(coord_test, competitors_test)[1]
# Print accuracy
print('Accuracy:', accuracy)
# Transform into a categorical variable
darts.competitor = pd.Categorical(darts.competitor)
# Assign a number to each category (label encoding)
darts.competitor = darts.competitor.cat.codes
# Print the label encoded competitors
print('Label encoded competitors: n',darts.competitor.head())
<script.py> output:
Label encoded competitors:
0 2
1 3
2 1
3 0
4 2
Name: competitor, dtype: int8
# Transform into a categorical variable
darts.competitor = pd.Categorical(darts.competitor)
# Assign a number to each category (label encoding)
darts.competitor = darts.competitor.cat.codes
# Import to_categorical from keras utils module
from keras.utils import to_categorical
# Use to_categorical on your labels
coordinates = darts.drop(['competitor'], axis=1)
competitors = to_categorical(darts.competitor)
# Now print the to_categorical() result
print('One-hot encoded competitors: n',competitors)
dense的结点不是1了,而是大于1的,激活函数还是sigmoid
# Instantiate a Sequential model
model = Sequential()
# Add a hidden layer of 64 neurons and a 20 neuron's input
model.add(Dense(64, input_shape=(20,), activation='relu'))
# Add an output layer of 3 neurons with sigmoid activation
model.add(Dense(3, activation='sigmoid'))
# Compile your model with adam and binary crossentropy loss
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
# Train for 100 epochs using a validation split of 0.2
model.fit(sensors_train, parcels_train, epochs=100, validation_split=0.2)
# Predict on sensors_test and round up the predictions
preds = model.predict(sensors_test)
preds_rounded = np.round(preds)
# Print rounded preds
print('Rounded Predictions: n', preds_rounded)
# Evaluate your model's accuracy on the test data
accuracy = model.evaluate(sensors_test, parcels_test)[1]
# Print accuracy
print('Accuracy:', accuracy)
回调函数使用
回调函数是一个函数的合集,会在训练的阶段中所使用。你可以使用回调函数来查看训练模型的内在状态和统计。你可以传递一个列表的回调函数(作为 callbacks 关键字参数)到 Sequential 或 Model 类型的 .fit() 方法。在训练时,相应的回调函数的方法就会被在各自的阶段被调用。keras.cn
在每个training/epoch/batch结束时,如果我们想执行某些任务,例如模型缓存、输出日志、计算当前的auc等等,Keras中的callback就派上用场了。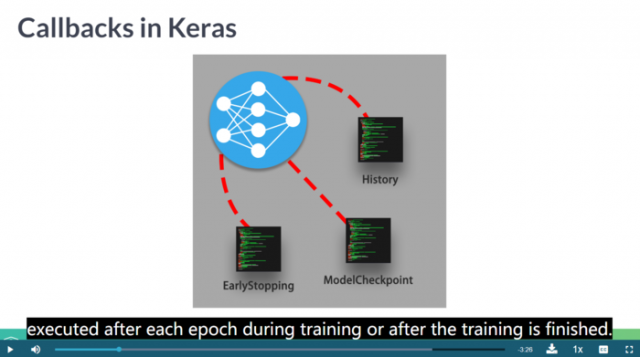
callbacks可以用来做这些事情:
模型断点续训:保存当前模型的所有权重
提早结束:当模型的损失不再下降的时候就终止训练,当然,会保存最优的模型。
动态调整训练时的参数,比如优化的学习速度。
等等
earlystopping和modelcheckpoint抄书侠
import keras
# Callbacks are passed to the model fit the `callbacks` argument in `fit`,
# which takes a list of callbacks. You can pass any number of callbacks.
callbacks_list = [
# This callback will interrupt training when we have stopped improving
keras.callbacks.EarlyStopping(
# This callback will monitor the validation accuracy of the model
monitor='acc',
# Training will be interrupted when the accuracy
# has stopped improving for *more* than 1 epochs (i.e. 2 epochs)
patience=1,
),
# This callback will save the current weights after every epoch
keras.callbacks.ModelCheckpoint(
filepath='my_model.h5', # Path to the destination model file
# The two arguments below mean that we will not overwrite the
# model file unless `val_loss` has improved, which
# allows us to keep the best model every seen during training.
monitor='val_loss',
save_best_only=True,
)
]
