1.1 RoI pooling
1.2 End-to-End model
3、R-CNN、SPPNet、Fast R-CNN效果对比
4、Fast R-CNN总结
引言:
SPPNet的性能已经得到很大的改善,但是由于网络之间不统一训练,造成很大的麻烦,所以接下来的Fast R-CNN就是为了解决这样的问题。
改进的地方:
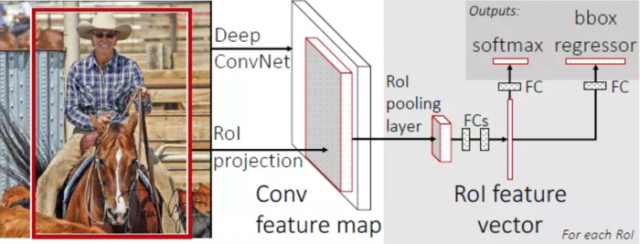
步骤
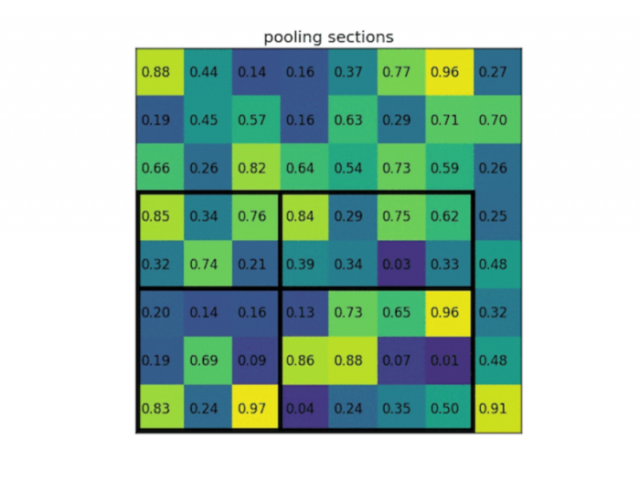
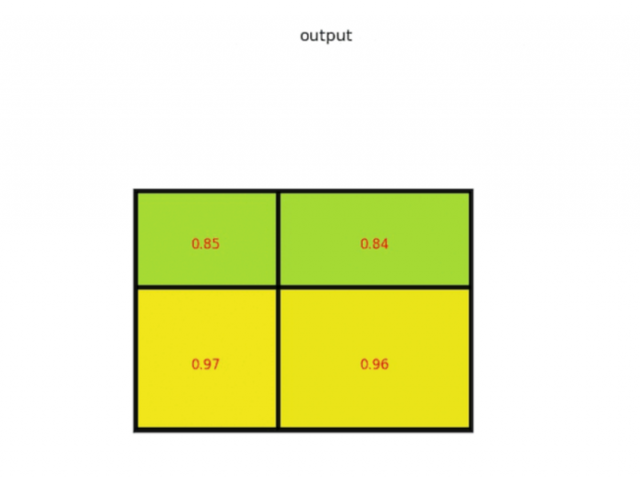
首先RoI pooling只是一个简单版本的SPP层,目的是为了减少计算时间并且得出固定长度的向量。
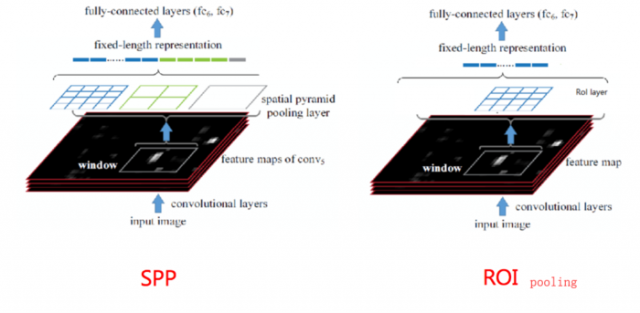
例如:VGG16 的第一个 FC 层的输入是 7 x 7 x 512,其中 512 表示 feature map 的层数。在经过 pooling 操作后,其特征输出维度满足 H x W。
假设输出的结果与FC层要求大小不一致,对原本 max pooling 的单位网格进行调整,使得 pooling 的每个网格大小动态调整为 h/H,w/W,
最终得到的特征维度都是 HxWxD。
它要求 Pooling 后的特征为 7 x 7 x512(即要求输入到 FC 层的特征维度是7 x 7),如果碰巧 ROI 区域只有 6 x 6 大小怎么办?每个网格的大小取 6/7=0.85 , 6/7=0.85,以长宽为例,
按照这样的间隔取网格:[0, 0.85, 1.7, 2.55, 3.4, 4.25, 5.1, 5.95],取整后,每个网格对应的起始坐标为:[0, 1, 2, 3, 4, 5, 6]
下面是一整套RoI pooling流程图:
