啊啊啊,又来吐槽面试了。某天下午,突然接到一个面试电话,你好,我是**公司的,请问你有10-20分钟的时间吗?接下来我们将进行一个面试。完全没有预料的好吗?自己一点准备也没有,边听问题边回忆好吗?想着怎么回答。当时看过的论文已经很久了,忘记了好吗?还记得当时面试官问我你知道DCGAN吗?你看过CycleGAN没有?我当时就没办法讲清楚那些论文所做的工作。另外还有一次问我看过的最新的工作是什么?有没有看过什么论文?我也不知道如何回答。说了一个CycleGAN,面试官说那都是去年的好吗?当时深深地意识到自己对前沿的关注力度还不够呀,即便我关注过,如果面试官让我在短时间内讲一讲论文的要点,恐怕我也没办法。我觉得做笔记还是很有必要的,现在就只有慢慢地填坑了。当然这只是第一步,第二步是你自己能不能根据论文复现别人的工作,注意是复现,而不是把别人share出来的代码直接跑一跑,复现真的很有帮助,会有助于你去弄懂论文中的每一个细节。之前试着去复现了一篇论文的工作,虽然遇到了一点问题卡住了,但是真的学到了很多东西,明显感觉自己进步了,但是还是有很长的一段路要走啊。好了,先回到DCGAN这里来。
DCGAN全名是deep convolutional generative adversarial networks。
先介绍一下背景,从大量没有标记的数据集中学习到可以利用的特征表示是一个活跃的研究领域。在计算机视觉领域,利用这些实际生活无限量的没有标记的图像和视频学习到好的中间表示,然后将这些特征可以用到许多于监督的学习任务中比如说图像分类。这篇论文就提出了一个方法通过训练生成对抗网络来建立好的图像表示,然后利用generator和discriminator网络的某些部分作为特征提取器用于其他的任务。
这篇论文是实验分析部分除了说明DCGAN所学到的表示特征在其他任务中的应用,还尝试着去理解和可视化GAN究竟学到了什么以及multi-layer GAN的中间表示。
Architecture guidelines for stable Deep Convolutional GANs:
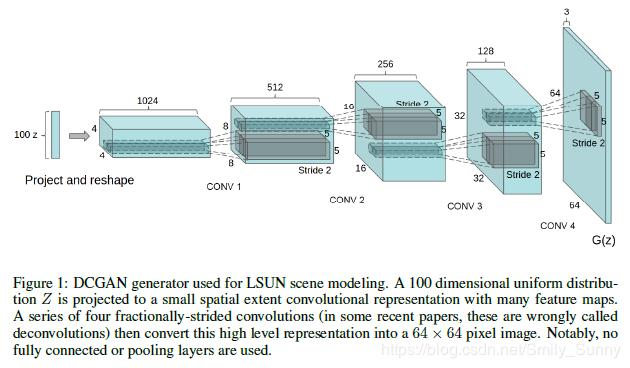
(1)对discriminator来说,用strided convolution代替池化层;对generator来说,用fractional-strided convolution代替池化层;
(2)在generator和discriminator使用batchnorm;
(3)对于更深的网络结构,去掉了隐藏的全连接层;
(4)在generator中使用ReLU**函数,除了**层使用Tanh;
(5)在discriminator中的所有层都使用LeakyReLU。
关于改进的分析:
关于第(1)点,这样做的话可以使网络去学习它自己的空间降采样,而不是使用那些决定性意义的空间池化函数(比如最大池化,就选取的是最大值的那个点);
关于第(2)点,通过batch normalization使得每个神经元的输入服从0均值,单位方差的分布,这有助于处理因为不好的初始化导致的训练问题和帮助更深的模型中的梯度流动(也就是梯度消失)。这对于很深的generator在刚开始训练时是很关键的,这可以避免GAN中的模式塌陷问题,也就是阻止generator将所有样本折叠成一个样本。但是有一个问题就是说如果对所有层都运用batch normalization的话,会导致样本的震荡和模型的不稳定。这可以通过避免在generator的输出层和discriminator的输入层运用batchnorm避免。
关于第(3)点是倾向于在卷积层的顶端减轻全连接层。这方面最有说服力的一个例子是在目前state of the art的图像分类模型中全局平均池化的使用(Going deeper into neural networks. http://googleresearch.blogspot.com/2015/06/inceptionism-going-deeper-into-neural.html. Accessed: 2015-06-17.)本文的作者发现全局平均池化增加了模型的稳定性但是影响了模型的收敛速度,一个折衷的办法就是将最高卷积特征直接连接到generator的输入和discriminator的输出。
具体说来,对于generator来说,也就是GAN的第一层(由于是一个矩阵的乘法运算被称作全连接层)以服从均匀分布的噪声作为输入,输出会被reshape成一个4维的张量,被用作后续堆叠的卷积层的开端。对于discriminator来说,最后一层卷积层的输出会被展开,然后输入一个sigmoid函数。也就是只在generator和discriminator的开头和结尾使用一层这样的层就好了。那个折中办法的意思也就是说在generator的第一个卷积层开始之前使用一个这样的连接,在discriminator最后一个卷积层之后使用一个这样的连接。
关于第(4)点,作者通过实验观察到使用一个有界的**函数会使得模型学习得更快,从而收敛并且会使得训练的分布覆盖色彩空间。
关于第(5)点,作者发现leaky recitified activation效果更好,尤其是对于更高清晰度的模型。
关于作者提到的这些点我觉得是可以在自己的GAN网络中去尝试,当自己模型训练遇到问题的时候,就需要看看别人是怎么做的啦。
Details of adversarial training
(1)在对数据集的处理上,作者写的是no pre-processing was applied to training images besides scaling to the range of the tanh activateion function[-1,1].
我觉得这个是很重要的一点,如果你generator最后一层的**函数使用的是tanh,那就按照作者说的这样做吧。我的理解是**函数tanh当x大于或者小于一定范围的时候就很容易达到饱和,求导的话梯度几乎没有什么变化,可能会导致梯度消失的问题。
(2)权重初始化方面:所有的权重都采用的是(0,0.02)的正态分布;
(3)LeakyReLU的leak斜率设的是0.2;
(4)使用的是Adam优化器,作者对默认的learning rate和momentum term 进行了调整,learning rate = 0.0002,
关于数据集方面,这篇论文还是做了一些准备工作的,比如LSUN数据冗余的去除,faces数据集的准备(自己去爬取,以及识别出人脸)。这个细节可以自己去看论文。我们重点放在分析等方面。
1、Empirical Validation of DCGANs capabilities
一种常见的评估无监督表示学习算法的方法是将它们作为一个特征提取器用到有监督的数据集上然后评估在这些特征上拟合出的线性模型的性能。这里使用的是DCGAN中discriminator的特征,因为discriminator是以图片作为输入的。
classifying CIFAR-10 using GANs as a feature extractor
classifying SVHN digits using GANs as a feature extractor
2、Investigating and Visualizing the Internals of the Networks
(1) walking in the latent space
(2) visualizing the discriminator features
(3) manipulting the generator representation
看了一下实验部分,它的设计还是蛮巧妙的,很有意思的一个工作,大家还是看论文吧。
本文链接:http://task.lmcjl.com/news/5767.html


