首先声明下,这个爬虫采用的框架来自慕课网的一段视频教程http://www.imooc.com/view/563,原来的爬虫是爬取1000个跟python相关的百度百科页面的标题和摘要。经过改造,本文的爬虫是爬取100个人体艺术页面,下载每个页面上的艺术图片,并汇总每个页面及页面上所有艺术图片的链接地址。
该爬虫分为主控程序(spider_mian)、url管理器(url_manager)、html下载器(html_downloader)、html解析器(html_parser)和数据搜集器(html_outputer)5个py文件构成。
主控程序从入口URL开始爬取,调用html下载器下载需要爬取的页面的源码,然后调用html解析器解析页面源码,获取新的URL来充实url管理器,同时获取新的数据交给数据搜集器供其下载和汇总。
废话不多说,直接上源码,首先是主控程序(spider_mian.py),亮点是那个入口URL,低调,那是艺术。
#coding=utf-8 import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, root_url): self.urls.add_new_url(root_url) count = 1 while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print "craw %d : %s" %(count,new_url) html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url,html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 100: break count = count + 1 except: print "craw failed" self.outputer.output_html() if __name__=="__main__": root_url = "http://www.1000rtrt.com/" obj_spider = SpiderMain() obj_spider.craw(root_url)
接下来是url管理器(url_manager.py):
#coding=utf-8 class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: self.add_new_url(url) def has_new_url(self): return len(self.new_urls) != 0 def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url
以上两段程序基本与慕课网讲的源代码一致,感觉无可挑剔,所以没啥可改的。接下来是html下载器(html_downloader.py),在原课程代码基础上加入了user_agent,伪装成浏览器,以便更顺利地访问网站。
#coding=utf-8 import urllib2
class HtmlDownloader(object):
def download(self,url): if url is None: return None user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } request = urllib2.Request(url,headers = headers) response = urllib2.urlopen(request) if response.getcode() != 200: return None return response.read()
接下来是html解析器(html_parser.py),要想针对具体应用做相应的爬虫,这里是重点需要改的地方,在本文的爬虫中,我们想要把每个页面中的需要下载的照片的链接地址找到。直接上代码:
#coding=utf-8 from bs4 import BeautifulSoup import re import urlparse import urllib2 class HtmlParser(object): def _get_new_urls(self, page_url, soup): new_urls = set() links = soup.find_all('a', href=re.compile(r"News/\d+/\d+\.htm")) for link in links: new_url = link['href'] new_full_url = urlparse.urljoin(page_url,new_url) new_urls.add(new_full_url) return new_urls def _get_new_data(self, page_url, soup): res_data = {} res_data['url'] = page_url res_data['pic'] = [] nodes = soup.find_all('img') for node in nodes: if node.attrs.has_key('src'): src = node.get('src') if src[0:4]=='http': res_data['pic'].append(src) return res_data def parse(self, page_url, html_cont): if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8') new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) return new_urls,new_data
最后就是数据收集器(html_outputer.py)啦,采用边爬取边下载的步骤,所以将下载图片放在collect_data函数中。
#coding=utf-8 import urllib import os class HtmlOutputer(object): def __init__(self): self.datas = [] def collect_data(self,data): if data is None: return self.datas.append(data) path = data['url'].replace(r'/','').replace(':','') os.mkdir(path) x=0 for pic in data['pic']: urllib.urlretrieve(pic,os.path.join(path,'%s.jpg'%x)) x+=1 def output_html(self): fout = open('output.txt','w') for data in self.datas: fout.write("%s\n" %data['url']) for pic in data['pic']: fout.write("%s\n"%pic)
编写完成,可以运行啦。运行主控程序spider_mian.py:
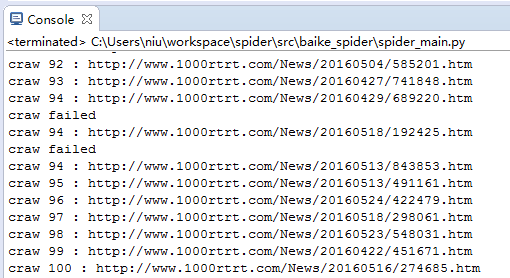
有的页面爬取失败,是因为个别图片没下载下来导致的。
爬取并下载100个页面的所有图片还是需要点时间的,耐心等待,或者把100改成更小的数目。
成果:
文件夹里面的东西就不在这里展示了,少儿不宜。
本文链接:http://task.lmcjl.com/news/6775.html


