深度学习模型在计算机视觉与语音识别方面取得了卓越的成就,在 NLP 领域也是可以的。将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似 n-gram 的关键信息),从而能够更好地捕捉局部相关性。
文本分类是自然语言处理领域最活跃的研究方向之一,目前文本分类在工业界的应用场景非常普遍,从新闻的分类、商品评论信息的情感分类到微博信息打标签辅助推荐系统,了解文本分类技术是NLP初学者比较好的切入点,较简单且应用场景高频。
1、Yoon Kim在2014年 “Convolutional Neural Networks for Sentence Classification” 论文中提出TextCNN(利用卷积神经网络对文本进行分类的算法)(该论文翻译)。
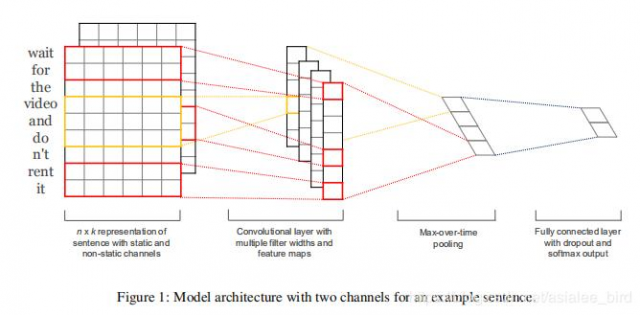
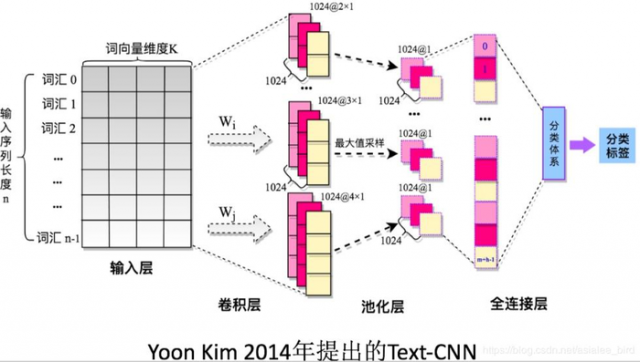
上图很好地诠释了模型的框架。假设我们有一些句子需要对其进行分类。句子中每个词是由n维词向量组成的,也就是说输入矩阵大小为m*n,其中m为句子长度。CNN需要对输入样本进行卷积操作,对于文本数据,filter不再横向滑动,仅仅是向下移动,有点类似于N-gram在提取词与词间的局部相关性。图中共有三种步长策略,分别是2,3,4,每个步长都有两个filter(实际训练时filter数量会很多)。在不同词窗上应用不同filter,最终得到6个卷积后的向量。然后对每一个向量进行最大化池化操作并拼接各个池化值,最终得到这个句子的特征表示,将这个句子向量丢给分类器进行分类,至此完成整个流程。
(1)嵌入层(Embedding Layer)
通过一个隐藏层, 将 one-hot 编码的词投影到一个低维空间中,本质上是特征提取器,在指定维度中编码语义特征。 这样, 语义相近的词, 它们的欧氏距离或余弦距离也比较近。(作者使用的单词向量是预训练的,方法为fasttext得到的单词向量,当然也可以使用word2vec和GloVe方法训练得到的单词向量)。
(2)卷积层(Convolution Laye)
在处理图像数据时,CNN使用的卷积核的宽度和高度的一样的,但是在text-CNN中,卷积核的宽度是与词向量的维度一致!这是因为我们输入的每一行向量代表一个词,在抽取特征的过程中,词做为文本的最小粒度。而高度和CNN一样,可以自行设置(通常取值2,3,4,5),高度就类似于n-gram了。由于我们的输入是一个句子,句子中相邻的词之间关联性很高,因此,当我们用卷积核进行卷积时,不仅考虑了词义而且考虑了词序及其上下文(类似于skip-gram和CBOW模型的思想)。
(3)池化层(Pooling Layer)
因为在卷积层过程中我们使用了不同高度的卷积核,使得我们通过卷积层后得到的向量维度会不一致,所以在池化层中,我们使用1-Max-pooling对每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征,而且认为这个最大值表示的是最重要的特征。当我们对所有特征向量进行1-Max-Pooling之后,还需要将每个值给拼接起来。得到池化层最终的特征向量。在池化层到全连接层之前可以加上dropout防止过拟合。
(4)全连接层(Fully connected layer)
全连接层跟其他模型一样,假设有两层全连接层,第一层可以加上’relu’作为**函数,第二层则使用softmax**函数得到属于每个类的概率。
(5)TextCNN的小变种
在词向量构造方面可以有以下不同的方式: CNN-rand: 随机初始化每个单词的词向量通过后续的训练去调整。 CNN-static: 使用预先训练好的词向量,如word2vec训练出来的词向量,在训练过程中不再调整该词向量。 CNN-non-static: 使用预先训练好的词向量,并在训练过程进一步进行调整。 CNN-multichannel: 将static与non-static作为两通道的词向量。
(6)参数与超参数
sequence_length (Q: 对于CNN, 输入与输出都是固定的,可每个句子长短不一, 怎么处理? A: 需要做定长处理, 比如定为n, 超过的截断, 不足的补0. 注意补充的0对后面的结果没有影响,因为后面的max-pooling只会输出最大值,补零的项会被过滤掉)
num_classes (多分类, 分为几类)
vocabulary_size (语料库的词典大小, 记为|D|)
embedding_size (将词向量的维度, 由原始的 |D| 降维到 embedding_size)
filter_size_arr (多个不同size的filter)
