转自http://mp.weixin.qq.com/s?__biz=MzU0NTAyNTQ1OQ==&mid=2247485402&idx=2&sn=d4c0d65b75ebca219397cf2263ca480a&chksm=fb727b06cc05f21082d6e469496e7155974415250404d1e7294730cf0a6130feadf27b73d082&mpshare=1&scene=23&srcid=0201GEiLSp6WiKUb8bybEBKk#rd
今天是二月的第一天,是一个月的新的开始,估计现在有很多学生都已经进入了漫长的寒假,希望你们在寒假空闲之余可以慢慢来阅读我们的精彩推送。今天我们将的就是目标检测,说到目标检测,很多人都会想到许多经典的框架,说明你们都很厉害,对该领域都有深入的了解,今天主要聊聊细粒度的事!
首先我们来看两幅简单的图片组:
图1 黑脚信天翁
图2 黑背信天翁
通过这两组图像,粗略观察会发现差别不是很大,所以我们仔细的去看,就能发现一些细节性的差别。由此,引出了细粒度类别检测。平时,我们在做目标检测的过程中,也可以通过引入该思想,让我们对目标只提取高判别性的特征,提高目标特征的表达,提升检测结果的精度。
对了,今天主要说的内容都是基础简单,如果你是该领域的大佬,请跳过直接去做你自己的科研,或者当做休闲一刻快速浏览,谢谢!
先来说一个案例:
两类不同的鸟,但是差别很小,主要应该就在眼部,怎么通过一只小鸟去寻找到对应的类别呢?
结果其实就是通过寻找出具有判别区域部分:
1、Pose-normalized correspondence
其中,黄色就是我们平时所说的边界框,红色就是语义区域部分。
首先就是找到这些部分,然后就可以通过特征表示出来。
下面是之前该领域的一些工作总结:
深度学习的进展:
2、深度表达用于细粒度
[Donahue et.al. ICML 2014] DPM detec7ons + DeCAF feature
[Zhang et.al. CVPR 2014] poselet detec7ons + deep network training from scratch
RNN
3、新框架
Object and Part detectors
边界框约束:
高斯混合:
首先得到边界框和部分的注解:
然后归一化:
为每个部分先生成高斯混合
最后得到:
细粒度类别犹如下面的过程:
4、对比
DPM模型:
Multiple components
Deforma7on cost is a percomponent Gaussian prior.
R-CNN is a single-component model, mo7va7ng our MG and NP constraint. (New)
Nonparametric prior on keypoint configuration space.
Our non-parametric prior uses nearest neighbors on appearance space. (New)
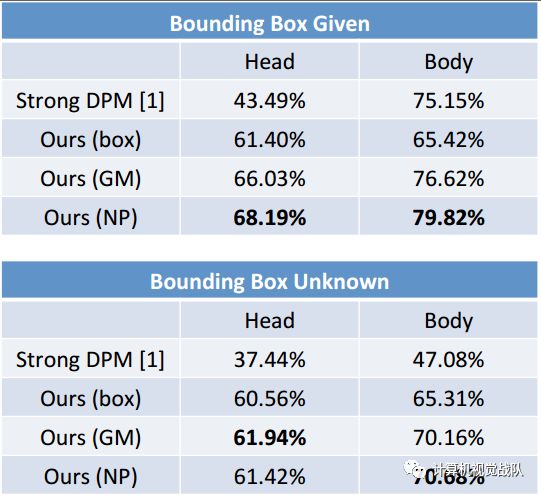
5、结果
数据集:CUB-200-2011 (12k张图像,200类,15个点)
[1] Berg et.al. POOF: Part-based one-vs-one features for fine-grained
categoriza7on, face verifica7on, and ahribute es7ma7on. In CVPR 2013.
[2] Chai et.al. Symbio7c segmenta7on and part localiza7on for fine-grained
categoriza7on. In ICCV 2013.
[3] Gavves et.al. Fine-grained categoriza7on by alignments. In ICCV 2013.
[4] Donahue et.al. DeCAF: A deep convolu7onal ac7va7on feature for
generic visual recogni7on. In ICML 2014.
微调过程其实对实验结果有很大的帮助,也做了一组对比试验来证明其有效性。
接下来就是部分区域定位的结果:
如果大于0.5就设定其为正确的。
[1] Azizipour et.al. Object detec7on using strongly-supervised deformable part models. In ECCV 2012.
后期其实还可以基于多区域部分来进行特征表达,这样检测的效果会更好一些。
本文链接:http://task.lmcjl.com/news/6031.html