# Since we monitor `acc`, it should be part of the metrics of the model.
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
# Note that since the callback will be monitor validation accuracy,
# we need to pass some `validation_data` to our call to `fit`.
model.fit(x, y,
epochs=10,
batch_size=32,
callbacks=callbacks_list,
validation_data=(x_val, y_val))
monitor为选择的检测指标,我们这里选择检测'acc'识别率为指标,patience就是我们能让训练停止变好多少epochs才终止训练,这里选择了1,而modelcheckpoint就起到了存储最优的模型的作用,filepath为我们存储的位置和模型名称,以.h5为后缀,monitor为检测的指标,这里我们检测验证集里面的成功率,save_best_only代表我们只保存最优的训练结果。
而validation_data就是给定的验证集数据。
学习率减少callback抄书侠
callbacks_list = [
keras.callbacks.ReduceLROnPlateau(
# This callback will monitor the validation loss of the model
monitor='val_loss',
# It will divide the learning by 10 when it gets triggered
factor=0.1,
# It will get triggered after the validation loss has stopped improving
# for at least 10 epochs
patience=10,
)
]# Note that since the callback will be monitor validation loss,
# we need to pass some `validation_data` to our call to `fit`.
model.fit(x, y,
epochs=10,
batch_size=32,
callbacks=callbacks_list,
validation_data=(x_val, y_val))
翻译一下,就是如果连续10个批次,val_loss不再下降,就把学习率弄到原来的0.1倍。
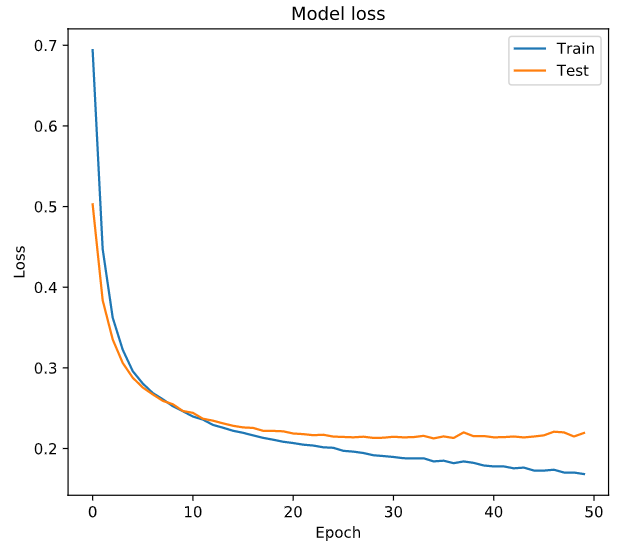
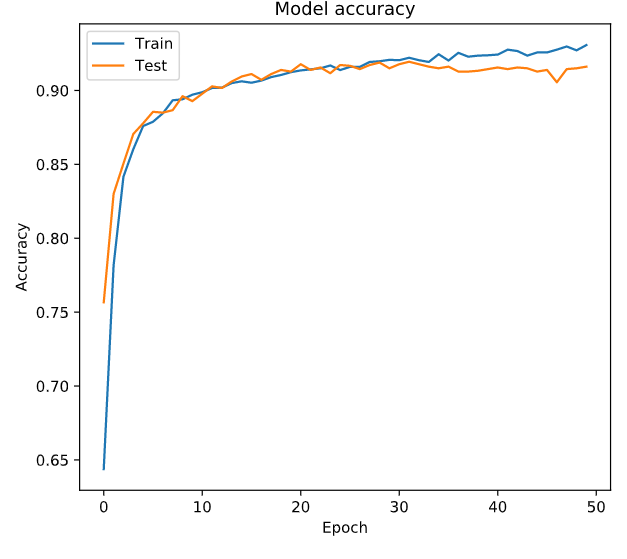
# Train your model and save its history
history = model.fit(X_train, y_train, epochs = 50,
validation_data=(X_test, y_test))
# Plot train vs test loss during training
plot_loss(history.history['loss'], history.history['val_loss'])
# Plot train vs test accuracy during training
plot_accuracy(history.history['acc'], history.history['val_acc'])
# Import the early stopping callback
from keras.callbacks import EarlyStopping
# Define a callback to monitor val_acc
monitor_val_acc = EarlyStopping(monitor='val_acc',
patience=5)
# Train your model using the early stopping callback
model.fit(X_train, y_train,
epochs=1000, validation_data=(X_test, y_test),
callbacks=[monitor_val_acc])
当验证集的误差不再发生变化的时候,停止迭代,并且保存模型为hdf5格式
# Import the EarlyStopping and ModelCheckpoint callbacks
from keras.callbacks import EarlyStopping, ModelCheckpoint
# Early stop on validation accuracy
monitor_val_acc = EarlyStopping(monitor = 'val_acc', patience = 3)
# Save the best model as best_banknote_model.hdf5
modelCheckpoint = ModelCheckpoint('best_banknote_model.hdf5', save_best_only = True)
# Fit your model for a stupid amount of epochs
history = model.fit(X_train, y_train,
epochs = 10000000,
callbacks = [monitor_val_acc, modelCheckpoint],
validation_data = (X_test, y_test))
h5格式
学习曲线
查看损失函数的curve和accuary的curve
# Instantiate a Sequential model
model = Sequential()
