exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在;当它说某个值不存在时,那这个值肯定不存在,这个误判概率大约在 1% 左右。
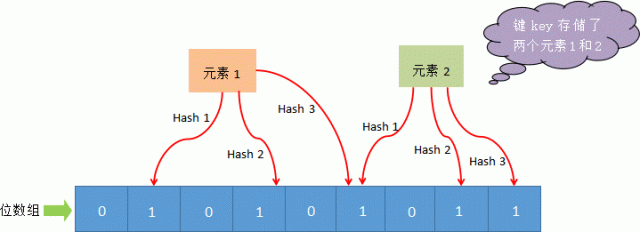
图1:布隆过滤器原理
docker pull redislabs/rebloom:latest docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest docker exec -it redis-redisbloom bash redis-cli #测试是否安装成功 127.0.0.1:6379> bf.add www.lmcjl.com hello
下载地址: https://github.com/RedisBloom/RedisBloom 解压文件: unzip RedisBloom-master.zip 进入目录: cd RedisBloom-master 执行编译命令,生成redisbloom.so 文件: make 拷贝至指定目录: cp redisbloom.so /usr/local/redis/bin/redisbloom.so 在redis配置文件里加入以下配置: loadmodule /usr/local/redis/bin/redisbloom.so 配置完成后重启redis服务: sudo /etc/init.d/redis-server restart #测试是否安装成功 127.0.0.1:6379> bf.add www.lmcjl.com hello
| 命令 | 说明 |
|---|---|
| bf.add | 只能添加元素到布隆过滤器。 |
| bf.exists | 判断某个元素是否在于布隆过滤器中。 |
| bf.madd | 同时添加多个元素到布隆过滤器。 |
| bf.mexists | 同时判断多个元素是否存在于布隆过滤器中。 |
| bf.reserve | 以自定义的方式设置布隆过滤器参数值,共有 3 个参数分别是 key、error_rate(错误率)、initial_size(初始大小)。 |
127.0.0.1:6379> bf.add spider:url www.lmcjl.com (integer) 1 127.0.0.1:6379> bf.exists spider:url www.lmcjl.com (integer) 1 127.0.0.1:6379> bf.madd spider:url www.taobao.com www.123qq.com 1) (integer) 1 2) (integer) 1 127.0.0.1:6379> bf.mexists spider:url www.jd.com www.taobao.com 1) (integer) 0 2) (integer) 1
import redis
size=10000
r = redis.Redis()
count = 0
for i in range(size):
#添加元素,key为userid,值为user0...user9999
r.execute_command("bf.add", "userid", "user%d" % i)
#判断元素是否存在,此处切记 i+1
res = r.execute_command("bf.exists", "userid", "user%d" % (i + 1))
if res == 1:
print(i)
count += 1
#求误判率,round()中的5表示保留的小数点位数
print("size: {} ,error rate:{}%".format(size, round(count / size * 100, 5)))
执行三次测试,size 从小到大。输出结果如下:
size: 1000 , error rate: 1.0% size: 10000 , error rate: 1.25% size: 100000 , error rate: 1.305%通过上述结果可以看出布隆过滤器的错误率为 1% 多点,当 size 越来越大时,布隆过滤器的错误率就会升高,那么有没有办法降低错误率呢?这就用到了布隆过滤器提供的
bf.reserve方法。如果不使用该方法设置参数,那么布隆过滤器将按照默认参数进行设置,如下所示:
key #指定存储元素的键,若已经存在,则bf.reserve会报错 error_rate=0.01 #表示错误率 initial_size=100 #表示预计放入布隆过滤器中的元素数量当放入过滤器中的元素数量超过了 initial_size 值时,错误率 error_rate 就会升高。因此就需要设置一个较大 initial_size 值,避免因数量超出导致的错误率上升。
client.execute_command("bf.reserve", "keyname", 0.001, 50000)
布隆过滤器相比于平时常用的的列表、散列、集合等数据结构,其占用空间更少、效率更高,但缺点就是返回的结果具有概率性,并不是很准确。在理论情况下,添加的元素越多,误报的可能性就越大。再者,存放于布隆过滤器中的元素不容易被删除,因为可能出现会误删其他元素情况。
本文链接:http://task.lmcjl.com/news/18050.html


