Scalable Object Detection using Deep Neural Networks
作者: Dumitru Erhan, Christian Szegedy, Alexander Toshev, and Dragomir Anguelov
引用: Erhan, Dumitru, et al. "Scalable object detection using deep neural networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014.
引用次数: 181(Google Scholar, by 2016/11/23).
项目地址: https://github.com/google/multibox
1 介绍
这是一篇2014年发表的CVPR会议论文, 几个作者都是Google公司的,文中的检测算法被命名为"DeepMultiBox".首先来看一下本文模型的思路: 本文的目标检测还是采用两步走的策略:
第一步: 在图像上生成候选区域; 以前常用的生成候选区域的方法是穷举法,对图像上所有的位置以及尺度进行穷举,这种计算效率太低,已经遭到废弃,现在陆续出来一些其他的方法,比如论文<论文阅读笔记--Selective Search for Object Recognition>里面提出的Selective Search的方法,利用层次聚类的思想,生成指定数目最可能包含目标的候选区域.同样,本文也是在这一方面做努力,提出了使用CNN来生成候选区域,并且命名为"DeepMultiBox";
第二步: 利用CNN对生成的候选区域进行分类; 生成候选区域后,提取特征,然后利用分类器进行分类从而达到识别的目的,这是一般的思路,没有什么好讲的,本文的重心在第一步.
2 本文模型
2.1 回归模型DeepMultiBox
如何使用CNN来在图像上生成候选区域呢? 本文借鉴了AlexNet网络的结构:
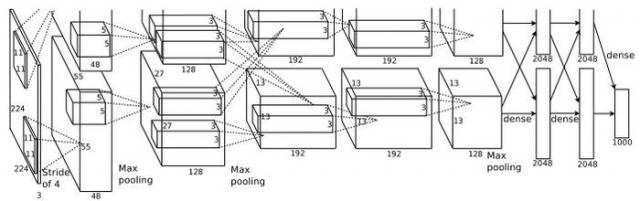
要对这个问题进行建模! 我们这里的目的是想让CNN输出一定数量的bounding boxes(每个box用4个参数表示,分别是此box的左上角的横坐标+纵坐标,右下角的横坐标+纵坐标,对每个坐标值要用图像的宽和高进行归一化),另外还要输出每个box上还要有一个是否包含目标的置信度(值介于0~1之间).这样,如果我们想让CNN输出K=100个bounding boxes,CNN输出层节点的维度要为(K*(4+1)=5*K=500).
2.1.1 DeepMultiBox的训练集构造
训练集是如何构造的? 训练集的输入肯定是每张训练图像上的"maximum center square crop",这个的含义是先计算每张图像的中心点,然后以它为中心从图像上裁剪出来一个最大的正方形,为了满足AlexNet的网络结构,可能每张图像还要resize到220*220大小(这点在原文中的4.2.2中讲述);关键在于输出,这点文中讲的比较隐晦,原文的表述为:"For each image,we generate the same number of square samples such that the total number of samples is about ten million.For each image, the samples are bucketed such that for each of the ratios in the ranges of 0−5%, 5−15%, 15−50%, 50−100%,there is an equal number of samples in which the ratio covered by the bounding boxes is in the given range." 我的理解是,对于训练集中的每个图像,产生固定数量(假设为N)的正方形的区域作为训练集(问题1:为什么要是正方形? 这些区域的大小都是相同的吗?如果相同,如何满足目标多尺度要求?如果不相同,如何选择区域的大小?),这N个区域的选择是有讲究的:它由四份组成,每份中区域向数量相等,而且每份中的区域与图像上GT boxes的重合程度分别是0-5%,5-15%,15-50%,50-100%.每个区域的置信度也没有讲要如何确定,我想应该就是每个区域与GT boxes的重合程度吧!
(问题2: 训练样本是不是这样构造的,还请指教!)
2.1.2 DeepMultiBox的训练
2.2里面讲述了训练集是如何构造的(有可能我理解的不正确,但是文中讲述的也太隐晦了),下面开始训练AlexNet模型.假如回归bounding box的数目K设定为100的话,将有500个参量需要回归,这样AlexNet的输出层节点的数目就要被设置为500(这点文中也没有讲).由于是回归,在CNN后面直接用Softmax可能不行,作者自己定于了目标函数,具体的见原论文.
2.2 CNN分类模型
2.2.1 分类模型的训练集构造
DeepMultiBox在每张图像上回归了K个候选区域,然而这些候选区域到底属于哪一类还不能确定,因此这里需要再训练一个CNN来对这些区域进行分类.
原文中的4.2.1节简短讲述了用于训练CNN分类器的训练样本构造(对于VOC数据集来说的,类别总数目为20):
正样本: 为每个类别构造正样本,如果候选区域和此类的GT boxes之间的Jaccard大于0.5,则此区域被标记成正样本,这样共产生了1千万个正样本,遍布20个类;
负样本: 和正样本构造的方式类似,只是Jaccard要小于0.2才被认定是负样本,这样,总共产生了2千万个负样本;
2.2.2 分类模型的结构
文中貌似没有具体讲述分类模型的结构,只知道用的也是AlexNet,输出层的节点数目肯定改成了21(对于VOC数据集而言),样本集区域的大小是多少不知道!每个样本区域要resize到AlexNet网络输入的指定大小,这点也没看到!
2.3 测试过程
测试的过程在原文的4.2.2节有讲到(假设有N个目标): 给定一张测试图像 --> 裁剪出它的最大正方形区域 --> 将此区域resize到220*220大小 --> 送入DeepMultiBox网络进行回归,得到K个回归boxes以及每个box的置信度分数 --> 利用非最大值抑制的方法将重叠度小于0.5的box去除掉 --> 拥有最高置信度分数的10个区域将被保留 --> 将这些区域送到分类CNN里面进行软分类,输出每个区域的概率值,得到10*(N+1)的概率矩阵 --> 每个区域的置信度分割乘上概率值作为它最终的分数 --> 这些分数用于估计和计算P-R曲线.
(问题3:这个测试的过程我认为最后少了一个对最终分数进行判断的过程,不知道最后是如何确定最终结果的!)
参考文献:
[1]
本文链接:http://task.lmcjl.com/news/5882.html