2、2015年“A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification”论文详细地阐述了关于TextCNN模型的调参心得。
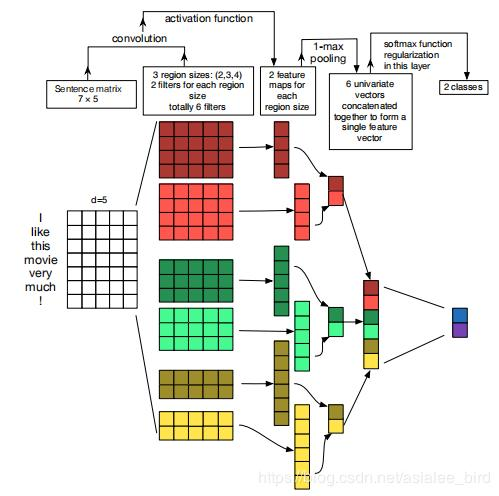
(1)TextCNN详细过程:
(2)论文调参结论:
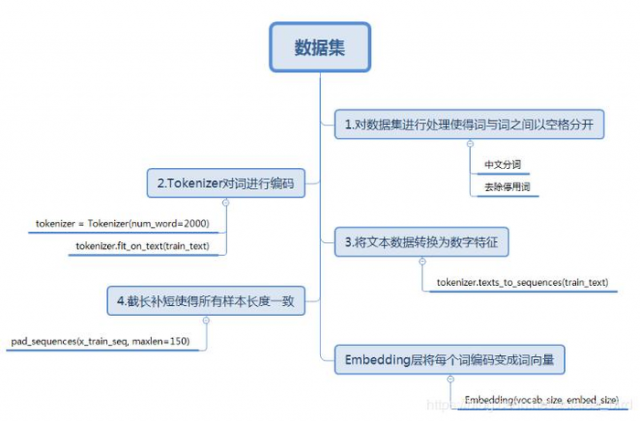
1、读取数据集
2、使用Tokenizer将文字转换成数字特征
使用Keras的Tokenizer模块实现转换。当我们创建了一个Tokenizer对象后,使用该对象的fit_on_texts()函数,可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小。使用word_index属性可以看到每次词对应的编码。
3、将数据集中的每条文本转换为数字列表,使用每个词的编号进行编号
使用该对象的texts_to_sequences()函数,将每条文本转变成一个向量。
4、使用pad_sequences()让每句数字影评长度相同
由于每句话的长度不唯一,需要将每句话的长度设置一个固定值。将超过固定值的部分截掉,不足的在最前面用0填充。
5、使用Embedding层将每个词编码转换为词向量
Embedding层基于上文所得的词编码,对每个词进行one-hot编码,每个词都会是一个vocabulary_size维的向量;然后通过神经网络的训练迭代更新得到一个合适的权重矩阵(具体实现过程可以参考skip-gram模型),行大小为vocabulary_size,列大小为词向量的维度,将本来以one-hot编码的词向量映射到低维空间,得到低维词向量。需要声明一点的是Embedding层是作为模型的第一层,在训练模型的同时,得到该语料库的词向量。当然,也可以使用已经预训练好的词向量表示现有语料库中的词。
文本预处理目的:将每个样本转换为一个数字矩阵,矩阵的每一行表示一个词向量。
Keras文本预处理代码实现:
from sklearn.model_selection import train_test_split
import pandas as pd
import jieba
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
if __name__=='__main__':
dataset = pd.read_csv('sentiment_analysis/data_train.csv', sep='\t',names=['ID', 'type', 'review', 'label']).astype(str)
cw = lambda x: list(jieba.cut(x))
dataset['words'] = dataset['review'].apply(cw)
tokenizer=Tokenizer() #创建一个Tokenizer对象
#fit_on_texts函数可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小
tokenizer.fit_on_texts(dataset['words'])
vocab=tokenizer.word_index #得到每个词的编号
x_train, x_test, y_train, y_test = train_test_split(dataset['words'], dataset['label'], test_size=0.1)
# 将每个样本中的每个词转换为数字列表,使用每个词的编号进行编号
x_train_word_ids=tokenizer.texts_to_sequences(x_train)
x_test_word_ids = tokenizer.texts_to_sequences(x_test)
#序列模式
# 每条样本长度不唯一,将每条样本的长度设置一个固定值
x_train_padded_seqs=pad_sequences(x_train_word_ids,maxlen=50) #将超过固定值的部分截掉,不足的在最前面用0填充
x_test_padded_seqs=pad_sequences(x_test_word_ids, maxlen=50)
1、基础版CNN(模仿LeNet-5)
LeNet-5是卷积神经网络的作者Yann LeCun用于MNIST识别任务提出的模型。模型很简单,就是卷积池化层的堆叠,最后加上几层全连接层。将其运用在文本分类任务中。
#构建CNN分类模型(LeNet-5)
#模型结构:嵌入-卷积池化*2-dropout-BN-全连接-dropout-全连接
def CNN_model(x_train_padded_seqs, y_train, x_test_padded_seqs, y_test):
