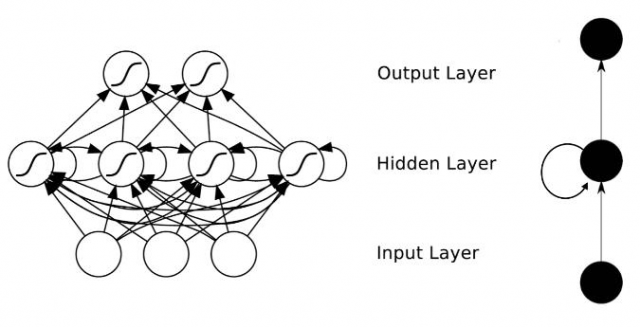
传统的神经网络是层与层之间是全连接的,但是每层之间的神经元是没有连接的(其实是假设各个数据之间是独立的)。这种结构不善于处理序列化的问题。比如要预测句子中的下一个单词是什么,这往往与前面的单词有很大的关联,因为句子里面的单词并不是独立的。
RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
RNN的主要应用领域有哪些呢?
① 自然语言处理(NLP): 主要有视频处理, 文本生成, 语言模型, 图像处理
② 机器翻译, 机器写小说
③ 语音识别
④ 图像描述生成
⑤ 文本相似度计算
⑥ 音乐推荐、网易考拉商品推荐、Youtube视频推荐等新的应用领域
RNN结构,如图 :
Hidden Layer的层级展开图:
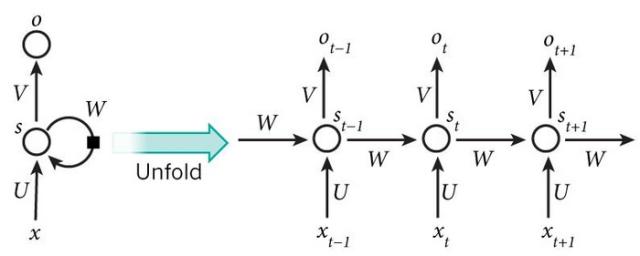
(1)如上循环的结构图,
inputs units):t 隐层单元的输出为:f就是激励函数,一般是sigmoid,tanh, relu等(3)时间 t 的输出为:
RNNs中,每输入一步,每一层都共享参数U,V,W,(因为是将循环的部分展开,天然应该相等) RNNs的关键之处在于隐藏层,隐藏层能够捕捉序列的信息。
由于每一步的输出不仅仅依赖当前步的网络,并且还需要前若干步网络的状态,那么这种BP改版的算法叫做Backpropagation Through Time(BPTT) , 也就是将输出端的误差值反向传递,运用梯度下降法进行更新
以下图为例:
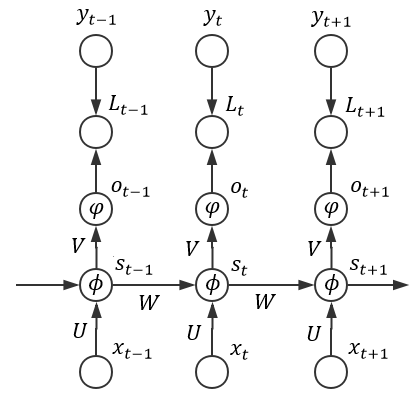
(1)接受完序列中所有样本后再统一计算损失,此时模型的总损失可以表示为(假设输入序列长度为n):
(2)
其中:
令:…(1)(没有经过激励函数和变换函数前)
则:,
(3)矩阵V的更新
对矩阵 V 的更新过程,根据(1)式可得, (和传统的神经网络一致,根据求导的链式法则):
因为:,所以对矩阵V的更新对应的导数:
(4)矩阵U和W的更新
RNN 的 BP 算法的主要难点在于它 State 之间的通信
可以采用循环的方法来计算各个梯度,t应从n开始降序循环至 1
计算时间通道上的局部梯度(同样根据链式法则)
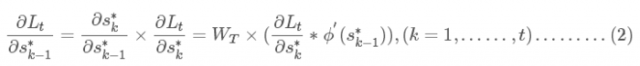
利用局部梯度计算U和W的梯度,这里累加是因为权值是共享的,所以往前推算一直用的是一样的权值:
(5)训练过程中的问题
W更新需要计算,即经过激励函数的导数。如果时间维度上很长,则这个梯度是累积的,所以造成梯度消失或爆炸
RNN 主要的作用就是能够记住之前的信息,但是梯度消失的问题又告诉我们不能记住太久之前的信息,改进的思路有两点:state的传递方式,比如就是下面提及的LSTM。关于为何 LSTMs 能够解决梯度消失,直观上来说就是上方时间通道是简单的线性组合。
本文链接:http://task.lmcjl.com/news/12454.html