# Input and hidden layer with input_shape, 16 neurons, and relu
model.add(Dense(16, input_shape = (64,), activation = 'relu'))
# Output layer with 10 neurons (one per digit) and softmax
model.add(Dense(10, activation = 'softmax'))
# Compile your model
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
# Test if your model works and can process input data
print(model.predict(X_train))
# 这里划分数据集的方式是通用的,不过这个是留出法
# Train your model for 60 epochs, using X_test and y_test as validation data
history = model.fit(X_train, y_train, epochs=60, validation_data=(X_test, y_test), verbose=0)
# Extract from the history object loss and val_loss to plot the learning curve
plot_loss(history.history['loss'], history.history['val_loss'])
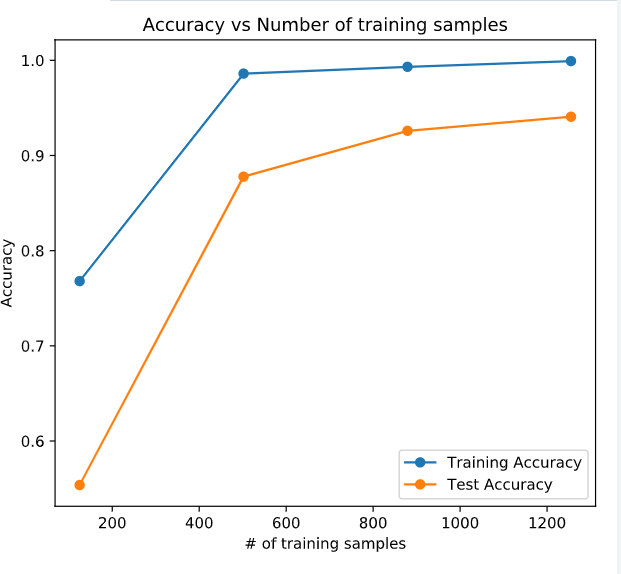
for size in training_sizes:
# Get a fraction of training data (we only care about the training data)
X_train_frac, y_train_frac = X_train[:size], y_train[:size]
# Reset the model to the initial weights and train it on the new data fraction
model.set_weights(initial_weights)
model.fit(X_train_frac, y_train_frac, epochs = 50, callbacks = [early_stop])
# Evaluate and store the train fraction and the complete test set results
train_accs.append(model.evaluate(X_train_frac, y_train_frac)[1])
test_accs.append(model.evaluate(X_test, y_test)[1])
# Plot train vs test accuracies
plot_results(train_accs, test_accs)
神经网络的内部就是一堆的数相乘,求和的过程,这个图很形象了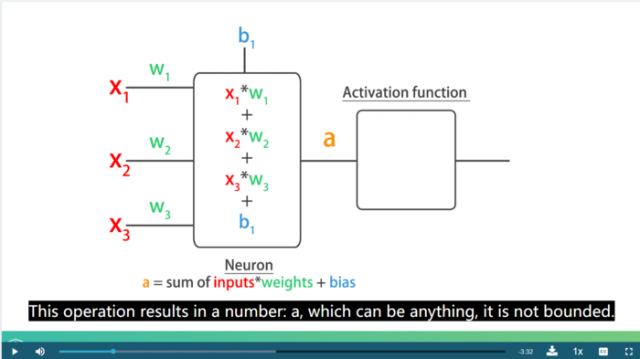
分批的尺寸和每批的正则化
批量标准化层 (Ioffe and Szegedy, 2014)。
在每一个批次的数据中标准化前一层的激活项, 即,应用一个维持激活项平均值接近 0,标准差接近 1 的转换。
# Import batch normalization from keras layers
from keras.layers import BatchNormalization
# Build your deep network
batchnorm_model = Sequential()
batchnorm_model.add(Dense(50, input_shape=(64,), activation='relu', kernel_initializer='normal'))
batchnorm_model.add(BatchNormalization())
batchnorm_model.add(Dense(50, activation='relu', kernel_initializer='normal'))
batchnorm_model.add(BatchNormalization())
batchnorm_model.add(Dense(50, activation='relu', kernel_initializer='normal'))
batchnorm_model.add(BatchNormalization())
batchnorm_model.add(Dense(10, activation='softmax', kernel_initializer='normal'))
# Compile your model with sgd
batchnorm_model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
# Train your standard model, storing its history
history1 = standard_model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, verbose=0)
# Train the batch normalized model you recently built, store its history
history2 = batchnorm_model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, verbose=0)