model = Sequential()
model.add(Embedding(len(vocab) + 1, 300, input_length=50)) #使用Embeeding层将每个词编码转换为词向量
model.add(Conv1D(256, 5, padding='same'))
model.add(MaxPooling1D(3, 3, padding='same'))
model.add(Conv1D(128, 5, padding='same'))
model.add(MaxPooling1D(3, 3, padding='same'))
model.add(Conv1D(64, 3, padding='same'))
model.add(Flatten())
model.add(Dropout(0.1))
model.add(BatchNormalization()) # (批)规范化层
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
one_hot_labels = keras.utils.to_categorical(y_train, num_classes=3) # 将标签转换为one-hot编码
model.fit(x_train_padded_seqs, one_hot_labels,epochs=5, batch_size=800)
y_predict = model.predict_classes(x_test_padded_seqs) # 预测的是类别,结果就是类别号
y_predict = list(map(str, y_predict))
print('准确率', metrics.accuracy_score(y_test, y_predict))
print('平均f1-score:', metrics.f1_score(y_test, y_predict, average='weighted'))2、简单版TextCNN
#构建TextCNN模型
#模型结构:词嵌入-卷积池化*3-拼接-全连接-dropout-全连接
def TextCNN_model_1(x_train_padded_seqs,y_train,x_test_padded_seqs,y_test):
main_input = Input(shape=(50,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=48)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=47)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=46)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(3, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
one_hot_labels = keras.utils.to_categorical(y_train, num_classes=3) # 将标签转换为one-hot编码
model.fit(x_train_padded_seqs, one_hot_labels, batch_size=800, epochs=10)
#y_test_onehot = keras.utils.to_categorical(y_test, num_classes=3) # 将标签转换为one-hot编码
result = model.predict(x_test_padded_seqs) # 预测样本属于每个类别的概率
result_labels = np.argmax(result, axis=1) # 获得最大概率对应的标签
y_predict = list(map(str, result_labels))
print('准确率', metrics.accuracy_score(y_test, y_predict))
print('平均f1-score:', metrics.f1_score(y_test, y_predict, average='weighted'))3、使用Word2Vec词向量的TextCNN
w2v_model=Word2Vec.load('sentiment_analysis/w2v_model.pkl')
# 预训练的词向量中没有出现的词用0向量表示
embedding_matrix = np.zeros((len(vocab) + 1, 300))
for word, i in vocab.items():
try:
