cycleGAN源文:https://arxiv.org/abs/1703.10593
cycleGAN笔者实践代码:https://github.com/leehomyc/cyclegan-1
-----------------------------------------------------------------------------------------------------------------------------------------
到了cycleGAN,就不再像之前几个改进,仅仅停留在改动 Loss,还开始改动结构了…
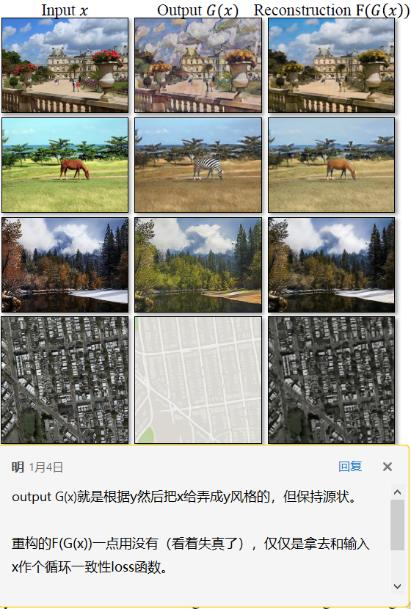
图像到图像的翻译是一类视觉和图形问题,其目标是学习输入图像和输出图像之间的映射使用一组对齐的图像对。然而,对于许多任务,成对的训练数据是不可用的。本文提出了一种学习方法,在没有成对实例的情况下,将图像从源域X转换为目标域Y。我们的目标是学习一个映射G: X->Y,使来自G(X)的图像的分布与使用对抗损失的分布难以区分。因为这个映射是高度欠约束的,我们将它与一个逆映射F: Y->X 和引入一个循环一致性损失 执行F(G(X))约等于X (Y与G(F(Y))亦然).在不存在成对训练数据的情况下,对风格转换、物体变形(有限)、季节转换、照片增强等任务进行定性分析。通过与已有方法的定量比较,证明了该方法的优越性。
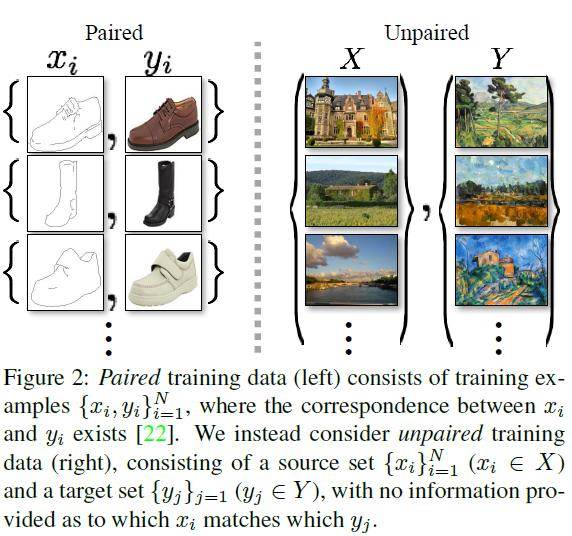
图像到图像的翻译[22],是将一个图像从一个给定场景的一种表示x,转换成另一个y。例如,灰度到颜色,图像到语义标签,边缘地图到照片。多年来在计算机视觉、图像处理、计算摄影和图形方面的研究已经产生了强大的翻译系统,在监督设置,其中的示例图像对{xi,yi}Ni=1是可用的(图2,左),例如,[11,19,22,23,28,33,45,56,58,62]。然而,获得成对的训练数据可能是困难和昂贵的。例如,只有几个数据集用于语义分割(例如[4]),而且它们相对较小。为艺术风格化之类的图形任务获取输入-输出对可能更加困难,因为所需的输出非常复杂,通常需要艺术创作。对于许多任务,比如对象变形(例如zebra<->horse,图1中上部),所需的输出甚至没有定义。
因此,我们寻求一种无需成对输入-输出示例就能学会在域之间进行转换的算法(图2,右侧)。我们假设在这些域之间存在某种潜在的关系——例如,它们是同一底层场景的两种不同的呈现——并试图了解这种关系。虽然我们缺乏成对样本的监督,但我们可以利用集合层面的监督: 给定X域中的一组图像和Y域中的另一组图像。我们可以训练一个映射G: X->Y,这样输出 y ^ = G (x) (x∈X),y ^ 与y在对抗网络训练下不能彼此分开。从理论上讲,这一目标可以产生一个输出分布y^ 相匹配的经验分布 pdata (y)(一般来说,这需要随机G) [16]。最优的G将定义域X转化为定义域Y的同分布。然而,这样的转换并不能保证一个单独的输入x和输出y以有意义的方式配对——有无穷多个映射G会在y^ 上产生相同的分布。此外,在实践中,我们发现很难单独优化对抗目标: 标准程序常常导致众所周知的模式崩溃问题,即所有输入图像映射到相同的输出图像,而优化未能取得进展。
