打印损失:
迭代变化:可看到图像逐渐变得清晰。

import tensorflow as tf
import numpy as np
import pickle
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('./data/')
img = mnist.train.images[50]
def get_inputs(real_size, noise_size):
"""
真实图像tensor与噪声图像tensor
"""
real_img = tf.placeholder(tf.float32, [None, real_size], name='real_img')
noise_img = tf.placeholder(tf.float32, [None, noise_size], name='noise_img')
return real_img, noise_img
def get_generator(noise_img, n_units, out_dim, reuse=False, alpha=0.01):
"""
生成器
noise_img: 生成器的输入
n_units: 隐层单元个数
out_dim: 生成器输出tensor的size,这里应该为32*32=784
alpha: leaky ReLU系数
"""
with tf.variable_scope("generator", reuse=reuse):
# hidden layer
hidden1 = tf.layers.dense(noise_img, n_units)
# leaky ReLU
hidden1 = tf.maximum(alpha * hidden1, hidden1)
# dropout
hidden1 = tf.layers.dropout(hidden1, rate=0.2)
# logits & outputs
logits = tf.layers.dense(hidden1, out_dim)
outputs = tf.tanh(logits)
return logits, outputs
def get_discriminator(img, n_units, reuse=False, alpha=0.01):
"""
判别器
n_units: 隐层结点数量
alpha: Leaky ReLU系数
"""
with tf.variable_scope("discriminator", reuse=reuse):
# hidden layer
hidden1 = tf.layers.dense(img, n_units)
hidden1 = tf.maximum(alpha * hidden1, hidden1)
# logits & outputs
logits = tf.layers.dense(hidden1, 1)
outputs = tf.sigmoid(logits)
return logits, outputs
# 定义参数
# 真实图像的size
img_size = mnist.train.images[0].shape[0]
# 传入给generator的噪声size
noise_size = 100
# 生成器隐层参数
g_units = 128
# 判别器隐层参数
d_units = 128
# leaky ReLU的参数
alpha = 0.01
# learning_rate
learning_rate = 0.001
# label smoothing
smooth = 0.1
tf.reset_default_graph()
real_img, noise_img = get_inputs(img_size, noise_size)
# generator
g_logits, g_outputs = get_generator(noise_img, g_units, img_size)
# discriminator
d_logits_real, d_outputs_real = get_discriminator(real_img, d_units)
d_logits_fake, d_outputs_fake = get_discriminator(g_outputs, d_units, reuse=True)
# discriminator的loss
# 识别真实图片
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,
labels=tf.ones_like(d_logits_real)) * (1 - smooth))
# 识别生成的图片
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.zeros_like(d_logits_fake)))
# 总体loss
d_loss = tf.add(d_loss_real, d_loss_fake)
# generator的loss
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_logits_fake)) * (1 - smooth))
train_vars = tf.trainable_variables()
# generator中的tensor
g_vars = [var for var in train_vars if var.name.startswith("generator")]
# discriminator中的tensor
d_vars = [var for var in train_vars if var.name.startswith("discriminator")]
# optimizer
d_train_opt = tf.train.AdamOptimizer(learning_rate).minimize(d_loss, var_list=d_vars)
g_train_opt = tf.train.AdamOptimizer(learning_rate).minimize(g_loss, var_list=g_vars)
#训练
# batch_size
batch_size = 64
# 训练迭代轮数
epochs = 300
# 抽取样本数
n_sample = 25
# 存储测试样例
samples = []
# 存储loss
losses = []
# 保存生成器变量
saver = tf.train.Saver(var_list = g_vars)
# 开始训练
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for batch_i in range(mnist.train.num_examples//batch_size):
batch = mnist.train.next_batch(batch_size)
batch_images = batch[0].reshape((batch_size, 784))
# 对图像像素进行scale,这是因为tanh输出的结果介于(-1,1),real和fake图片共享discriminator的参数
batch_images = batch_images*2 - 1
# generator的输入噪声
batch_noise = np.random.uniform(-1, 1, size=(batch_size, noise_size))
# Run optimizers
_ = sess.run(d_train_opt, feed_dict={real_img: batch_images, noise_img: batch_noise})
_ = sess.run(g_train_opt, feed_dict={noise_img: batch_noise})
# 每一轮结束计算loss
train_loss_d = sess.run(d_loss,
feed_dict = {real_img: batch_images,
noise_img: batch_noise})
# real img loss
train_loss_d_real = sess.run(d_loss_real,
feed_dict = {real_img: batch_images,
noise_img: batch_noise})
# fake img loss
train_loss_d_fake = sess.run(d_loss_fake,
feed_dict = {real_img: batch_images,
noise_img: batch_noise})
# generator loss
train_loss_g = sess.run(g_loss,
feed_dict = {noise_img: batch_noise})
print("Epoch {}/{}...".format(e+1, epochs),
"Discriminator Loss: {:.4f}(Real: {:.4f} + Fake: {:.4f})...".format(train_loss_d, train_loss_d_real, train_loss_d_fake),
"Generator Loss: {:.4f}".format(train_loss_g))
# 记录各类loss值
losses.append((train_loss_d, train_loss_d_real, train_loss_d_fake, train_loss_g))
# 抽取样本后期进行观察
sample_noise = np.random.uniform(-1, 1, size=(n_sample, noise_size))
gen_samples = sess.run(get_generator(noise_img, g_units, img_size, reuse=True),
feed_dict={noise_img: sample_noise})
samples.append(gen_samples)
# 存储checkpoints
saver.save(sess, './checkpoints/generator.ckpt')
# 将sample的生成数据记录下来
with open('train_samples.pkl', 'wb') as f:
pickle.dump(samples, f)
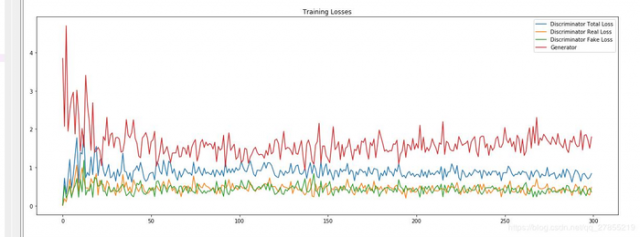
# 绘制loss曲线
fig, ax = plt.subplots(figsize=(20,7))
losses = np.array(losses)
plt.plot(losses.T[0], label='Discriminator Total Loss')
plt.plot(losses.T[1], label='Discriminator Real Loss')
plt.plot(losses.T[2], label='Discriminator Fake Loss')
plt.plot(losses.T[3], label='Generator')
plt.title("Training Losses")
plt.legend()
with open('train_samples.pkl', 'rb') as f:
samples = pickle.load(f)
# 指定要查看的轮次
epoch_idx = [0, 5, 10, 20, 40, 60, 80, 100, 150, 250] # 一共300轮,不要越界
show_imgs = []
for i in epoch_idx:
show_imgs.append(samples[i][1])
# 指定图片形状
rows, cols = 10, 25
fig, axes = plt.subplots(figsize=(30,12), nrows=rows, ncols=cols, sharex=True, sharey=True)
idx = range(0, epochs, int(epochs/rows))
for sample, ax_row in zip(show_imgs, axes):
for img, ax in zip(sample[::int(len(sample)/cols)], ax_row):
ax.imshow(img.reshape((28,28)), cmap='Greys_r')
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
本文链接:http://task.lmcjl.com/news/5702.html