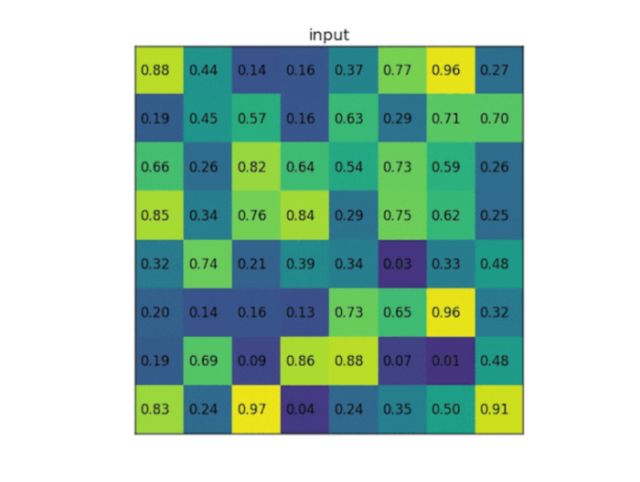
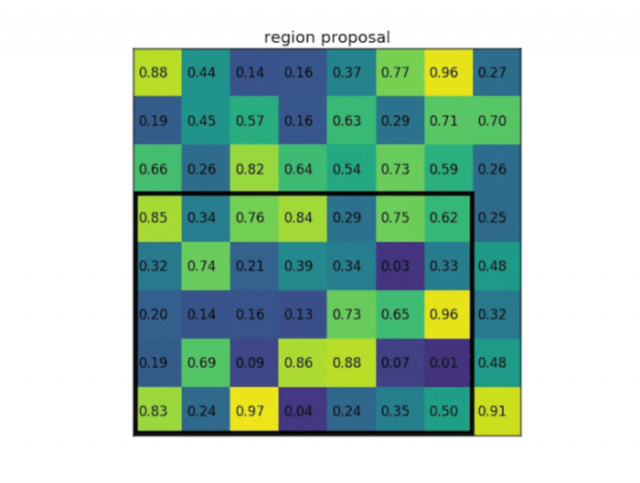
因为每个候选区大小不固定,需要提取一个固定长度的特征向量:
为什么要设计单个尺度呢?这要涉及到single scale与multi scale两者的优缺点
后者比前者更加准确些,不过没有突出很多。但是第一种时间要省很多,所以实际采用的是第一个策略,因此Fast R-CNN要比SPPNet快很多也是因为这里的原因。
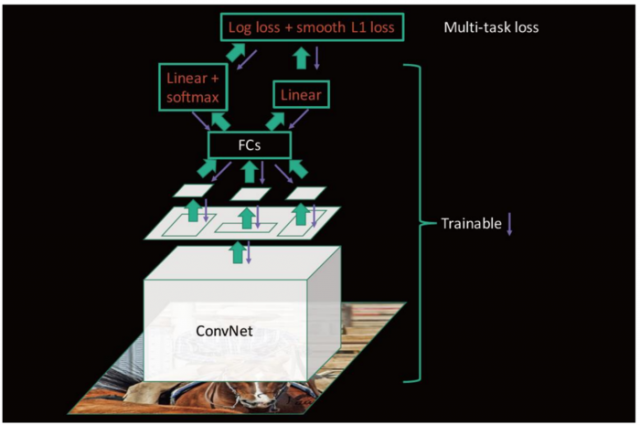
从输入端到输出端直接用一个神经网络相连,整体优化目标函数。
特征提取CNN的训练和SVM分类器的训练在时间上是先后顺序,两者的训练方式独立,因此SVMs的训练Loss无法更新SPP-Layer之前的卷积层参数,去掉了SVM分类这一过程,所有特征都存储在内存中,不占用硬盘空间,形成了End-to-End模型(生成Region proposal除外,end-to-end在Faster-RCNN中得以完善)
两个loss,分别是:
之所以要N+1类,是因为region proposal 会被标记为0,什么都没有,会什么类别都不是,因此最后一层神经元要 N+1 个。
这里训练的就是边框对应的4个坐标,左上角一对坐标,右下角一对坐标
| 参数 | R-CNN | SPPNet | Fast R-CNN |
|---|---|---|---|
| 训练时间(h) | 84 | 25 | 9.5 |
| 测试时间/图片 | 47.0s | 2.3s | 0.32s |
| mAP | 66.0 | 63.1 | 66.9 |
其中有一项指标为mAP,这是一个对算法评估准确率的指标,mAP衡量的是学出的模型在所有类别上的好坏。
缺点:
本文链接:http://task.lmcjl.com/news/6034.html