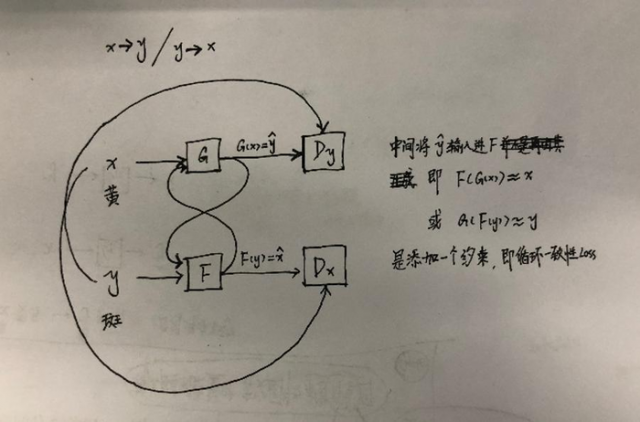
这些问题要求为我们的目标增加更多的结构。因此,我们利用了翻译应该是“循环一致的”这一特性,也就是说,如果我们把一个句子从英语翻译成法语,然后再把它从法语翻译成英语,我们应该回到原来的句子[3]。数学上,如果我们有一个翻译器G: X->Y和另一个翻译器F: Y->X。那么G和F应该是彼此的逆,两个映射都应该是双射。我们应用这种结构,假设通过同时训练映射 G 和 F, 和添加一个循环一致性损失[64],促使 F(G(x))≈x 和 G(F(y))≈y,整合这个过程中的G的损失与判别器X和Y损失。我们完整客观解决未配对的图像翻译问题。
我们的方法适用于广泛的应用,包括收集风格的转移,对象变形,季节转移和照片增强。我们还比较了以前的方法,这些方法要么依赖于手工定义的样式和内容的因数分解,要么依赖于共享的嵌入函数,并表明我们的方法比这些基线更好。我们提供了PyTorch和Torch实现。更多结果请访问我们的网站。
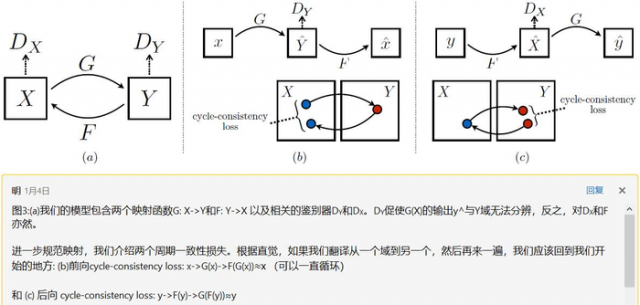
我们的目标是在给定训练样本{xi}Ni=1(其中xi∈X)和{yj}Mj=1(其中yj∈Y)的情况下,学习X和Y两个域之间的映射函数。我们表示数据分布的x~pdata(x) 和 y~pdata(y).如图3 (a)所示,我们的模型包含两个映射G: X->Y和F: Y->X。此外,我们还介绍了两个鉴别器DX和DY,其中DX的目的是区分图像{x}和图像{F(y)};同样的,DY的目的是区分{y}和{G(x)}。我们的目标包含两类: 用于将生成的图像的分布与目标域中的数据分布匹配的对抗性损失[16];和循环一致性损失,以防止学习的映射G和F相互矛盾。
我们对这两个映射函数应用了对抗损失[16]。对于映射函数G: X->Y及其判别器DY,我们将目标表示为:
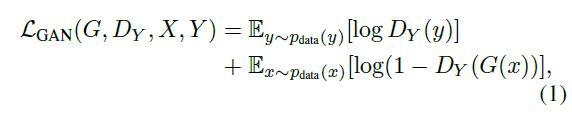
其中G试图生成与Y域图像相似的图像G(x),而DY旨在区分已翻译的样本G(x)和真实样本y,minG maxDY LGAN(G,DY,X,Y)。我们为映射函数F: Y->X 引入了一个类似的竞争损失。X和它的鉴别器minF maxDx LGAN(F,DX,Y,X)。