embedding_vector = w2v_model[str(word)]
embedding_matrix[i] = embedding_vector
except KeyError:
continue
#构建TextCNN模型
def TextCNN_model_2(x_train_padded_seqs,y_train,x_test_padded_seqs,y_test,embedding_matrix):
# 模型结构:词嵌入-卷积池化*3-拼接-全连接-dropout-全连接
main_input = Input(shape=(50,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=50, weights=[embedding_matrix], trainable=False)
#embedder = Embedding(len(vocab) + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=38)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=37)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=36)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(3, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
one_hot_labels = keras.utils.to_categorical(y_train, num_classes=3) # 将标签转换为one-hot编码
model.fit(x_train_padded_seqs, one_hot_labels, batch_size=800, epochs=20)
#y_test_onehot = keras.utils.to_categorical(y_test, num_classes=3) # 将标签转换为one-hot编码
result = model.predict(x_test_padded_seqs) # 预测样本属于每个类别的概率
result_labels = np.argmax(result, axis=1) # 获得最大概率对应的标签
y_predict = list(map(str, result_labels))
print('准确率', metrics.accuracy_score(y_test, y_predict))
print('平均f1-score:', metrics.f1_score(y_test, y_predict, average='weighted'))1、环境配置
(1)安装graphviz模块
首先,命令行pip install graphviz;其次,安装graphviz软件,官网下载:graphviz-2.38.msi ;最后,将安装目录中的graphviz-2.38\release\bin添加进Path环境变量。
(2)安装pydot模块
命令行pip install pydot
(3)在运行程序中加入下面两行代码
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'2、使用plot_model()画出模型图
from keras.utils import plot_model
#生成一个模型图,第一个参数为模型,第二个参数为要生成图片的路径及文件名,还可以指定两个参数:
#show_shapes:指定是否显示输出数据的形状,默认为False
#show_layer_names:指定是否显示层名称,默认为True
plot_model(model,to_file='sentiment_analysis/model.png',show_shapes=True,show_layer_names=False)模型图如下:
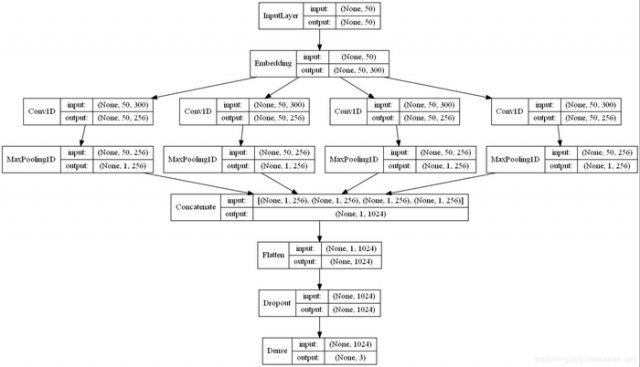
from keras.models import load_model
#模型的保存
model.save('model.h5')
#模型的加载
model=load_model('model.h5')
参考学习资料:
(1)Keras之文本分类实现
(3)NLP论文
(5)用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
(8)基于 word2vec 和 CNN 的文本分类 :综述 & 实践
本文链接:http://task.lmcjl.com/news/5773.html


