import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据
path = 'D:\BaiduNetdiskDownload\data_sets\ex1data1.txt'
# pd.read_csv 将 TXT 文件读入并转化为数据框形式
# names 添加列名
# header 用指定的行来作为标题(表头),若原来无标题则设为 none
# 用到 Pandas 里面的 head( ) 函数读取数据(只能读取前五行)
data = pd.read_csv(path,header=None,names=['Population','Profit'])
data.head()
# 在训练集中插入一列1(其实是x0=1),方便我们可以使用向量化的解决方案来计算代价和梯度。
data.insert(0, 'Ones', 1)
# set X(training set), y(target variable)
# 设置训练集X,和目标变量y的值
cols = data.shape[1] # 获取列数
X = data.iloc[:,0:cols-1] # 输入向量X为前cols-1列
y = data.iloc[:,cols-1:cols] # 目标变量y为最后一列
# 代价函数是应该是 numpy 矩阵,所以我们需要转换X和Y,然后才能使用它们。 我们还需要初始化 theta 。
X = np.array(X.values)
y = np.array(y.values)
theta = np.array([0,0])
核心代码:
from sklearn import linear_model
# 需要导入LinearRegression类,并将之实例化,并采用fit()方法已验证这些训练数据。
model = linear_model.LinearRegression()
model.fit(X, y) # fit(X, y)对训练集X, y进行训练
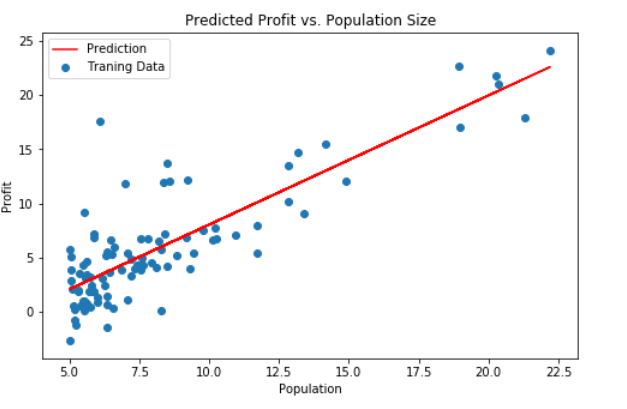
scikit-learn model的预测表现:
x = np.array(X[:, 1])
f = model.predict(X).flatten() # .flatten() 默认按行的方向降维
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
python_sklearn机器学习算法系列之LinearRegression线性回归
本文链接:http://task.lmcjl.com/news/5774.html