从理论上讲,对抗性训练可以学习生成结果分别为目标域Y和X同分布的映射G和F(严格地说,这要求G和F是随机函数)[15]。然而,在足够大的容量下,网络可以将同一组输入图像映射到目标域中任意随机排列的图像,其中任何已学习的映射都可以诱导出与目标分布匹配的输出分布。因此,仅仅是对抗性损失并不能保证所学习的函数能够将单个的输入xi映射到所需的输出yi。为了进一步减少可能的映射函数的空间,我们认为所学习的映射函数应该是循环一致的: 如图3 (b)所示,对于x域中的每个图像x,图像翻译周期应该能够将x带回到原始图像,即x->G (x)->F(G(x))≈x ,我们称之为 正向循环。类似地,如图3 ©所示,对于y域中的每个图像y, G和F也应该满足反向循环一致性:y->F(y)->G(F(y))≈y 。我们使用循环一致性损失以鼓励这种行为:
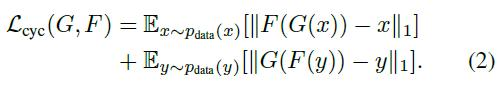
在初步实验中,我们也尝试用F(G(x))和x之间、G(F(y))和y之间的对抗性损失来代替L1范数,但没有观察到性能的改善。
循环一致性损失引起的行为如图4所示: 重构图像F(G(x))最终与输入图像x紧密匹配。
我们的总目标函数为:
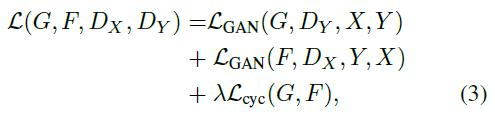
λ是控制对抗loss和循环一致性loss的比重。
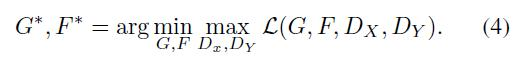
注意到训练我们的模型可以看作是两个“自编码器” [20]: 我们学习一个自编码器 F○G : X->X 会同另一个G○F : Y->Y。然而,这些自编码器都有特殊的内部结构: 它们通过中间表示将图像映射到自身,中间表示是将图像转换到另一个域。这样的设置也可以看作是“对抗性自动编码器”[34]的一个特例,它使用对抗性损失来训练自编码器的瓶颈层来匹配任意的目标分布。在我们的例子中,目标分布X->X是定义域Y的自编码器。
在第5.1.4节中,我们将我们的方法与全部目标进行了比较,包括仅使用对抗性损失LGAN和仅使用周期一致性损失Lcyc,并通过实证表明,这两个目标在获得高质量的结果中都发挥了关键作用。我们也评估了我们的方法只用一个循环损失在一个方向,并表明,一个单一的循环是不够正则化的训练,这一不足约束的问题。
我们的生成网络采用了Johnson等人的体系结构,他们在神经风格传输和超分辨率方面取得了令人印象深刻的成果。该网络包含两个stride-2卷积,几个残差块[18],以及两个部分stride卷积和stride 1/2。我们使用6blocks128×128图片 , 9blocks 256×256和更高分辨率训练图片。与Johnson等人的[23]类似,我们使用instance normalization(实例规范化) [53]。对于判别器网络 我们使用70×70PatchGANs [22, 30, 29], 旨在分类 70×70 重叠的图像补丁是否真实或 fake。这种补丁级判别器架构的参数比全图像鉴别器的少,并且可以以全卷积的方式处理任意大小的图像。(见后)
我们从最近的工作中应用了两种技术来稳定我们的模型训练过程。首先,对于LGAN(公式1),我们用最小二乘损失[35]代替负对数似然目标。这种损失在训练中更稳定,产生更高质量的结果。特别是对于LGAN(G;D;X;Y )的GAN损失函数,
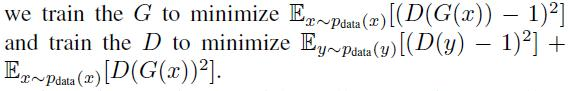
