有兴趣阅读GAN鼻祖之作的给出链接: 2014年NIPS Generative Adversarial Net
GAN核心思想:生成器G与判别器D,双方博弈。
扯完皮了,下面看一下怎么样训练模型。
生成模型与对抗模型可以说是完全独立的两个模型,好比就是完全独立的两个神经网络模型,他们之间没有什么联系。那么训练这样的两个模型的大方法就是:单独交替迭代训练。
下图给出模型示意,红线以上是判别模型,红线以下是生成模型+判别模型。
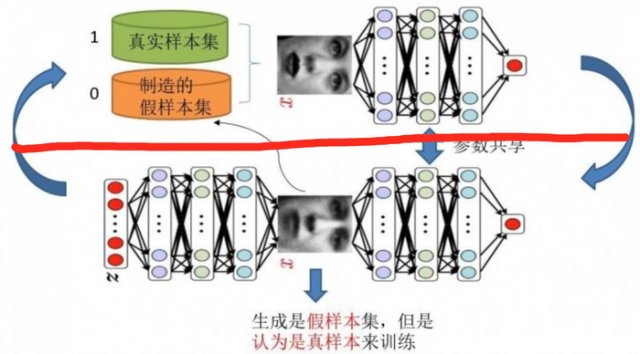
第一步:(训练判别模型)
初始化生成模型,输入一堆随机数组,得到一堆假的样本集,而真样本集默认给定。制定标签:真样本集所有的类标签都为1,而假样本集的所有类标签都为0。单就判别网络来说,此时问题就变成了一个再简单不过的有监督的二分类问题了,直接送到神经网络模型中训练就完事了。这样我们就得到了具备一定判别能力的判别模型。
第二步:(训练生成模型)
生成网络的训练其实是对生成-判别网络串接的训练,就像上图中显示的那样。输入噪声数组Z,通过生成模型生成了假样本,此时很关键的一点来了,既然我们已经有了初具判断能力的判别模型,我们固定判别模型参数,将这些假样本的标签都设置为1,使得生成模型向着真样本分布去拟合。
好了,重新顺一下思路,现在对于生成网络的训练,我们有了样本集(只有假样本集,没有真样本集),有了对应的label(全为1),是不是就可以训练了?有人会问,这样只有一类样本,训练啥呀?谁说一类样本就不能训练了?只要有误差就行。还有人说,你这样一训练,判别网络的网络参数不是也跟着变吗?没错,这很关键,所以在训练这个串接的网络的时候,一个很重要的操作就是不要判别网络的参数发生变化,也就是不让它参数发生更新,只是把误差一直传,传到生成网络那块后更新生成网络的参数。这样就完成了生成网络的训练了。
重复上述两步:
完成第二步后,可以根据目前新的生成网络再对先前的那些噪声Z生成新的假样本,并且训练后的假样本应该是更真了才对。这样又可以重复上述过程了。我们把这个过程称作为单独交替训练。我们可以实现定义一个迭代次数,交替迭代到一定次数后停止即可。这个时候我们再去看一看噪声Z生成的假样本会发现,原来它已经很真了。
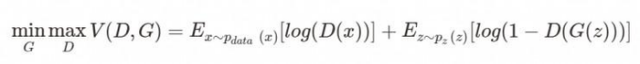
max过程固定G生成模型优化D判别模型,min过程反之。
GAN强大之处在于可以自动的学习原始真实样本集的数据分布(生成模型);
GAN强大之处在于可以自动的定义潜在损失函数。(判别模型)
本文链接:http://task.lmcjl.com/news/12085.html