# Call compare_acc_histories passing in both model histories
compare_histories_acc(history1, history2)
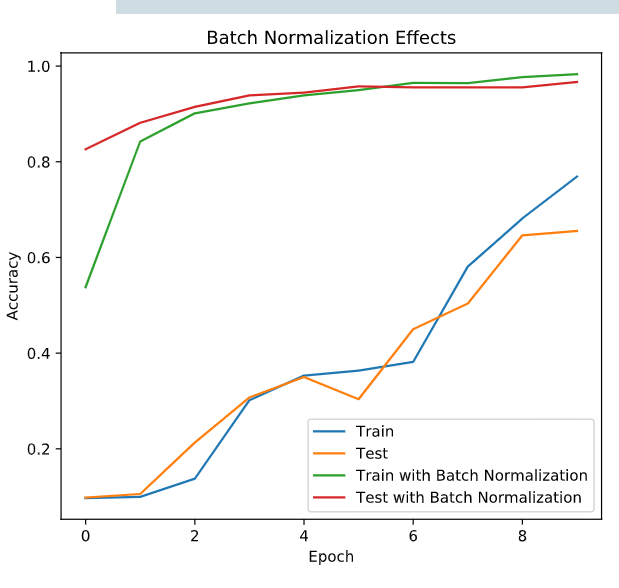
超参数调节
# Import KerasClassifier from keras wrappers
from keras.wrappers.scikit_learn import KerasClassifier
# Create a KerasClassifier
model = KerasClassifier(build_fn = create_model, epochs = 50,
batch_size = 128, verbose = 0)
# Calculate the accuracy score for each fold
kfolds = cross_val_score(model, X, y, cv = 3)
# Print the mean accuracy
print('The mean accuracy was:', kfolds.mean())
# Print the accuracy standard deviation
print('With a standard deviation of:', kfolds.std())
目前来看是一样的
这里等熟悉keras包之后回看
Keras是一个模型级的库,提供了快速构建深度学习网络的模块。Keras并不处理如张量乘法、卷积等底层操作。这些操作依赖于某种特定的、优化良好的张量操作库。Keras依赖于处理张量的库就称为“后端引擎”。Keras提供了三种后端引擎Theano/Tensorflow/CNTK,并将其函数统一封装,使得用户可以以同一个接口调用不同后端引擎的函数
Theano是一个开源的符号主义张量操作框架,由蒙特利尔大学LISA/MILA实验室开发。
TensorFlow是一个符号主义的张量操作框架,由Google开发。
CNTK是一个由微软开发的商业级工具包。keras中文文档
from keras import backend as K
导入后K模块提供的所有方法都是abstract keras backend API。
# Start with a sequential model
autoencoder = Sequential()
# Add a dense layer with the original image as input
autoencoder.add(Dense(32, input_shape=(784, ), activation="relu"))
# Add an output layer with as many nodes as the image
autoencoder.add(Dense(784, activation="sigmoid"))
# Compile your model
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# Take a look at your model structure
autoencoder.summary()
<script.py> output:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 32) 25120
_________________________________________________________________
dense_2 (Dense) (None, 4) 132
=================================================================
Total params: 25,252
Trainable params: 25,252
Non-trainable params: 0
_________________________________________________________________
<script.py> output:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 32) 25120
_________________________________________________________________
dense_2 (Dense) (None, 784) 25872
=================================================================
Total params: 50,992
Trainable params: 50,992
Non-trainable params: 0
_________________________________________________________________
增加一层encoder编码
# Build your encoder
encoder = Sequential()
encoder.add(autoencoder.layers[0])
# Encode the images and show the encodings
preds = encoder.predict(X_test_noise)
show_encodings(preds)
# Predict on the noisy images with your autoencoder
decoded_imgs = autoencoder.predict(X_test_noise)
# Plot noisy vs decoded images
compare_plot(X_test_noise, decoded_imgs)


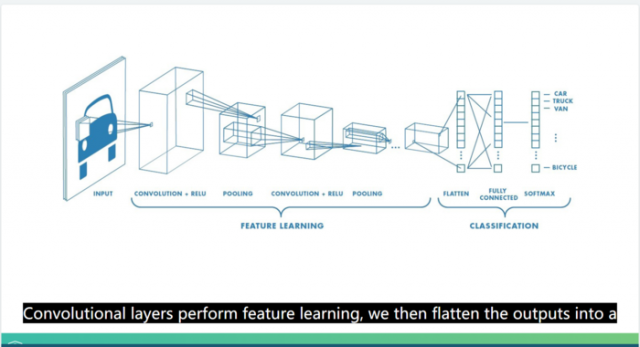
卷积神经网络
图是三维张量