其次,为了减少模型振荡[15],我们遵循Shrivastava等人的策略[46],并使用生成图像的历史来更新判别器,而不是使用最新的生成器生成的图像。我们保存了一个图像缓冲区,它存储了之前创建的50个图像。
对于所有实验, 公式3. 中 我们设置 λ= 10。我们使用批量大小为1的Adam solver[26]。所有网络都是从零开始训练,学习率为0.0002。我们对前100个周期保持相同的学习率,并在接下来的100个周期内线性衰减到0。有关数据集、体系结构和训练程序的详细信息,请参阅附录(第7节)。
我们首先将我们的方法与最近在成对数据集上的非成对图像翻译方法进行比较,其中ground truth输入-输出对可用于评估。然后,我们研究了对抗性损失和循环一致性损失的重要性,并将我们的完整方法与几种变体进行了比较。最后,我们演示了我们的算法在不存在配对数据的广泛应用中的通用性。为了简单起见,我们将我们的方法称为CycleGAN。PyTorch和Torch代码、模型和完整的结果可以在我们的网站上找到。
AMT感知研究
在map<->航拍任务中,我们在Amazon Mechanical Turk (AMT)上运行“真实与虚假”感知研究,以评估输出的真实性。我们遵循的知觉研究协议与Isola等人的[22]相同,只是我们每个测试算法只收集25个参与者的数据。研究人员向参与者展示了一系列图像,其中一张是真实的照片或地图,另一张是假的(由我们的算法或基线生成),并要求他们点击他们认为是真实的图像。每一阶段的前10次试验都是练习,并就参与者的回答是正确还是错误给出反馈。剩下的40个试验用于评估每种算法骗到参与者的比率。每个会话(session)只测试一个算法,参与者只允许完成一个会话(session)。我们在这里报告的数字与[22]中的数字没有直接的可比性,因为我们的ground truth图像处理略有不同,我们测试的参与者池可能与[22]中的参与者池分布不同(因为在不同的日期和时间运行实验)。因此,我们的数字应该只用于与基线(在相同的条件下运行)比较我们当前的方法,而不是与[22]比较。
FCN score
虽然感知学习可能是评估图形真实感的黄金标准,我们也寻求一种不需要人类实验的自动定量测量。为此,我们采用了来自[22]的“FCN分数”,并使用它来评估Cityscapes标签->照片的任务。FCN度量根据现成的语义分割算法(全卷积网络,FCN,源自[33])评估生成的照片的可解释性。FCN预测生成的照片的标签映射。然后,可以使用下面描述的标准语义分割指标将此标签映射与输入的ground truth标签进行比较。我们的直觉是,如果我们从“道路上的汽车”的标签地图生成一张照片,那么如果FCN应用到生成的照片检测到“道路上的汽车”,那么我们就成功了。
语义细分指标
为了评估照片->标签的性能。我们使用Cityscapes基准[4]的标准度量,包括每像素精度、每类精度和平均类相交-过并(类IOU)[4]。
一顿叽里呱啦的数据分析…
