有一些网站为了避免爬虫的恶意访问,会设置一些反爬虫机制,对方服务器会对爬虫进行屏蔽。常见的饭爬虫机制主要有下面几个:
1. 通过分析用户请求的Headers信息进行反爬虫
2. 通过检测用户行为进行反爬虫,比如通过判断同一个IP在短时间内是否频繁访问对应网站等进行分析
3. 通过动态页面增加爬虫的爬取难度,达到反爬虫的目的
第一种反爬虫机制在目前网站中应用的最多,大部分反爬虫网站会对用户请求的Headers信息的“User-Agent”字段进行检测来判断身份,有时,这类反爬虫的网站还会对“Referer”字段进行检测。我们可以在爬虫中构造这些用户请求的Headers信息,以此将爬虫伪装成浏览器,简单的伪装只需设置好“User-Agent”字段的信息即可,如果要进行高相似度的路蓝旗伪装,则需要将用户请求的Headers信息中常见的字段都在爬虫中设置好
第二种反爬虫机制的网站,可以通过之前学习的使用代理服务器并经常切换代理服务器的方式,一般就能够攻克限制
第三种反爬虫机制的网站,可以利用一些工具软件,比如selenium+phantomJS,就可以攻克限制
在学习高相似度的浏览器伪装技术之前,我们首先要对Headers信息要有一定的了解。我们先打开火狐浏览器,打开淘宝的网站www.taobao.com,利用Fiddler获取头部信息。
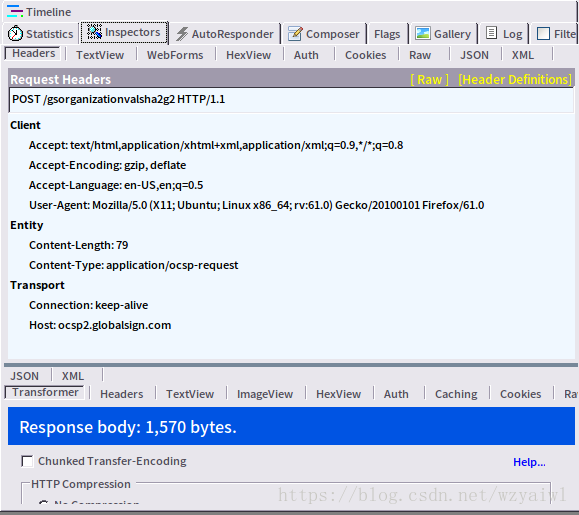
字段的格式,基本格式为:“字段名”:”字段值”,字段名和对应的值之间通过”:”隔开。
字段1: Accept: text/html, application/xhtml+xml, application/xmlq=0.9,*/*;q=08
这一行字段信息表示浏览器可以支持 text/html,application/xml、/等内容类型,支持的优先顺序从左到右依次排列。
字段2: accept-encoding:gzip, deflate
这一行字段信息表示浏览器可以支持gzp、 deflate等压缩编码。
字段3: Accept- Language:en-US,en;q=0.5
所以之一行字段表示浏览器可以支持en-US、cn等语言。除此之外,有些还支持zh-CN(表示简体中文语言。zh表示中文,CN表示简体)。
字段4:User- Agent: Mozilla/5.0( X11;Ubuntu;Linux x86_64 ;rv:61.0) Gecko20100101Firefox/61.0
所以这一行字段表示信息为对应的用户代理信息。
字段5: Connection:keep-alve
所以此时,这一行字段表示客户端与服务器的连接是持久性连接。
字段6:Host: ocsp2.globalsign.com
字段7: Referer:网址
使用代理服务器
import urllib.request
import urllib.parse
import http.cookiejar
url = "http://bbs.chinaunix.net/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=LfgTz"
postdata = urllib.parse.urlencode({ # 此处登录可用自己在网站上注册的用户名和密码
"username": "weisuen",
"password": "aA123456"
}).encode("utf-8")
req = urllib.request.Request(url, postdata)
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36")
# 使用http.cookiejar.CookieJar()创建CookieJar对象
cjar = http.cookiejar.CookieJar()
# 使用HTTPCookieProcessor创建cookie处理器,并以其参数构建opener对象
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
# 将opener安装为全局
urllib.request.install_opener(opener)
file = opener.open(req)
data = file.read()
file = open('/home/wk/csdn.html','wb')
file.write(data)
file.close()
url2 = "http://bbs.chinaunix.net/" # 设置要爬取的该网站下其他网页地址
data2 = urllib.request.urlopen(url2).read()
fhandle = open('/home/wk/csdn1.html','wb')
fhandle.write(data2)
fhandle.close()
本文链接:http://task.lmcjl.com/news/6549.html


