1.1. 相同的表的自连接和不同表间的普通连接并没有什么区别,自连接里的“自”这个词也没有太大的意义
1.2. 与多表之间进行的普通连接相比,自连接的性能开销更大
1.2.1. 特别是与非等值连接结合使用的时候
1.2.2. 用于自连接的列推荐使用主键或者在相关列上建立索引
2.1. 有顺序的有序对(ordered pair)
2.2. 无顺序的无序对(unordered pair)
3.1.
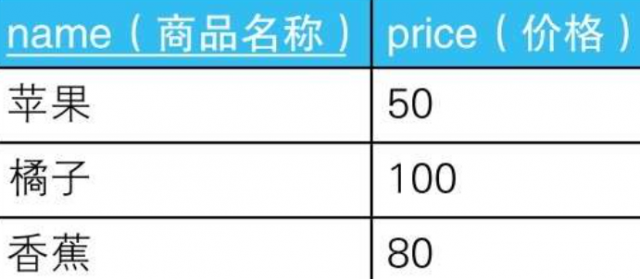
3.2. --用于获取可重排列的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2;
3.3. --用于获取排列的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name <> P2.name;
3.4. --用于获取组合的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name > P2.name;
3.5. --用于获取组合的SQL语句:扩展成3列
SELECT P1.name AS name_1, P2.name AS name_2, P3.name AS name_3
FROM Products P1, Products P2, Products P3
WHERE P1.name > P2.name
AND P2.name > P3.name;
3.6. ">”和“<”等比较运算符不仅可以用于比较数值大小,也可以用于比较字符串(比如按字典序进行比较)或者日期
4.1. 示例
4.1.1. --用于删除重复行的SQL语句(1):使用极值函数
DELETE FROM Products P1
WHERE rowid < ( SELECT MAX(P2.rowid)
FROM Products P2
WHERE P1.name = P2. name
AND P1.price = P2.price ) ;
4.1.2. --用于删除重复行的SQL语句(2):使用非等值连接
DELETE FROM Products P1
WHERE EXISTS ( SELECT *
FROM Products P2
WHERE P1.name = P2.name
AND P1.price = P2.price
AND P1.rowid < P2.rowid );
4.2. 如果从物理表的层面来理解SQL语句,抽象度是非常低的
4.3. “表”“视图”这样的名称只反映了不同的存储方法,而存储方法并不会影响到SQL语句的执行和结果
4.4. 无论表还是视图,本质上都是集合——集合是SQL能处理的唯一的数据结构
5.1. 示例
5.1.1. --用于查找是同一家人但住址却不同的记录的SQL语句
SELECT DISTINCT A1.name, A1.address
FROM Addresses A1, Addresses A2
WHERE A1.family_id = A2.family_id
AND A1.address <> A2.address ;
5.1.2. --用于查找价格相等但商品名称不同的记录的SQL语句
SELECT DISTINCT P1.name, P1.price
FROM Products P1, Products P2
WHERE P1.price = P2.price
AND P1.name <> P2.name;
5.1.3. 如果改用关联子查询,就不需要DISTINCT了
6.1. 示例
6.1.1. --排序:使用窗口函数
SELECT name, price,
RANK() OVER (ORDER BY price DESC) AS rank_1,
DENSE_RANK() OVER (ORDER BY price DESC) AS rank_2
FROM Products;
6.1.1.1. 在出现相同位次后,rank_1跳过了之后的位次,rank_2没有跳过,而是连续排序
6.1.1.2. 依赖于具体数据库来实现的方法
6.1.2. --排序从1开始。如果已出现相同位次,则跳过之后的位次
SELECT P1.name,
P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price > P1.price) + 1 AS rank_1
FROM Products P1
ORDER BY rank_1;
6.1.2.1. 不依赖于具体数据库来实现的方法
6.1.2.2. 去掉标量子查询后边的+1,就可以从0开始给商品排序
6.1.2.3. 如果修改成COUNT(DISTINCT P2.price),那么存在相同位次的记录时,就可以不跳过之后的位次,而是连续输出(相当于DENSE_RANK函数)
7.1. 示例
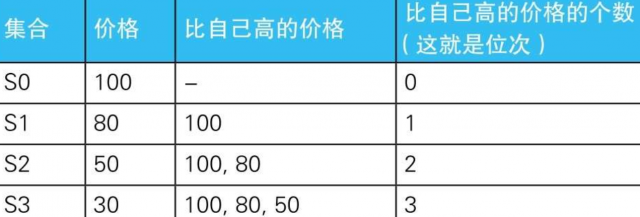
7.1.2. --排序:使用自连接
SELECT P1.name,
MAX(P1.price) AS price,
COUNT(P2.name) +1 AS rank_1
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price
GROUP BY P1.name
ORDER BY rank_1;
7.1.3. --排序:改为内连接
SELECT P1.name,
MAX(P1.price) AS price,
COUNT(P2.name) +1 AS rank_1
FROM Products P1 INNER JOIN Products P2
ON P1.price < P2.price
GROUP BY P1.name
ORDER BY rank_1;
7.1.4. --不聚合,查看集合的包含关系
SELECT P1.name, P2.name
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price;
原文链接:https://www.cnblogs.com/lying7/p/17270513.html
本文链接:http://task.lmcjl.com/news/17763.html