并与有监督的图像翻译pix2pix(他们都有成对的训练数据)作对比:
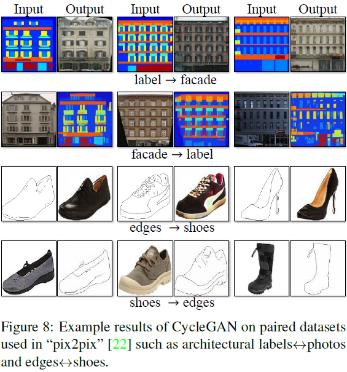
风格转换(图10和图11)
我们通过从Flickr和WikiArt下载的风景照片来训练模型。与最近关于“神经风格转移”[13]的工作不同,我们的方法学会了模仿整个艺术作品集合的风格,而不是转移单个选定的艺术作品的风格。因此,我们可以学习生成梵高风格的照片,而不仅仅是《星夜》的风格。每个艺术家/风格的数据集大小分别为526、1073、400和563 (Cezanne, Monet, Van Gogh, Ukiyo-e)。

对象变形(图13)
模型被训练来将一个对象类从ImageNet[5]转换成另一个对象类(每个类包含大约1000个训练图像)。Turmukhambetov等人[50]提出了一种子空间模型,将一个对象转换成另一个具有相同类别的对象,而我们的方法侧重于两个视觉上相似的类别之间的对象变形。

季节转移(图13)
模型使用从Flickr下载的854张优胜美地冬季照片和1273张夏季照片进行训练。

绘画生成照片(图12)
绘画<->照片,我们发现它有助于引入一个额外的损失,以鼓励映射,以保持颜色组成之间的输入和输出。特别地,我们采用了Taigman等人的[49]技术,当提供目标域的真实样本作为生成器的输入时,将生成器调整为接近于一个身份映射:即
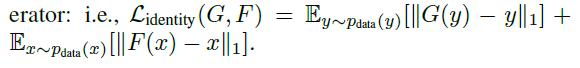
在没有Lidentity的情况下,G和F可以在不需要的时候自由改变输入图像的颜色。例如,当学习Monet的绘画和Flickr照片之间的映射时,生成器经常将白天的绘画映射到日落时拍摄的照片,因为这样的映射在对抗损失和循环一致性损失下可能同样有效。这种身份映射丢失的影响如图9所示。

在图12中,我们展示了将莫奈的画作转换成照片的附加结果。这个图和图9显示了训练集中包含的绘画的结果,而对于本文中所有其他的实验,我们只评估和显示了测试集的结果。因为训练集不包含成对的数据,所以为训练集绘制提出一个合理的转换是一项重要的任务。事实上,由于莫奈不再能够创作出新的画作,泛化成看不见的“测试集”,画作就不是一个紧迫的问题。

照片增强(图14)
结果表明,该方法可以生成景深较浅的照片。我们在从Flickr下载的花卉照片上训练模型。源域由智能手机拍摄的花卉照片组成,由于孔径较小,这些照片通常具有较深的DoF。目标包含用较大光圈的单反相机拍摄的照片。我们的模型成功地从智能手机拍摄的照片中生成了景深较浅的照片。

与Gatys等人的比较
在图15中,我们将我们的结果与神经类型转换[13]在照片风格化上的结果进行了比较。对于每一行,我们首先使用两个具有代表性的艺术品作为[13]的样式图像。另一方面,我们的方法可以生成整个集合风格的照片。为了与整个集合的神经风格传递进行比较,我们计算了目标域上的格拉姆矩阵,并使用这个矩阵与Gatys等人的[13]一起传递“平均风格”。
