之前在学习爬虫的时候遇到了匹配内容时发现存在换行,这时没法匹配了,后来在网上找到了一种方法,当时懒得记录,今天突然有遇到了这种情况,想想还是在这里记录一下吧。
当时爬取的时csdn首页博客,如下图
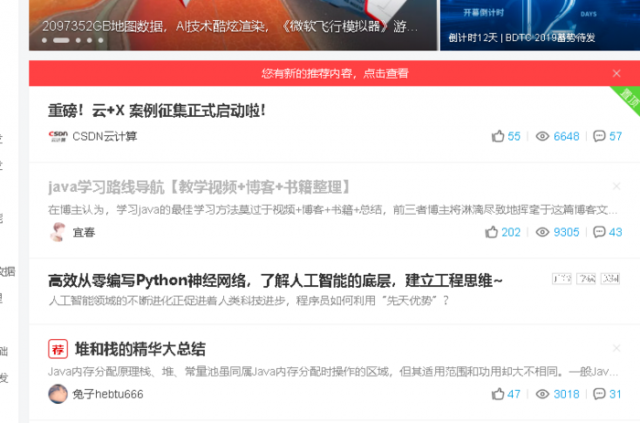
看了源代码,发现如果使用<a href="....来爬取的话,这样得到的会有许多其他的网址,并不全是我需要得博文,但是用<div class="title">去匹配后面的又出现了换行,但是换行匹配我又不会。。。。
re.compile()函数的一个标志参数叫re.DOTALL,它可以让正则表达式中的点(.)匹配包括换行符在内的任意字符。
pat = ' <div class="title">.*?<h2>.*?<a href="(.*?)" target="_blank"' # 此时的.就可以匹配包括换行在内的任意字符 rst1 = re.compile(pat, re.DOTALL).findall(data)

import urllib.request import re
url = "http://www.csdn.net/" data = urllib.request.urlopen(url).read().decode("utf-8") print(len(data)) pat = ' <div class="title">.*?<h2>.*?<a href="(.*?)" target="_blank"' rst1 = re.compile(pat, re.DOTALL).findall(data) print(len(rst1)) for i in range(0, len(rst1)): print(rst1[i]) data = urllib.request.urlopen(rst1[i]).read().decode("utf-8", "ignore") urllib.request.urlretrieve(rst1[i], "D:\\python\\studyPython\\爬虫学习\\学习urllib\\blog\\"+str(i+1)+".html") print("爬取第:", i+1, "篇博客成功") print("首页所有博客爬取结束")
此时则爬取成功
本文链接:http://task.lmcjl.com/news/6557.html