# Import the Conv2D and Flatten layers and instantiate model
from keras.layers import Conv2D,Flatten
model = Sequential()
# Add a convolutional layer of 32 filters of size 3x3
model.add(Conv2D(32, input_shape=(28, 28, 1), kernel_size=3, activation='relu'))
# Add a convolutional layer of 16 filters of size 3x3
model.add(Conv2D(16, kernel_size=3, activation='relu'))
# Flatten the previous layer output
model.add(Flatten())
# Add as many outputs as classes with softmax activation
model.add(Dense(10, activation='softmax'))
# Obtain a reference to the outputs of the first layer
layer_output = model.layers[0].output
# Build a model using the model input and the first layer output
first_layer_model = Model(inputs = model.input, outputs = layer_output)
# Use this model to predict on X_test
activations = first_layer_model.predict(X_test)
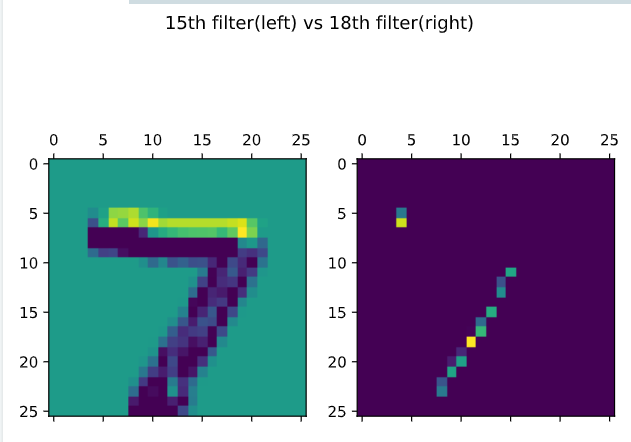
# Plot the first digit of X_test for the 15th filter
axs[0].matshow(activations[0,:,:,14], cmap = 'viridis')
# Do the same but for the 18th filter now
axs[1].matshow(activations[0,:,:,17], cmap = 'viridis')
plt.show()
预训练模型
# Split text into an array of words
words = text.split()
# Make lines of 4 words each, moving one word at a time
lines = []
for i in range(4, len(words)):
lines.append(' '.join(words[i-4:i]))
# Instantiate a Tokenizer, then fit it on the lines
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
# Turn lines into a sequence of numbers
sequences = tokenizer.texts_to_sequences(lines)
print("Lines: n {} n Sequences: n {}".format(lines[:5],sequences[:5]))
# Import the Embedding, LSTM and Dense layer
from keras.layers import Embedding, LSTM, Dense
model = Sequential()
# Add an Embedding layer with the right parameters
model.add(Embedding(input_dim=vocab_size, output_dim=8, input_length=3))
# Add a 32 unit LSTM layer
model.add(LSTM(32))
# Add a hidden Dense layer of 32 units and an output layer of vocab_size with softmax
model.add(Dense(32, activation='relu'))
model.add(Dense(vocab_size, activation='softmax'))
model.summary()
<script.py> output:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 3, 8) 352
_________________________________________________________________
lstm_1 (LSTM) (None, 32) 5248
_________________________________________________________________
dense_1 (Dense) (None, 32) 1056
_________________________________________________________________
dense_2 (Dense) (None, 44) 1452
=================================================================
Total params: 8,108
Trainable params: 8,108
Non-trainable params: 0
_________________________________________________________________

本文链接:http://task.lmcjl.com/news/5764.html