 图16展示了其他翻译任务的类似比较。我们观察到,Gatys等人的[13]需要找到与期望输出密切匹配的目标样式图像,但仍然经常不能产生逼真的结果,而我们的方法成功地生成自然外观的结果,类似于目标域。
图16展示了其他翻译任务的类似比较。我们观察到,Gatys等人的[13]需要找到与期望输出密切匹配的目标样式图像,但仍然经常不能产生逼真的结果,而我们的方法成功地生成自然外观的结果,类似于目标域。

虽然我们的方法在很多情况下都能得到令人信服的结果,但结果远不是一致肯定的。图17显示了几个典型的失败案例。在涉及颜色和纹理变化的翻译任务中,就像上面报道的许多任务一样,这种方法通常会成功。我们还探索了需要几何变化的任务,但收效甚微。例如,关于狗变形猫的任务,学习后的翻译退化为对输入进行最小的更改(图17)。此故障可能是由我们的生成器架构导致的,我们的生成器架构是为外观更改的良好性能而定制的。处理更多样和极端的转换,特别是几何变化,是未来工作的一个重要问题。
一些失败案例是由训练数据集的分布特性引起的。例如,我们的方法在马->斑马示例(图17,右)中被混淆了,因为我们的模型是在ImageNet的野马和斑马的同义词集上训练的,它不包含人骑着马或斑马的图像。
我们还观察到配对训练数据和非配对训练方法所获得的结果之间的差距。在某些情况下,这种差距可能很难(甚至不可能)消除: 例如,我们的方法有时会在照片->标签任务的输出中破坏树和建筑物的标签。为了解决这种模糊性,可能需要某种形式的弱语义监督。集成弱或半监督的数据可能会产生更强大的翻译,但其注释成本仅为全监督系统的一小部分。
尽管如此,在许多情况下,完全不配对的数据是大量可用的,应该加以利用。这篇论文在这种“无监督”的环境下拓展了可能性的边界。

-----------------------------------------------------------------------------------------------------------------------------------------
在实践代码Github: https://github.com/leehomyc/cyclegan-1
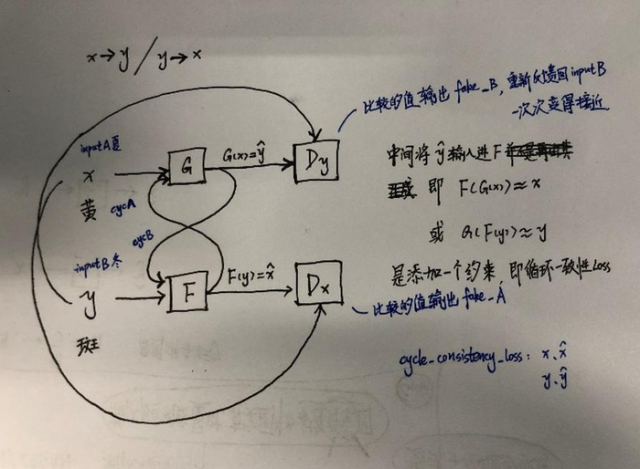
代码中夏天<->冬天需要训练200次,我训练了10次以后的test效果图:

从左到右依次为:inputA、inputB、cycA、cycB、fakeB、fakeA(cycA、cycB没啥用)
-----------------------------------------------------------------------------------------------------------------------------------------
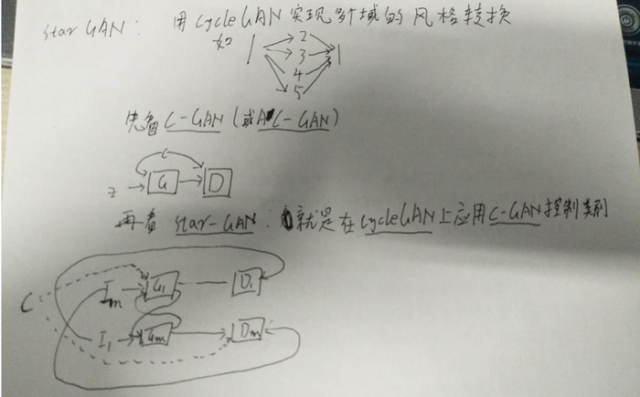
starGAN = cycGAN+ACGAN
本文链接:http://task.lmcjl.com/news/5722.html


