很久以前看过循环神经网络的相关知识,但一直没有推梯度。这次仔细的看了一遍梯度推导。关于循环神经网络的前向理论,http://blog.csdn.net/juanjuan1314/article/details/52020607 这一篇译文已经有详细的写过了。这里就不赘述了。本文主要记录梯度推导过程,另外补充前向通道之前没有看过的理论。
卷积神经网络的主要思想:稀疏交互、参数共享、等变表示。
而循环神经网络的主要思想:图展开、参数共享。
循环系统展开成有向无环图: 
表达式: 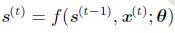
其中f为状态转移函数。
将循环的过程展开成有向无环图的好处是可以更容易的列出表达式,同时,也更容易理解整个过程。
图展开:将输出到隐藏层的训练按照时间步展开成横向传递的计算图,输入的有多少时间步,横向就展开成多少条路径。具体展开过程如下图: 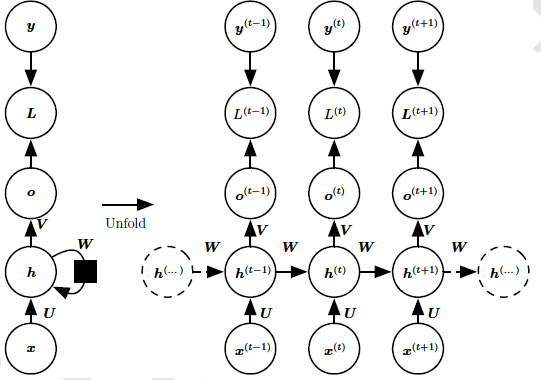
图1. 循环神经网络展开图
在循环神经网络中,横向传递的只有状态,而状态是一个固定长度的向量h。h的表达式可写作: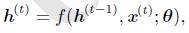
其中,θ是w和b的组合。
根据上图,各节点的公式表示为: 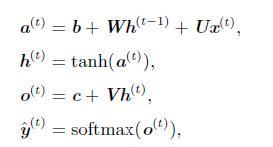
纠结了好久,为什么损失要用对数似然估计来计算呢。后来发现是这样的:
对于像文本这种时间序列数据,每一层的输出通常是通过softmax预测下一个单词,而输出结果通常为词典中各词被预测为下一个词的概率。既然是预测概率,那么就希望真实的目标词被预测的概率尽量大,等同于真实目标词的预测概率的对数尽量大,也就是其负对数尽量小。因此用负对数似然来表示softmax分类的损失函数是很合理的。
上图中,整个网络的损失是所有时间步输出的损失的总和。 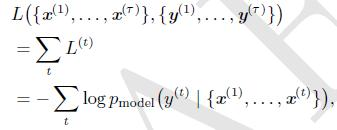
其中,y(t)是每个时间步真是的目标,对于文本来说,多半就是下一个词。
权值共享:每个时间步使用相同的参数。
对于y=g(x), z=f(y)这样的关系,z对x求导可以表示为
如果以上x、y、z均表示矩阵或者张量,那么 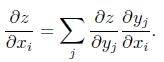
以梯度的方式表示为: 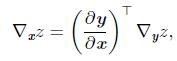
其中, 是g的Jacobian矩阵,而 是z对y的梯度。也就是,z对x的梯度可以换算成g的一阶偏导矩阵的的转置与z对y的梯度的乘积。
再次列出前向计算公式 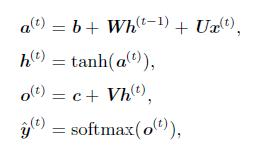
循环神经网咯的反向传播为BPTT,是横向和纵向同时进行的反向传播过程。
根据上一小节的微积分链式法则: 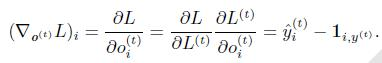
表示最终的损失,即所有输出的负对数似然和。
其中,当时间步为最后一步,h不再往下传播没输出h(t+1),只有o(t),则: 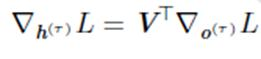
除此之外,其他时间步,每个时间步的输出有两个o(t)和h(t+1),因此,梯度为 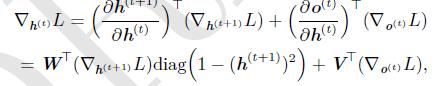
这个式子是由前向传播求导推出来的。
当然,这个式子需要从最后一层往回推倒数第二层,然后反向层层递推。
其中 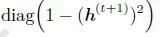 是**函数tanh的一阶偏导矩阵(Jacobian矩阵)。
是**函数tanh的一阶偏导矩阵(Jacobian矩阵)。
再推导各参数的梯度如下: 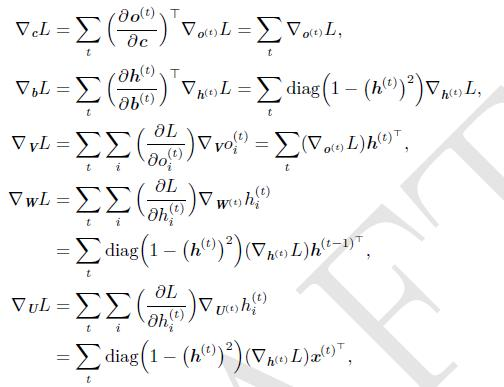
层层递推,就能把每一层的参数的梯度求出来了。
下一篇将分析LSTM在tensorflow中实现的过程。
本文链接:http://task.lmcjl.com/news/722.html


